
Voice has become a core interface for modern applications. However, as call volumes increase and AI-driven conversations move into production, many systems begin to fail in subtle but costly ways. Latency rises, accuracy drops, and conversational flow breaks. While teams often focus on choosing the right AI model, the real challenge lies in handling audio reliably at scale. High-volume voice processing introduces unique constraints around streaming, concurrency, and session management that traditional APIs were never designed to solve.
This is where a voice recognition SDK becomes essential. In this blog, we break down why scalable audio recognition requires purpose-built infrastructure and how teams can architect voice systems that work reliably under real-world enterprise load.
Why Is Voice Becoming A Core System For Modern Applications?
Voice is no longer limited to call centers or basic IVR systems. Instead, it has become a primary interaction layer for modern applications. From customer support and sales outreach to healthcare triage and logistics coordination, voice is now deeply integrated into how businesses operate.
At the same time, AI adoption has accelerated this shift. As organizations deploy AI agents to handle conversations, the volume of audio being generated and processed has increased rapidly. Consequently, teams are no longer dealing with hundreds of calls per day but thousands or even millions of minutes of audio.
According to Fortune Business Insights, the global speech and voice recognition market is projected to grow from USD 19.09 billion in 2025 to USD 81.59 billion by 2032, with a strong 23.1% CAGR, underscoring rapid enterprise demand for voice technology.
However, while AI models have improved significantly, the underlying voice infrastructure often remains outdated. As a result, many systems struggle to process voice reliably at scale. This is where the need for a voice recognition SDK becomes clear.
In other words, voice is not just a feature anymore. It is a system-level capability that requires dedicated engineering attention.
What Makes High Volume Audio Processing Fundamentally Different From Text Or Files?

At first glance, audio may appear similar to other data types. However, high volume audio processing introduces challenges that do not exist in text or file-based systems.
Audio Is Continuous, Not Discrete
Text and files are processed as complete units. Audio, on the other hand, is a continuous stream.
- There is no clear “end” during live calls
- Data arrives in small frames over time
- Processing must happen while audio is still arriving
Because of this, systems must handle streaming input, not batch requests.
Latency Directly Impacts User Experience
With text-based systems, delays of a few seconds may be acceptable. However, in voice interactions, latency becomes immediately noticeable.
- Delays above 300 milliseconds feel unnatural
- Pauses break conversational flow
- Overlapping speech causes confusion
Therefore, high-volume audio systems must process, analyze, and respond within strict latency limits.
Real-World Audio Is Messy
Unlike clean audio files, production voice data includes:
- Background noise
- Accents and dialects
- Network jitter and packet loss
- Telephony compression artifacts
As a result, scalable audio recognition requires systems that are resilient to imperfect inputs.
What Is A Voice Recognition SDK And How Is It Different From A Simple Speech API?
This distinction is critical, especially for engineering leaders designing production systems.
Speech APIs Solve A Narrow Problem
Most speech APIs are designed for:
- File uploads
- Short audio clips
- Stateless requests
While these APIs work well for experimentation or low-volume use cases, they struggle under sustained load.
A Voice Recognition SDK Solves A System Problem
A voice recognition SDK provides long-lived control over audio streams. Instead of treating each request independently, it manages the entire lifecycle of an audio session.
A typical SDK handles:
- Persistent audio connections
- Real-time streaming input
- Audio buffering and frame management
- Partial and incremental recognition
- Error recovery and retries
Because of this, SDKs are better suited for high volume audio SDK use cases, where reliability and continuity matter.
Key Differences At A Glance
| Capability | Speech API | Voice Recognition SDK |
| Streaming audio | Limited | Native support |
| Session management | Stateless | Stateful |
| Latency control | Minimal | Fine-grained |
| Error handling | Basic | Built-in |
| High concurrency | Weak | Designed for scale |
As systems grow, these differences become impossible to ignore.
Why Do High Volume Systems Break Without A Dedicated Audio SDK?
Many teams initially rely on simple APIs. However, problems surface quickly once volume increases.
Connection Instability Under Load
Without persistent sessions, systems must repeatedly establish connections. Consequently:
- Connection overhead increases
- Failure rates rise
- Audio gaps appear
Over time, this leads to unreliable recognition.
Loss Of Conversational Context
In voice-driven workflows, context matters. Stateless processing makes it difficult to:
- Track who said what
- Maintain intent across turns
- Handle interruptions
As a result, conversations feel fragmented.
Latency Spikes At Peak Traffic
When thousands of calls occur simultaneously:
- Audio queues grow
- Processing delays compound
- Responses arrive too late
Eventually, user experience degrades, even if the AI logic is sound.
How Does A Voice Recognition SDK Enable Scalable Audio Recognition?
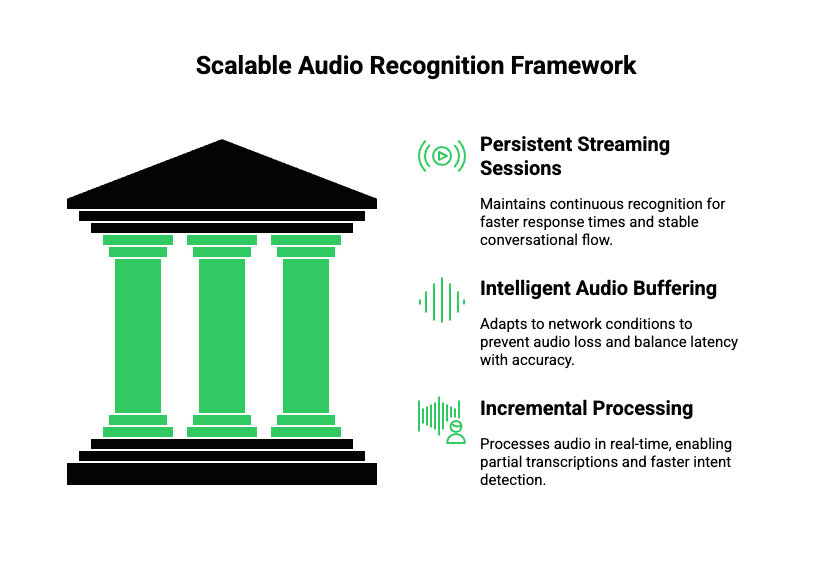
This is where SDK-based architecture shows its value.
Persistent Streaming Sessions
Instead of restarting processing for every audio chunk, SDKs maintain an open session. This allows:
- Continuous recognition
- Faster response times
- Stable conversational flow
Because sessions remain active, systems respond more predictably under load.
Intelligent Audio Buffering
Network conditions are rarely perfect. Therefore, SDKs use adaptive buffering to:
- Smooth out jitter
- Prevent audio frame loss
- Balance latency and accuracy
This is essential for scalable audio recognition in real-world environments.
Incremental Processing
Rather than waiting for full sentences, SDKs process audio incrementally.
This enables:
- Partial transcriptions
- Faster intent detection
- Early AI responses
As a result, conversations feel natural, even at scale.
What Role Does Batch Voice Processing Play In High-Volume Audio Workflows?
While real-time processing is critical, batch voice processing still plays an important role.
Common Batch Use Cases
- Post-call transcription
- Quality assurance analysis
- Compliance audits
- Training data generation
Batch workflows allow teams to process large volumes of recorded audio efficiently.
Why SDK-Based Pipelines Simplify Batch Processing
When real-time and batch processing share the same audio pipeline:
- Data formats remain consistent
- Metadata stays attached
- Debugging becomes easier
Therefore, teams avoid building separate systems for live and offline workloads.
How Do Enterprises Handle Load, Concurrency, And Reliability In Voice Systems?
At enterprise scale, reliability becomes non-negotiable.
Concurrency Is The Default State
High-volume environments often involve:
- Thousands of parallel calls
- Independent audio streams
- Isolated processing pipelines
SDK-based systems are designed to manage this concurrency safely.
Fault Isolation And Recovery
When failures occur, systems must recover without affecting other sessions. SDKs help by:
- Isolating per-call state
- Restarting streams gracefully
- Avoiding global failures
This is essential for enterprise load handling.
How Do Voice Recognition SDKs Power Modern Voice Agents?
Modern voice agents are not standalone systems. Instead, they are composed of multiple layers working together.
A typical voice agent includes:
- Speech-to-text for input
- Language models for reasoning
- Tools and databases for actions
- Text-to-speech for output
However, none of these components function well without a reliable voice layer. A voice recognition SDK acts as the transport layer that connects these pieces in real time.
Without it, even the most advanced AI logic fails to deliver consistent results.
Why Is Voice Infrastructure More Important Than The AI Model Itself?
As AI adoption grows, many teams focus heavily on selecting the “right” model. However, in voice systems, the model is rarely the limiting factor. Instead, the voice infrastructure determines whether an application works reliably at scale.
While language models can be swapped or upgraded over time, voice infrastructure is deeply embedded into system design. Therefore, early infrastructure decisions often define long-term success or failure.
Several factors make infrastructure more critical than the model:
- Voice interactions are time-sensitive
- Latency directly affects user trust
- Audio streams cannot be replayed easily
- Failures are immediately noticeable
Because of this, even a strong LLM will fail if audio input arrives late, drops mid-sentence, or loses context between turns.
In practice, most production issues in voice agents are not caused by reasoning errors. Instead, they stem from unstable audio streams, poor concurrency handling, or unreliable session management.
How Do Calling-First Platforms Fall Short For AI Voice Systems?
Many platforms in the market were originally built for outbound dialing, IVRs, or call routing. While they handle telephony well, they were not designed for AI-driven conversations.
As a result, several limitations appear when teams try to layer AI on top.
Media-First, Not Data-First Design
Calling platforms often treat audio as media to be played or recorded. However, AI systems treat audio as data that must be processed in real time.
This mismatch causes issues such as:
- Delayed access to audio frames
- Limited streaming control
- Weak integration with STT and LLM pipelines
Rigid Call Flow Logic
Traditional call flows rely on predefined paths. In contrast, AI voice agents require:
- Dynamic turn-taking
- Interrupt handling
- Real-time intent changes
Without a flexible voice recognition SDK underneath, these behaviors become difficult to implement.
What Does A Production-Grade Voice Recognition Stack Look Like Today?
To understand where SDKs fit, it helps to look at the full stack.
A modern high-volume voice system typically includes:
- Voice ingestion layer
- Captures real-time audio
- Handles telephony and VoIP protocols
- Captures real-time audio
- Voice recognition SDK
- Maintains streaming sessions
- Buffers and forwards audio
- Ensures low-latency delivery
- Maintains streaming sessions
- Speech-to-text engine
- Converts audio to text incrementally
- Converts audio to text incrementally
- AI reasoning layer
- LLMs or agent frameworks
- Context tracking and decision-making
- LLMs or agent frameworks
- Tool and data access
- CRMs, ticketing systems, scheduling APIs
- CRMs, ticketing systems, scheduling APIs
- Text-to-speech engine
- Generates natural audio responses
- Generates natural audio responses
- Playback and call control
- Streams audio back to the caller
- Streams audio back to the caller
Among these layers, the voice recognition SDK is the glue. Without it, integration becomes fragile and difficult to scale.
Sign Up for FreJun Teler Today
How Does FreJun Teler Fit Into A High Volume Voice Recognition Stack?
At this point, it becomes clear that teams need a dedicated voice infrastructure layer. This is where FreJun Teler fits in.
FreJun Teler is designed specifically as a global voice infrastructure for AI agents, not as an AI model or chatbot platform.
From a technical perspective, Teler focuses on the hardest problems in high volume audio processing:
- Real-time, bidirectional audio streaming
- Stable session management across calls
- Low-latency audio delivery at scale
- Compatibility with telephony and VoIP networks
Importantly, Teler is model-agnostic. Teams can integrate:
- Any LLM
- Any speech-to-text engine
- Any text-to-speech system
Teler acts as the transport and orchestration layer, allowing engineering teams to focus on AI logic rather than audio reliability.
How Can Teams Implement Teler With Any LLM, STT, And TTS?
From an implementation standpoint, the architecture remains flexible.
A typical flow looks like this:
- An inbound or outbound call connects to the system
- Audio is streamed in real time through the voice recognition SDK
- Audio frames are forwarded to the chosen STT engine
- Transcribed text is sent to the LLM
- The LLM performs reasoning, tool calls, or data retrieval
- The response text is converted to audio using TTS
- Audio is streamed back to the caller with minimal delay
Because Teler maintains persistent sessions, conversational context stays intact throughout the call. As a result, interruptions, follow-up questions, and dynamic responses work naturally.
This architecture also supports:
- Multi-language voice agents
- AI handoffs to human agents
- Hybrid real-time and batch voice processing
When Should Teams Invest In A High Volume Audio SDK?
Not every project starts at enterprise scale. However, certain signals indicate it is time to invest in a high volume audio SDK.
Common triggers include:
- Call volume increasing month over month
- Latency becoming noticeable to users
- Difficulty maintaining conversational context
- Rising failure rates during peak traffic
- AI agents moving from pilots to production
At this stage, patching together APIs becomes risky. Instead, teams benefit from a purpose-built voice recognition SDK that supports growth.
What Should Engineering Leaders Look For In A Voice Recognition SDK?
Choosing the right SDK requires careful evaluation. While features matter, architecture matters more.
Core Technical Capabilities To Evaluate
- Native real-time streaming support
- Persistent session handling
- Fine-grained latency control
- High concurrency and isolation
- Compatibility with multiple AI stacks
Enterprise Readiness Considerations
- Security and data integrity
- Geographic redundancy
- Predictable uptime
- Support for batch voice processing
A strong SDK enables scalable audio recognition without locking teams into a single AI vendor.
How Does A Voice Recognition SDK Support Long-Term Scalability?
Scalability is not just about handling more traffic. It is also about adapting to change.
Over time, teams may:
- Switch LLM providers
- Improve speech models
- Add new tools or workflows
A well-designed voice recognition SDK absorbs these changes without requiring major rewrites. Consequently, teams can evolve their AI capabilities while keeping the voice layer stable.
This separation of concerns becomes critical as systems mature.
Why Voice Recognition SDKs Are The Foundation Of Scalable Voice AI
As voice becomes a primary interface, the need for reliable infrastructure grows. High volume audio processing introduces challenges that cannot be solved with simple APIs or ad-hoc solutions.
A voice recognition SDK provides:
- Stability under load
- Low-latency streaming
- Consistent conversational context
- Flexibility across AI models
When paired with a purpose-built infrastructure layer like FreJun Teler, teams can confidently deploy voice agents in production environments.
In the end, successful voice AI systems are not defined by intelligence alone. They are defined by how reliably they listen, process, and respond at scale.
That reliability starts with the right voice recognition SDK.
Final Takeaway
High-volume audio processing is not a model problem—it is an infrastructure problem. As voice agents move from experiments to production systems, reliability, latency control, and scalability become more important than raw AI capability. A voice recognition SDK provides the foundation required to manage real-time audio streams, maintain conversational context, and handle enterprise-level concurrency without breaking under load. When paired with the right voice infrastructure, teams gain the flexibility to use any LLM, any speech engine, and any workflow while keeping the voice layer stable and performant.
FreJun Teler is built precisely for this challenge. It provides a global, low-latency voice infrastructure designed for AI agents at scale.
Schedule a demo to see how Teler can power your production voice systems.
FAQs –
1. What is a voice recognition SDK?
A voice recognition SDK manages real-time audio streams, sessions, and reliability for scalable speech processing in production environments.
2. Why are speech APIs not enough for high-volume audio?
APIs are stateless and struggle with streaming, latency control, and concurrency required for enterprise-scale voice systems.
3. What does high-volume audio processing mean?
It refers to handling thousands of concurrent audio streams with low latency, accuracy, and reliability across real-world network conditions.
4. How does a voice SDK improve latency?
It enables persistent streaming sessions, incremental processing, and adaptive buffering to reduce delays in real-time conversations.
5. Can voice recognition SDKs work with any LLM?
Yes, modern SDKs are model-agnostic and integrate with any LLM, STT, or TTS without locking teams into vendors.
6. What is batch voice processing used for?
Batch processing supports post-call analytics, compliance audits, quality assurance, and training data generation at scale.
7. Why does enterprise load handling matter in voice systems?
High call volumes demand isolation, fault tolerance, and concurrency management to prevent failures during traffic spikes.
8. Are voice agents only useful for call centers?
No, voice agents power sales, support, scheduling, notifications, and operational workflows across many industries.
9. When should teams adopt a voice recognition SDK?
When call volume grows, latency becomes noticeable, or voice agents move from pilots into production deployments.
10. How does FreJun Teler fit into voice AI systems?
Teler provides the real-time voice infrastructure layer that reliably connects AI models with telephony and VoIP networks.