
In the early days of building voice bots, the process was often a monolithic affair. A single, self-contained application was responsible for everything: managing the phone call, transcribing the audio, processing the logic, and synthesizing the response. This approach is fine for a simple prototype or a small-scale pilot.
But the moment you need to handle ten thousand simultaneous calls during a Black Friday sale or a global service outage, this monolithic architecture will buckle and collapse under the strain. Building a voice bot that can operate at a truly massive scale is not just about writing more efficient code; it is about adopting a fundamentally different architectural philosophy.
The same principles that power the world’s most scalable and resilient web applications, decoupling, distribution, and statelessness must also guide voice systems. The future of voice AI belongs to distributed voice bot architectures designed from the ground up for resilience, flexibility, and horizontal scaling for AI calls.
This guide will explore the essential architectural patterns that are defining the next generation of large-scale, production-grade voice AI.
Table of contents
- The Problem: Why Monolithic Voice Architectures Fail at Scale
- The Solution: A Decoupled, Distributed, Microservices-Based Architecture
- How Do These Layers Interact in a Real-World Workflow?
- What Are the Best Practices for a Multi-Region Voice Bot Deployment?
- Conclusion
- Frequently Asked Questions (FAQs)
The Problem: Why Monolithic Voice Architectures Fail at Scale
A monolithic voice bot architecture, where a single application server handles both the telephony and the AI logic, has several critical points of failure that make it completely unsuitable for large-scale deployments. The core issues are:
- The Scalability Bottleneck: The most resource-intensive parts of the process are often the AI models (especially the LLM). In a monolith, if your AI processing slows down, your entire application slows down, including its ability to handle new calls. You cannot scale the telephony component of the AI component
- The Single Point of Failure: If your single application server crashes, your entire voice service goes down. There is no redundancy.
- The Geographic Latency Problem: A single server in a single data center (e.g., in Virginia, USA) creates a terrible experience for users on the other side of the world (e.g., in Australia). The physical distance the audio data must travel creates hundreds of milliseconds of latency, making the conversation feel unnatural and laggy.
- The Lack of Flexibility: A monolithic architecture is often tied to a specific set of technologies. Swapping out one STT provider for another or upgrading your LLM can become a complex and risky refactoring project.
Also Read: The Role of Voice Calling SDKs in the Future of Voice AI and LLMs
The Solution: A Decoupled, Distributed, Microservices-Based Architecture
The solution to the problem of scale is to break the monolith apart. A modern, scalable architecture for building voice bots follows the principle of decoupling, with separate specialized services handling each distinct function. This approach defines the essence of microservices for voice AI.
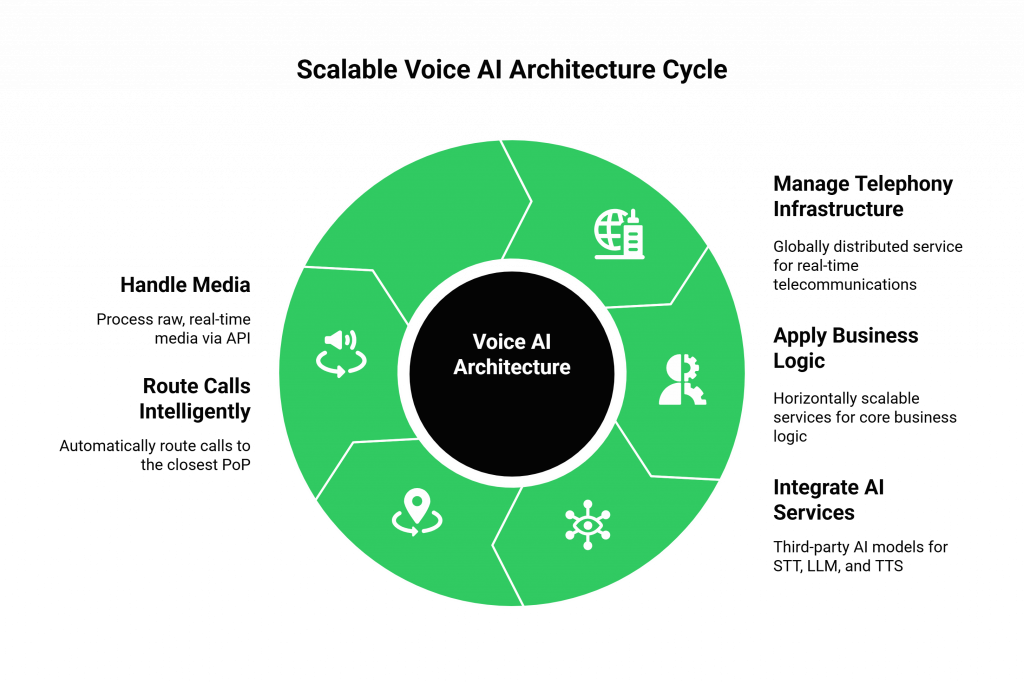
At its highest level, this architecture can be broken down into three distinct, independent layers:
- The Voice Infrastructure Layer (The “Voice”): This is a globally distributed, highly available service that is an expert in one thing: real-time telecommunications. Its job is to manage the scalable telephony infrastructure.
- The Application Logic Layer (The “Brain”): This is a horizontally scalable set of stateless services that contains your core business logic and conversational intelligence.
- The AI Services Layer (The “Senses”): These are the third-party AI models your STT, LLM, and TTS, which are themselves highly scalable, independent services.
How Does FreJun AI Provides the Scalable Telephony Infrastructure?
This is the foundational layer, and it is the part you should not have to build yourself. A provider like FreJun AI gives you this layer as a fully managed service. Our Teler engine is a perfect example of a globally distributed, scalable telephony infrastructure.
- Globally Distributed Edge PoPs: Teler is not a single server. It is a network of Points of Presence (PoPs) in data centers around the world.
- Intelligent Routing: When a call comes in, it is automatically routed to the PoP that is physically closest to the end-user.
- Decoupled Media Handling: Teler’s job is to handle the raw, real-time media and provide it to your application via a Real-Time Media API. It does not know or care about your AI’s logic; it is a pure, high-performance voice engine.
Ready to build your voice bot on a foundation that was designed for global scale? Sign up for FreJun AI and explore our distributed voice infrastructure.
How Do These Layers Interact in a Real-World Workflow?

The magic of this architecture is in how the independent layers communicate in a seamless, high-speed, event-driven workflow. Let’s trace a single conversational turn in a multi-region voice bot deployment.
- The Connection (Voice Layer): A user in London calls your application. The call is instantly routed to and answered by the FreJun AI Teler PoP in our London data center. Teler sends a webhook to your Application Logic Layer.
- The Orchestration (Application Layer): Your Application Logic Layer, which could be a set of serverless functions or containers running in a European AWS region, receives the webhook. It responds with an API command telling the London Teler PoP to greet the user and start listening.
- The “Hearing” (Voice Layer -> AI Services Layer): Teler streams the user’s speech in real time from the London PoP directly to your chosen STT provider’s nearest endpoint. The STT service transcribes the audio into text.
- The “Thinking” (AI Services Layer -> Application Layer): The STT provider sends the transcribed text back to your Application Logic Layer. Your application sends this text to your chosen LLM provider. The LLM processes the text and returns a response.
- The “Speaking” (Application Layer -> AI Services Layer -> Voice Layer): Your Application Logic Layer sends the LLM’s text response to your chosen TTS provider. The TTS provider synthesizes this into an audio stream. Your application then sends a final API command to the London Teler PoP, telling it to play this new audio stream back to the user.
This entire, multi-step, multi-service round trip is designed for horizontal scaling for ai calls. If you suddenly get a million calls, the Teler engine scales automatically. You can configure your Application Logic Layer to automatically scale up its number of containers or functions. And your AI service providers are already built for massive, global scale. Every component scales independently.
This table summarizes the responsibilities of each layer in this distributed model.
| Architectural Layer | Core Responsibility | Key Technologies |
| Voice Infrastructure (The “Voice”) | Real-time call connection, media streaming, and low-level call control. | A global CPaaS platform like FreJun AI’s Teler engine; Elastic SIP Trunking. |
| Application Logic (The “Brain”) | Orchestrating the conversation, managing business logic, and maintaining state. | Serverless functions (e.g., AWS Lambda), container orchestration (e.g., Kubernetes), microservices. |
| AI Services (The “Senses”) | Transcribing speech (STT), understanding intent (LLM), and synthesizing voice (TTS). | Third-party AI-as-a-Service providers (e.g., OpenAI, Google AI, AssemblyAI). |
Also Read: Integrating a Voice Calling SDK with Your AI Model: Step-by-Step Guide
What Are the Best Practices for a Multi-Region Voice Bot Deployment?
When you are building voice bots for a global audience, a single-region deployment is no longer sufficient. A multi-region voice bot deployment is essential for providing a low-latency experience for all of your users.

Co-Locate Your “Brain” and Your “Voice”
The most important principle is to co-locate your Application Logic Layer with your Voice Infrastructure Layer’s edge PoPs. If your users are in Asia, your FreJun AI Teler PoP in Singapore should be communicating with an instance of your application running in an AWS or Google Cloud region in Singapore. This minimizes the “middle mile” latency between the voice network and your logic, which is a critical part of the overall latency equation.
Design for Data Sovereignty
Different countries have different laws about where customer data can be stored and processed. A multi-region architecture allows you to deploy separate, isolated instances of your application in different geographic regions to comply with these data sovereignty requirements.
A recent report on data privacy highlighted that 75% of organizations say that data privacy is a top priority and a competitive differentiator, making this architectural choice a business imperative.
Also Read: Why Latency Matters: Optimizing Real-Time Communication with Voice Calling SDKs
Conclusion
The days of the monolithic voice application are over. The sheer scale and real-time demands of modern AI-powered conversations require a more sophisticated, resilient, and globally-aware architectural approach.
By embracing the principles of decoupling and distribution, and by building on top of a powerful, scalable telephony infrastructure like FreJun AI, developers can finally escape the limitations of the old world.
Microservices define the definitive architectural pattern for building voice AI, enabling teams to create voice bots that deliver not only intelligence but also true scalability for the modern, global enterprise.
Ready to start architecting your globally scalable voice bot? Schedule a demo with our team at FreJun Teler.
Also Read: Call Center Automation vs. Manual Operations: Which Is Better in 2025?
Frequently Asked Questions (FAQs)
The main problem is that it creates a single point of failure and a scalability bottleneck. You cannot scale the telephony component independently of the AI processing component, which means a slowdown in your AI can bring down your entire voice service.
Microservices for voice ai is an architectural approach where each distinct function of the voice bot (e.g., call handling, transcription, language understanding, response generation) is a separate, independent service. These services communicate with each other via APIs, creating a more flexible and scalable system.
A distributed voice bot system is one where the different components are not all running on a single server or in a single data center. The voice infrastructure might be at the network “edge,” while the core AI logic runs in a regional cloud, allowing for better performance and resilience.
A scalable telephony infrastructure is a voice network that can automatically handle a massive, sudden increase in call volume. This is a core feature of a modern, cloud-native platform like FreJun AI’s Teler engine.
Independent layers enable horizontal scaling for AI calls. When call volume spikes, the telephony layer scales automatically, and the stateless, microservice-based application layer scales horizontally by adding more containers or serverless function instances.
A multi-region voice bot deployment is where you have instances of application running in multiple regions around the world. It is important for two reasons. First one, it provides a low-latency experience for global users by processing their calls in a region close to them. Second is, it allows you to comply with local data sovereignty laws.
FreJun AI provides the foundational Voice Infrastructure Layer. Our Teler engine delivers globally distributed, scalable telephony infrastructure. It handles all complex, real-time telecommunications work and lets you focus on building your Application Logic Layer, the AI brain.
A “stateless” service is one that does not store any session data from one request to the next. This is important for scaling because any available instance of the service can handle any incoming request. This makes it very easy to add more instances behind a load balancer to handle increased traffic.
They communicate through a combination of synchronous API calls (for quick request-response interactions) and asynchronous event streams or webhooks (for notifications and triggering workflows).
While a basic understanding of cloud principles is helpful, a modern voice platform like FreJun AI abstracts away the most difficult parts (the global telephony). If your team is comfortable building and deploying standard, scalable web applications or microservices, you have the skills you need.