
Building voice-first AI systems requires a mindset shift. Unlike text-based workflows, voice interactions demand real-time responsiveness, stable media transport, and careful orchestration between infrastructure and intelligence layers. As seen throughout this guide, successful voice AI is less about individual components and more about how well they work together under real-world conditions.
From latency constraints to scalability and security, every design decision compounds over time. Before closing, it’s important to step back and look at what truly enables voice systems to move from experiments to production-grade platforms – and how teams can future-proof their architecture as AI capabilities continue to evolve.
What Does It Mean To Integrate A Voice Chat SDK With An LLM?
At its core, integrating a voice chat SDK with a chatbot or Large Language Model (LLM) means enabling real-time, two-way voice conversations between humans and AI. However, this is not a simple feature add-on. Instead, it is a system-level integration that combines voice infrastructure, AI orchestration, and low-latency media streaming.
In a text-based chatbot, input and output are asynchronous. A user types, the model responds, and delays are acceptable. In contrast, chatbots with voice must function like human conversations. Pauses longer than a few hundred milliseconds feel unnatural. Therefore, voice chat SDK integration requires a fundamentally different approach.
Specifically, a voice-enabled LLM must:
- Capture live audio in real time
- Convert speech into text continuously
- Stream partial text into the LLM
- Generate responses incrementally
- Convert responses back into speech
- Play audio without noticeable delay
Because of this, LLM voice integration is less about UI and more about streaming systems, concurrency, and orchestration.
Why Can’t Traditional Chatbots Handle Real-Time Voice Conversations?
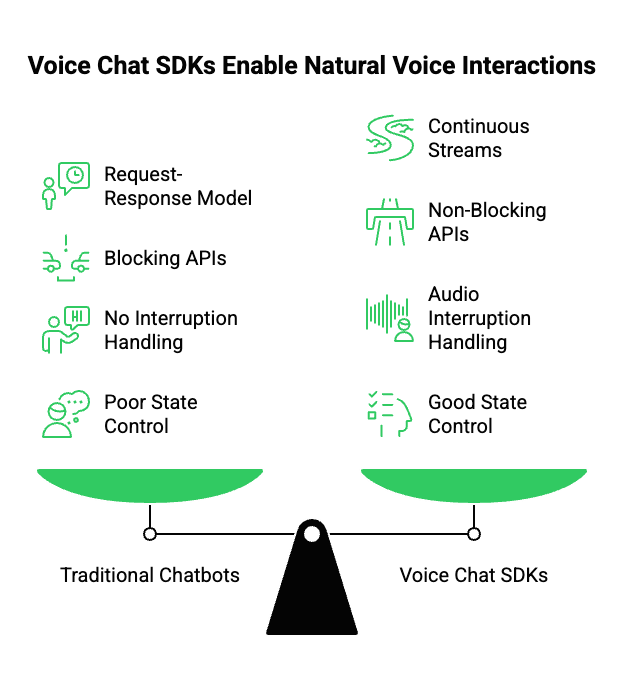
Although traditional chatbots are effective for many use cases, they struggle with voice for several reasons. First, most chatbots operate on request-response models. However, real-time voice requires continuous streams rather than discrete requests.
Secondly, REST-based APIs introduce blocking behavior. Each delay compounds. As a result, conversations feel slow and disjointed. In voice, this breaks user trust almost immediately.
More importantly, human conversation is interrupt-driven. People pause, correct themselves, and talk over each other. Traditional chatbots are not designed to handle these patterns.
Key limitations include:
- Latency sensitivity: Humans perceive delays above ~500ms as awkward
- No partial processing: Waiting for full transcripts slows responses
- No audio interruption handling: Users cannot “barge in” naturally
- Poor state control: Dialogue context resets easily
Therefore, if your goal is natural voice interaction, a different architecture is required. This is exactly where a voice chat SDK becomes essential.
What Are The Core Components Of A Voice-Enabled LLM System?
Before discussing implementation, it is important to break the system into clear components. A production-ready voice AI system is not a single service. Instead, it is a pipeline where each part handles a specific responsibility.
Below is the standard stack used in voice chat SDK integration.
| Layer | Responsibility |
| Voice Chat SDK | Capture and stream real-time audio |
| Speech-To-Text (STT) | Convert live audio into text |
| LLM | Generate responses and reasoning |
| Context Layer | Maintain conversation state and memory |
| Tools & RAG | Retrieve data and perform actions |
| Text-To-Speech (TTS) | Convert responses into audio |
| Orchestration Backend | Coordinate all components |
Together, these components enable chatbots with voice to behave like real conversational agents.
How Does A Voice Chat SDK Fit Into This Architecture?
At this point, it helps to clarify the role of a voice chat SDK. The SDK is not responsible for intelligence. Instead, it acts as the real-time transport and control layer for audio.
Specifically, a voice chat SDK:
- Manages audio capture from calls or devices
- Streams audio using low-latency protocols
- Handles audio encoding, buffering, and playback
- Maintains call sessions and lifecycle events
Because of this, the SDK becomes the foundation for everything else. Without it, developers are forced to manage raw audio streams, codecs, and network issues manually, which quickly becomes unmanageable.
As a result, most teams treat the voice chat SDK as infrastructure, not application logic.
How Does A Voice Chat SDK Connect To An LLM?
One of the most common questions engineers ask is: how to connect a voice SDK to an LLM?
The answer lies in streaming, not batching.
Below is the sequential flow used in modern LLM voice integration.
- The voice SDK captures live audio from the user
- Audio chunks are streamed to the backend
- A streaming STT engine converts audio into partial text
- Partial text is sent to the LLM as it arrives
- The LLM streams tokens back incrementally
- Tokens are converted into speech via TTS
- Audio is streamed back through the SDK
Because this loop runs continuously, the system feels responsive. Even more importantly, the LLM can “think while the user speaks,” which reduces response time noticeably.
Why Partial Transcripts Matter
Instead of waiting for the user to stop talking, partial transcripts allow:
- Faster intent detection
- Early response preparation
- Natural turn-taking
As a result, the conversation feels fluid rather than robotic.
What Integration Patterns Are Common For Voice-Driven LLMs?
Although the core flow remains consistent, different applications use different integration patterns. Understanding these patterns helps teams design systems that scale.
1. Pass-Through Integration Pattern
This is the most flexible pattern.
- Audio → STT → LLM → TTS → Audio
- The backend controls every step
- Supports advanced tooling and RAG
Because of this control, most production systems start here.
2. Hybrid Real-Time Pattern
In this pattern:
- Simple decisions are handled instantly
- Complex reasoning goes to the LLM
For example, call routing or keyword detection can happen without invoking the LLM. Therefore, latency and cost are reduced.
3. Tool-Driven Voice Agents
Here, the LLM acts as a controller.
- Voice triggers tool calls
- Tools fetch data or perform actions
- Results are summarized back into voice
This pattern is common for scheduling, payments, or CRM updates.
What Does A Step-By-Step Integration Flow Look Like?
Now that the architecture is clear, it is useful to walk through a real integration sequence. This is where many voice chat SDK integration projects fail due to poor ordering.
Step 1: Initialize The Voice Session
The SDK creates a session, assigns a call ID, and starts streaming audio.
Step 2: Stream Audio To STT
Audio is forwarded immediately. Interim transcripts are enabled.
Step 3: Feed Transcripts To The LLM
Partial and final transcripts are appended to the conversation state.
Step 4: Generate Streaming Responses
The LLM emits tokens as they are generated, not at the end.
Step 5: Convert Tokens To Audio
TTS receives short chunks and produces streamable audio.
Step 6: Handle Interruptions
If the user speaks again, audio output is paused gracefully.
Because each step overlaps in time, latency stays low.
How Should Conversation Context Be Managed In Voice Systems?
Unlike text chat, voice conversations are harder to rewind. Therefore, context handling must be deliberate.
Key best practices include:
- Maintain session state server-side
- Separate short-term turns from long-term memory
- Summarize older context to reduce token usage
- Use RAG only when needed, not on every turn
Additionally, context updates should happen continuously. This ensures that chatbots with voice respond consistently, even in long conversations.
Where Does FreJun Teler Fit In A Voice-Enabled LLM Architecture?
By now, the challenge is clear: building LLM voice integration is not about models alone. Instead, it depends on how reliably you can move audio in and out of real-world networks while keeping latency low.
This is where FreJun Teler fits in.
FreJun Teler acts as the voice transport and real-time media layer between phone networks and your AI stack. Instead of managing SIP, VoIP routing, codecs, buffering, and call lifecycle events yourself, Teler handles these concerns while remaining fully model-agnostic.
In practical terms, Teler:
- Captures real-time inbound and outbound call audio
- Streams audio with low latency over stable connections
- Maintains call sessions and state
- Sends and receives audio from your backend reliably
At the same time, Teler does not dictate:
- Which LLM you use
- Which STT or TTS provider you choose
- How conversation logic is implemented
Because of this separation, teams can focus on building intelligence while relying on a dedicated voice chat SDK to handle the complexity of telephony and real-time audio.
Why Does Latency Matter So Much In Voice LLM Systems?
Latency is the single most important technical factor in chatbots with voice. Even small delays affect how users perceive intelligence and trust.
Humans expect:
- Responses within a few hundred milliseconds
- Natural turn-taking
- Immediate interruption handling
However, latency accumulates across multiple layers. Therefore, it must be addressed holistically.
Common Sources Of Latency
- Audio capture and encoding
- Network transmission
- STT inference
- LLM processing
- TTS generation
- Audio playback buffering
Because each step adds delay, optimization must happen at every layer.
How Does FreJun Teler Help Reduce Voice Latency?
FreJun Teler is optimized specifically for real-time voice streaming, not batch calling workflows. As a result, it helps reduce latency in several ways.
Media-Level Optimizations
- Uses efficient audio codecs such as Opus
- Optimizes buffering for conversational flows
- Maintains persistent streaming connections
- Handles jitter and packet loss gracefully
Network-Level Benefits
- Routes calls using geographically distributed infrastructure
- Avoids unnecessary media hops
- Maintains consistent audio quality during calls
Because these capabilities are built into the voice chat SDK, developers do not need to re-engineer media pipelines themselves. Consequently, end-to-end response times drop noticeably.
How Do You Handle Interruptions And Barge-In Correctly?
Natural conversations involve interruptions. Users often start speaking before the AI finishes responding. If not handled properly, this creates frustration.
To manage this, a voice chat SDK integration must support barge-in logic.
A Typical Barge-In Flow
- AI starts speaking
- User begins talking
- Audio input is detected above threshold
- TTS playback is paused or stopped
- New audio is processed immediately
Because FreJun Teler maintains continuous audio streams, your backend can detect speech activity in real time and react instantly.
As a result, conversations feel less scripted and more human.
How Should Teams Secure Voice-Based LLM Applications?
Security becomes more complex once voice enters the system. Audio data can contain sensitive personal or financial information. Therefore, security must be addressed early.
Core Security Considerations
- Encrypted audio transport (SRTP / TLS)
- Secure API access and token rotation
- Strict session isolation
- Controlled data storage and retention
- Redaction of sensitive transcripts
FreJun Teler is designed with security by default, ensuring that audio integrity and confidentiality are maintained across the platform.
At the same time, developers retain full control over how transcripts, embeddings, and logs are stored or discarded.
How Do You Scale Voice LLM Systems Without Breaking Reliability?
Scaling voice systems is different from scaling text-based APIs. While text requests are short-lived, voice sessions can run for minutes. Therefore, architecture decisions matter.
Recommended Scaling Strategy
- Keep LLM workers stateless
- Isolate voice sessions with stable media connections
- Store conversation state in fast external stores
- Autoscale inference workers independently
Because FreJun Teler manages call lifecycle and persistence, backend services can scale horizontally without risking dropped calls.
As traffic grows, this separation helps maintain uptime and user experience.
How Does This Differ From Traditional Calling Platforms?
Many platforms offer “calling APIs.” However, their primary focus is automation, not conversation.
Traditional Calling Platforms
- Designed for IVRs and robocalls
- Batch-oriented workflows
- Limited real-time interaction
- Hard to integrate with modern LLM stacks
Voice AI Infrastructure (Like FreJun Teler)
- Built for continuous audio streaming
- Designed for two-way conversations
- Optimized for sub-second response times
- Model-agnostic by design
Because of these differences, teams building LLM voice integration often outgrow calling-first platforms quickly.
What Should Founders And Engineering Teams Build First?
Voice AI projects fail most often due to scope creep. Therefore, starting small is critical.
Recommended First Steps
- Pick a single, high-value voice use case
- Instrument latency from day one
- Keep models interchangeable
- Log conversations selectively for debugging
- Test with real users early
At the same time, choosing a flexible voice chat SDK early avoids painful rewrites later.
Final Thoughts
Integrating a voice chat SDK with chatbots and LLMs is not simply about adding speech. Instead, it requires designing real-time systems that respond naturally, remain dependable under scale, and adapt as AI models evolve. By clearly separating voice infrastructure, AI intelligence, and application logic, teams avoid tight coupling and gain long-term architectural flexibility.
FreJun Teler delivers the reliable, low-latency voice foundation required to make this separation work in production. It removes the operational burden of telephony and real-time media handling, allowing teams to focus on building intelligent, outcome-driven voice agents.
If you’re planning to deploy scalable, production-grade voice AI, FreJun Teler provides the infrastructure layer that lets your AI truly speak.
Schedule a demo.
FAQs –
- What is a voice chat SDK?
A voice chat SDK enables real-time audio capture, streaming, and playback for building voice-enabled applications and AI agents. - Can any LLM be connected to a voice SDK?
Yes. Most modern architectures allow model-agnostic LLM integration using streaming inputs and outputs. - Do voice chatbots require real-time processing?
Yes. Delays beyond a few hundred milliseconds negatively impact conversation quality and user trust. - What makes voice integration harder than text chat?
Voice requires low latency, streaming audio, interruption handling, and continuous state management. - Is telephony infrastructure necessary for voice AI?
For phone-based interactions, yes. Telephony ensures reliable connections across PSTN and VoIP networks. - How is conversation context handled in voice agents?
Context is managed server-side using session memory, summarized history, and optional retrieval systems. - Can voice agents scale like text-based AI systems?
Yes, if voice infrastructure and AI inference layers are independently scalable. - What causes most failures in voice AI projects?
High latency, poor interruption handling, and tightly coupled infrastructure choices. - Are voice AI systems secure for enterprise use?
They can be, when encrypted transport, access controls, and data governance are properly implemented. - When should teams add voice to their AI product?
Add voice when real-time interaction or phone-based access improves user experience or operational efficiency.