
For the past decade, the world of voice recognition has been stuck in a state of digital amnesia. A traditional Speech-to-Text (STT) engine operates in a perpetual “now.” It listens to a single utterance, transcribes it to the best of its ability, and then completely forgets it ever happened. It has no memory of the previous sentence, no knowledge of the conversation’s topic, and no understanding of the user’s ultimate goal.
Stateless transcription has a fundamental limitation. A new paradigm is emerging to overcome it. Context-aware speech recognition boosts accuracy and intelligence. This approach transform modern voice applications.
The future of voice AI is not just about turning sounds into words; it is about understanding the meaning and intent behind those words. This is only possible when the recognition process is not a series of isolated events, but a continuous, stateful conversation.
For developers and enterprises building the next generation of voice experiences, the choice of a voice recognition SDK is no longer just about raw accuracy on a single phrase. It is about finding a platform that enables continuous context tracking, creating a memory-powered STT system that gets smarter with every turn of the conversation.
Table of contents
What is the “Amnesia Problem” of Traditional Voice Recognition?
To appreciate the new paradigm, we must first understand the deep-seated limitations of the old one. A standard voice recognition SDK is a masterpiece of audio processing and machine learning, but its scope is intentionally narrow. It is designed to solve one problem: transcribing a single, isolated chunk of audio.
The Stateless World of Single-Utterance Transcription
Imagine a user is talking to a voice-enabled AI assistant to book a flight.
- User: “I want to book a flight to Boston.”
- Traditional STT: Hears this audio and, with high accuracy, transcribes it to the text “I want to book a flight to Boston.”
- User: “I need it for the fifth of September.”
- Traditional STT: Hears this second utterance completely on its own. It has no memory of the “flight to Boston” part. It just transcribes the new audio to “I need it for the fifth of September.”
This works, but it places the entire burden of managing the “context” on the application’s higher-level logic (the LLM). The STT engine itself is a dumb transcriber.
Why Does This Statelessness Lead to Errors?
This “amnesia” is a major source of transcription errors, especially with ambiguous or domain-specific words.
- The Homophone Problem: Consider the sentence, “I need to book a flight.” In isolation, the sound “flight” could be misinterpreted, especially on a noisy connection. But if the STT engine knew that the conversation was about travel, it would be much more likely to choose the correct word.
- The Jargon Problem: Imagine a doctor dictating notes: “The patient is showing signs of mitral stenosis.” A general-purpose STT that does not know the context is “cardiology” might transcribe that as “my trial stenosis” or some other nonsense.
Also Read: How Long Does It Take to Go from Prototype to Production While Building Voice Bots?
What is Context-Aware Speech Recognition?
Context-aware speech recognition is a revolutionary approach that breaks down the wall of amnesia. It is a system where the STT engine is no longer a stateless transcriber, but an active, stateful participant in the conversation. It maintains a “memory” of the conversation, and it uses this memory to dramatically improve the accuracy and relevance of its transcriptions.
The Power of a Memory-Powered STT
A memory-powered STT system is one that can be “primed” with contextual information at the beginning of and throughout a conversation. This context can take several forms:
- Domain Context: You can tell the STT engine that this conversation is about “healthcare” or “finance.” This allows the engine to give a higher weight to words and phrases that are common in that specific domain.
- Dynamic Vocabulary (Real-Time Biasing): This is the most powerful feature. You can provide the STT engine with a list of “hints”, specific, and perhaps unusual, words that are likely to come up in the conversation.
- Conversational History: An advanced system can even use the transcript of the previous conversational turns as a form of short-term memory to help it better interpret the current utterance.
This process of continuous context tracking is a game-changer for accuracy. It turns the STT engine from a generic tool into a highly specialized expert on your specific conversation.
This table illustrates the dramatic difference in how the two models handle a challenging transcription.
| User’s Utterance | The Traditional, Stateless STT Hears… | The Context-Aware, Memory-Powered STT Hears… | Why the Difference? |
| “My name is Siobhan O’Malley.” | “My name is Shove on O’Malley.” | “My name is Siobhan O’Malley.” | The STT was “primed” with the customer’s name from the CRM. |
| “I need a flight to Logan.” | “I need a flight to low-gun.” | “I need a flight to Logan.” | The STT was given the domain context of “travel” and a hint list of airport names. |
| “We need to check the Q2 EBITDA.” | “We need to check the cue to eat it raw.” | “We need to check the Q2 EBITDA.” | The STT was given a hint list of financial acronyms common to the business. |
Ready to build a voice agent that actually understands your business’s unique language? Sign up for FreJun AI
Also Read: What Monetization Strategies Work After Building Voice Bots for Businesses?
What is the Role of the Voice Recognition SDK in This?
The voice recognition SDK and its underlying platform are the essential enablers of this contextual intelligence. A basic SDK might only provide a simple API to start and stop a transcription. An advanced, enterprise-grade SDK provides the rich set of tools needed to manage and inject context throughout the life of a call.
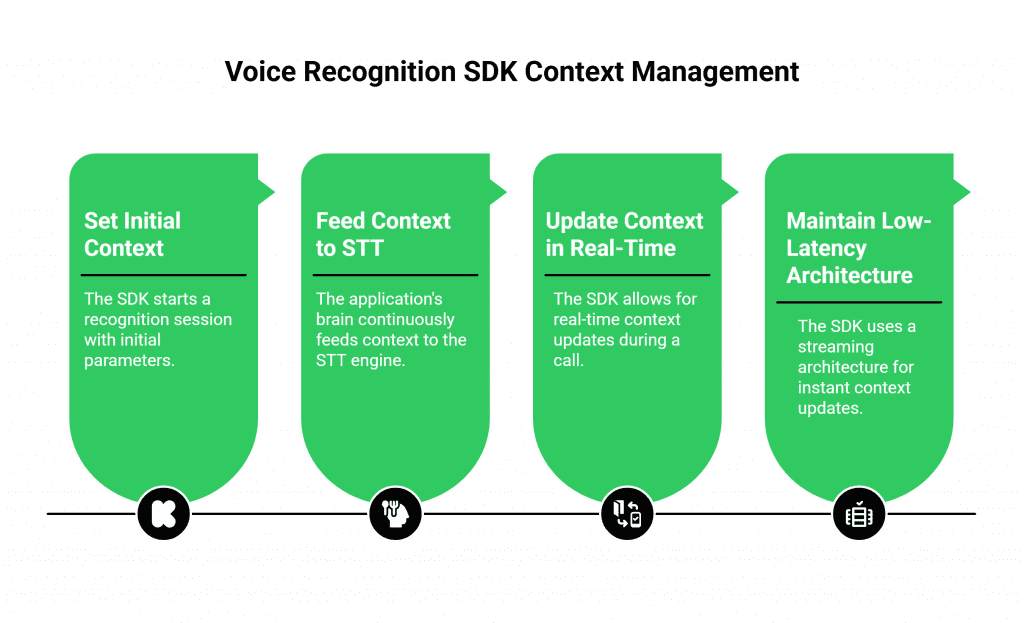
The Developer’s Toolkit for Continuous Context Tracking
A modern voice recognition SDK from a provider like FreJun AI provides the critical “hooks” that allow your application’s “brain” to continuously feed context to the STT “ears.” This includes:
- An API for Setting Initial Context: The ability to start a recognition session with a set of parameters that define the domain and provide an initial list of hint words.
- Real-Time Context Updates: The power to send a new API command in the middle of a live call to update the contextual hints.
- A Low-Latency, Streaming Architecture: For continuous context tracking to be effective, the entire system must be incredibly fast. The SDK must use a real-time streaming architecture. It must pass context updates to the STT engine instantly. This design keeps delays minimal and performance high.
The FreJun AI Approach: The Flexible Foundation for Context
At FreJun AI, we understand that the future of voice recognition is contextual. Our entire platform is designed to be a flexible, model-agnostic, and high-performance foundation for building these intelligent systems.
- Model Agnosticism is Key: We are not an STT provider. We are an infrastructure provider. This is a critical distinction. It means you are never locked into a single recognition engine. You can choose the absolute best, most advanced context-aware speech recognition provider on the market and seamlessly integrate it into your voice workflow using our platform.
- The High-Speed “Plumbing”: Our Teler engine provides the reliable, low-latency, real-time audio streaming that is the non-negotiable prerequisite for this kind of advanced, stateful recognition. We handle the immense complexity of the voice network so you can focus on the intelligence of your AI. The need for this specialized infrastructure is clear.
A recent report on enterprise AI adoption found that 90% of organizations cite the complexity of integration as a major barrier to AI deployment, a problem our platform is specifically designed to solve.
Also Read: How Can Building Voice Bots Improve Customer Experience Across Channels?
Conclusion
The era of the “amnesiac” voice recognition system is coming to an end. The future of voice interaction is not just about transcription; it is about comprehension. Context-aware speech recognition is the groundbreaking technology that is finally allowing our AI to move beyond simply hearing words to truly understanding the conversation.
By leveraging a modern voice recognition SDK that enables continuous context tracking and the power of a memory-powered STT, developers can build a new generation of voice agents that are not just more accurate, but fundamentally more intelligent. This is the key to creating voice experiences that are not just functional, but are genuinely helpful, efficient, and even delightful for the user.
Want to do a deep dive into the architecture of how to stream real-time audio from our platform to a context-aware STT engine? Schedule a demo for FreJun Teler.
Also Read: How to Set Up IVR Software for Your Call Center (Step-by-Step Guide)
Frequently Asked Questions (FAQs)
The main limitation is that it is “stateless.” A traditional Speech-to-Text (STT) engine transcribes each utterance in isolation, with no memory or understanding of the previous parts of the conversation.
Real-time biasing is another term for dynamically providing hint words to the STT engine. It is the process of “biasing” the AI to listen for certain words, which is a core part of continuous context tracking.
One key benefit is improved accuracy: supplying industry jargon, product names, and participant names helps the AI correctly transcribe hard words. (20 words)
No, FreJun AI is a voice infrastructure provider. Our platform is model-agnostic, which means we provide the powerful “plumbing” and the voice recognition SDK that allows you to connect and use the best, most advanced context-aware STT engine from any provider on the market.
Yes. An advanced voice recognition SDK allows a developer to send an API command during a live call to update the list of hint words, enabling true continuous context tracking as the conversation evolves.
While the underlying AI is complex, a well-designed SDK makes it relatively straightforward for a developer. Developers must gather relevant context from their applications. For example, they can pull a customer name from a CRM. They then call a simple API to send that context to the STT engine. This process improves recognition accuracy without adding friction.
It improves the experience by making the bot feel more intelligent and less frustrating. When the bot can correctly understand a complex name or a specific product number on the first try, the user gains confidence in the system and the conversation is much more efficient.