
In the intricate dance of human conversation, timing is everything. The subtle pauses, the rapid-fire back-and-forth, the seamless turn-taking, these are the invisible threads that weave a dialogue together, making it feel natural and engaging. When we interact with a modern voice bot solution, our brains, honed by a lifetime of conversation, instinctively expect this same rhythmic flow.
When there is a long, awkward silence after we speak, the illusion of intelligence shatters. That silence, known as latency, is the single greatest enemy of a successful voice AI interaction. It is the silent killer of user experience, and for developers building the next generation of conversational AI, the relentless pursuit of its reduction is the most critical mission.
The future of voice AI is not just about building a bot that can provide the right answer; it is about building one that can provide the right answer at the right time. For a real-time AI calling performance to be effective, it must be imperceptibly fast. This is why the architectural choices of the underlying voice platform are paramount.
A low latency voicebot is not a feature; it is the direct result of a deep, architectural commitment to speed. This guide will explore the profound impact of latency on the conversational experience and the essential, modern infrastructure required to conquer it.
Table of contents
What is Latency and Why is it the Enemy of Conversation?
Latency, in the context of a voice call, is the total delay from the moment a sound is made by a speaker to the moment that sound is heard by a listener. In a human conversation, this is governed by the speed of sound. In an AI-powered voice conversation, it is governed by the speed of light and the speed of computation.
The Natural Rhythm of Human Conversation
The natural rhythm of human dialogue is incredibly fast. Our brains are hard-wired to this rapid pace. When this gap is extended, we perceive the other person as hesitant, distracted, or having difficulty understanding.
How Latency Kills the AI Experience
When a voicebot’s response is slow, it triggers all of these negative perceptions in the user’s mind.
- It Feels Unintelligent: A long pause makes the AI feel “stupid,” as if it is struggling to process a simple request. Speed is often perceived as intelligence.
- It Creates Frustration: The user is left in a state of uncertainty. Did the bot hear me? Is it broken? This dead air is a massive source of user frustration and a primary reason for call abandonment.
- It Causes Conversational Chaos: The most destructive effect is that it breaks the natural turn-taking of the conversation. The user, assuming the bot is not going to respond, will often start speaking again just as the bot’s delayed response finally starts to play. This results in a chaotic mess of both parties talking over each other, completely derailing the interaction.
Also Read: How Can Building Voice Bots Improve Customer Experience Across Channels?
What is the “Anatomy of Latency” in an AI Voice Call?
The total latency, or the “end-to-end” delay, in an AI voice call is not a single problem; it is a cumulative effect of a series of distinct processing and network “hops.” To build a low latency voicebot, you must optimize every single link in this chain.
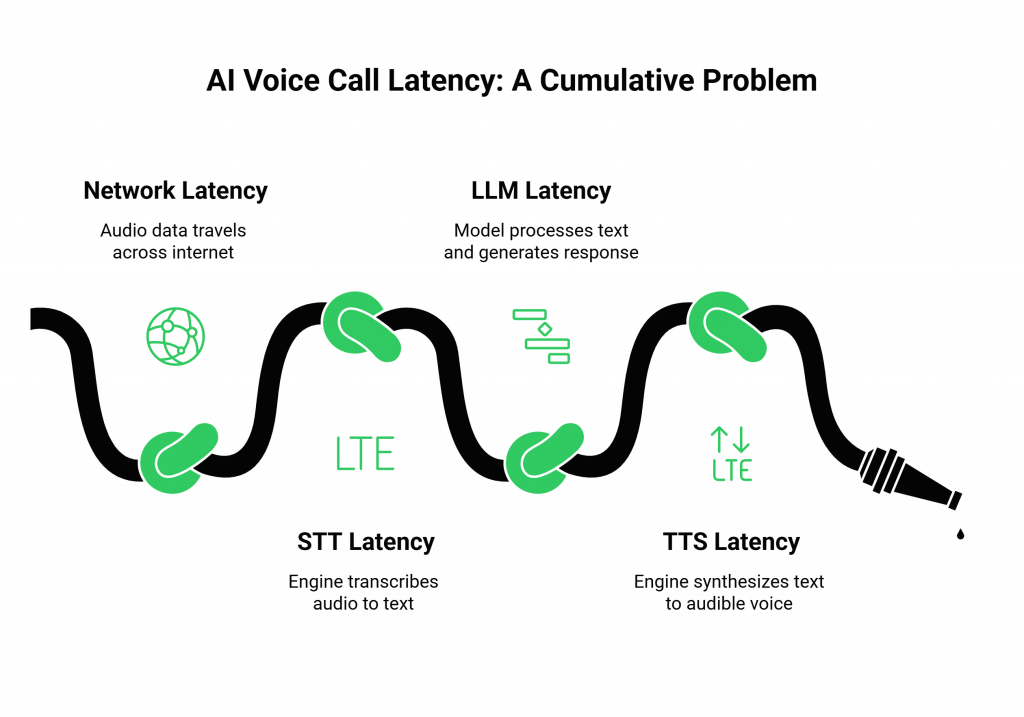
- Network Latency (The Journey): This is the time it takes for the audio data packets to travel from the user’s phone, across the internet to the voice platform’s servers, and for the AI’s response to make the journey back. This is largely a function of physical distance.
- STT Latency (The Ears): This is the time it takes for the Speech-to-Text (STT) engine to receive the audio stream and transcribe it into written text.
- LLM Latency (The Brain): This is the time it takes for the Large Language Model (LLM) to process the text, understand the user’s intent, decide on a course of action, and generate a text-based response. This is often the largest and most variable component of the AI’s “thinking time.”
- TTS Latency (The Mouth): This is the time it takes for the Text-to-Speech (TTS) engine to synthesize the text response back into an audible, human-like voice.
The total “glass-to-glass” latency is the sum of all of these individual delays. If each step takes just 200 milliseconds, the total round-trip time is already approaching a full second, which is far too long for a natural conversation.
Also Read: How Should QA Teams Evaluate Interactions While Building Voice Bots For Users?
How Do Modern Voice Platforms Architect for Low Latency?
While the developer is responsible for choosing fast AI models, the voice infrastructure provider is responsible for minimizing the largest and most critical variable: network latency. This is where the architectural philosophy of the platform becomes the key differentiator.
The Architectural Solution: A Globally Distributed, Edge-Native Network
This is the single most important strategy for defeating latency.
- The Problem with a Centralized Cloud: If a voice platform is hosted in a single data center in one part of the world, every global user is penalized. A call from Europe to a server in the US has to cross the Atlantic Ocean twice, adding hundreds of milliseconds of unavoidable delay.
- The Edge-Native Solution: A modern voice platform, like FreJun AI’s Teler engine, is built on a globally distributed network of Points of Presence (PoPs). These are smaller, powerful media servers located in data centers all over the world.
The Software Solution: Optimizing the Real-Time Pipeline
Beyond the physical architecture, a low latency voicebot platform uses sophisticated software techniques to shave off every possible millisecond.
- Streaming Everything: The platform does not wait for the user to finish their entire sentence before it starts working. It uses a streaming architecture. The audio is streamed to the STT engine in real-time as it is being spoken. Similarly, the TTS engine can start streaming the AI’s audio response back to the platform before it has even finished generating the full sentence.
- A High-Performance Media Engine: The core software that handles the audio packets (the voice streaming engine) is a highly specialize, low-level application that is obsessively optimize for speed and efficiency.
Ready to build your voicebot on an infrastructure that is obsessively engineered for speed? Sign up for FreJun AI and experience our ultra-low-latency platform.
What Are the Tangible Business Consequences of High Latency?
The decision to build on a high-latency platform is not just a technical compromise; it is a direct and measurable drag on your business outcomes. The real-time AI calling performance has a real impact on your bottom line. This table clearly illustrates the business consequences of latency.
| Business Metric | The Impact of a High-Latency Voicebot | The Benefit of a Low-Latency Voicebot |
| Customer Satisfaction (CSAT) | Plummets. The experience is frustrating, and the bot is perceived as unintelligent. | Increases. The experience is natural and efficient, and the bot is perceived as smart and helpful. |
| Call Containment Rate | Low. Frustrated users will quickly “zero out” or hang up to try and reach a human. | High. Users are more likely to complete their task with a responsive bot, reducing the load on human agents. |
| Task Completion Rate | Low. Conversational chaos caused by delays and interruptions leads to failed workflows. | High. The smooth, natural flow of the conversation allows the user and the AI to work together to complete the task. |
| Brand Perception | Your brand is perceived as outdated, clunky, and disrespectful of the customer’s time. | Your brand is perceived as modern, innovative, and customer-centric. |
Also Read: How Can Small Teams Start Building Voice Bots With Minimal Cost?
Conclusion
In the new era of conversational AI, latency is the new “loading” screen. It is the silent, frustrating delay that stands between your customer and the resolution they are seeking. For modern voice bot solutions, minimizing this latency is not a feature; it is the entire game.
The future of voice AI will be define by the quality of the conversational experience, and that experience is make on a foundation of speed. By choosing a voice infrastructure provider that has made a deep, architectural commitment to a globally distributed, edge-native, and obsessively optimized platform, you are not just buying a service.
You are acquiring the essential, high-performance nervous system that will allow your intelligent AI to finally speak at the speed of thought.
Want to do a deep dive into our global edge network and see a live demonstration of our low-latency performance? Schedule a demo with our team at FreJun Teler.
Also Read: 10 Best IVR Software Solutions for 2025: Features, Pricing & Use Cases
Frequently Asked Questions (FAQs)
Latency is the delay between when a user stops speaking and when they hear the AI’s response. It is the “pause” in the conversation.
Low latency is critical because it makes the conversation feel natural and responsive. High latency makes the voicebot feel slow, unintelligent, and frustrating to use.
A low-latency voicebot uses a globally distributed, edge-native voice infrastructure architected to minimize delay.
The biggest cause is network latency, which is the time it takes for data to physically travel across the internet. This is directly related to distance.
It improves real-time AI calling performance by processing the call’s audio at a server that is physically close to the end-user, dramatically reducing the data’s travel time.
The main components are network latency, Speech-to-Text (STT) processing time, Large Language Model (LLM) processing time, and Text-to-Speech (TTS) processing time.
It is a challenge. While the infrastructure can be very fast, the “thinking time” of the LLM is a major factor. This is why a hybrid AI architecture is often used.