
Building a real-time voicebot takes more than just plugging in a large language model. From telephony to streaming and latency handling, the backend complexity often slows teams down. FreJun AI simplifies this process by acting as the real-time voice infrastructure for your AI.
With built-in SIP support, audio routing, and easy API integration, FreJun lets developers focus on intelligence, not plumbing. This guide shows how to create a scalable, production-ready voicebot that connects seamlessly with your own AI stack.
Table of contents
- The Challenge: Why Building Production-Ready Voice AI is So Hard
- The Anatomy of a Real-Time Vocal Bot: A Look Under the Hood
- The DIY Dilemma: The Hidden Costs of Building from Scratch
- The FreJun Solution: Focusing on AI, Not Infrastructure
- DIY Vocal Bot Setup vs. FreJun’s Managed Voice Infrastructure
- Your Blueprint for a Flawless Vocal Bot Setup Real-Time with FreJun
- Final Thoughts: Move from Concept to Conversation with Confidence
- Frequently Asked Questions (FAQ)
The Challenge: Why Building Production-Ready Voice AI is So Hard
Your business has a clear goal: to deploy sophisticated AI voice agents that can handle customer service inquiries, qualify leads, or automate outbound campaigns. You’ve seen the power of Large Language Models (LLMs) and you’re ready to bring that intelligence to your phone lines. The problem? Turning a text-based chatbot into a fluid, real-time conversational voice agent is a monumental technical challenge.
The dream is an AI that can listen, think, and speak without awkward delays. The reality for most development teams is a frustrating battle with latency, dropped connections, and a fragile patchwork of disparate services. You end up spending more time managing complex voice infrastructure than you do refining the AI logic that delivers actual business value. This is the critical bottleneck that prevents great AI concepts from becoming production-grade voice solutions.
The Anatomy of a Real-Time Vocal Bot: A Look Under the Hood
Before we can solve the infrastructure problem, it’s essential to understand the moving parts. A successful vocal bot isn’t a single piece of software; it’s an orchestrated system of highly specialized components that must work in perfect, low-latency harmony.

A typical Vocal Bot Setup Real-Time requires integrating four distinct modules:
- Real-Time Audio Streaming: This is the foundation. A system must capture the user’s voice from a phone call and stream it instantly to your processing services. Platforms like FastRTC or LiveKit are often used for this, typically relying on WebSocket connections for speed.
- Speech-to-Text (STT): Once the raw audio is streaming, an STT service (like Deepgram or AssemblyAI) must transcribe it into text in real-time. The accuracy and speed of this service are critical for the bot’s comprehension.
- AI/LLM Response Generation: The transcribed text is then sent to the “brain” of the operation,a conversational AI model like OpenAI’s GPT-4o or Groq. This model interprets the user’s intent, consults its knowledge base, and generates a relevant, human-like text response. Maintaining conversational context here is key to avoiding robotic, repetitive dialogue.
- Text-to-Speech (TTS): Finally, the AI’s text response must be converted back into audible speech using a TTS service, such as those from ElevenLabs or Cartesia. This synthesized voice is then streamed back to the user, completing the conversational loop.
Each step in this chain adds a potential point of failure and, more critically, latency. Even a delay of a few hundred milliseconds at any stage can accumulate, resulting in the awkward pauses that shatter the illusion of a natural conversation.
Also Read: Virtual PBX Phone Systems Implementation for Businesses in South Africa
The DIY Dilemma: The Hidden Costs of Building from Scratch
Faced with this complexity, many teams attempt a Do-It-Yourself (DIY) approach, selecting and integrating best-in-class services for STT, LLM, and TTS. While this offers control over the AI components, it introduces a significant and often underestimated burden: building and managing the underlying voice transport layer.
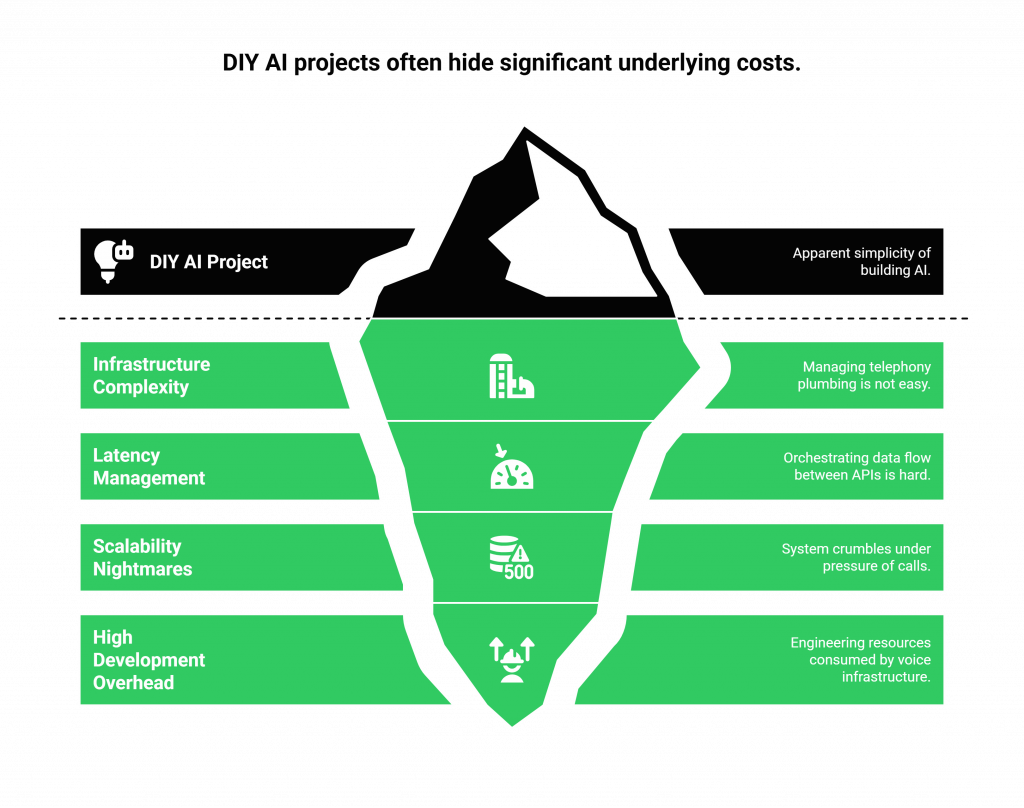
This DIY Vocal Bot Setup Real-Time creates several critical challenges:
- Infrastructure Complexity: You become responsible for the telephony “plumbing.” This involves managing phone numbers, handling inbound and outbound call legs, and ensuring a stable, low-latency media stream between the user and your various AI services. This is not a core competency for most application developers.
- Latency Management: You must manually orchestrate the data flow between four or more independent APIs (Call > Stream > STT > LLM > TTS > Stream > User). Minimizing the delay between each of these handoffs is a constant battle that requires deep expertise in real-time media processing and asynchronous programming.
- Scalability Nightmares: A system that works for one concurrent call may crumble under the pressure of ten, let alone hundreds. Scaling a real-time voice infrastructure requires horizontally scaling every component, from audio processing to API call management, often on expensive, GPU-optimized cloud instances.
- High Development Overhead: Your most valuable engineering resources are consumed by building and maintaining voice infrastructure instead of focusing on what truly differentiates your product: the intelligence of your AI. The development cycle for a robust, in-house solution can stretch from weeks into months.
This approach forces your team to become experts in telecommunications, a field far removed from the core task of building intelligent applications.
The FreJun Solution: Focusing on AI, Not Infrastructure
This is precisely where FreJun transforms the development process. FreJun is not another STT or TTS provider. We are the enterprise-grade voice transport layer built specifically for AI. We engineered our architecture from the ground up to handle complex voice infrastructure, so you can focus on building your AI.
FreJun AI provide the robust, low-latency “plumbing” that connects your phone calls to your chosen AI services. With FreJun, you bring your own AI,your preferred STT, LLM, and TTS providers, and maintain full control over your bot’s logic. We manage the real-time media streaming, call management, and telephony infrastructure, turning a complex integration nightmare into a simple, streamlined process.
Our developer-first SDKs and model-agnostic API allow you to move from concept to a production-grade Vocal Bot Setup Real-Time in days, not months. We deliver the speed and clarity required for powerful voice agents, eliminating the awkward pauses that break conversational flow.
Also Read: WhatsApp Chat Handling Strategies for Medium‑Sized Enterprises in Israel
DIY Vocal Bot Setup vs. FreJun’s Managed Voice Infrastructure
The choice between a DIY approach and a managed platform comes down to where you want to invest your time and resources. This table breaks down the key differences:
| Feature | DIY Vocal Bot Setup | FreJun’s Managed Voice Infrastructure |
| Core Focus | Manually integrating multiple APIs (Streaming, STT, LLM, TTS) and building call logic from scratch. | Focusing on AI logic while FreJun handles all voice transport and telephony infrastructure. |
| Telephony Management | Developer is responsible for acquiring numbers, managing call legs, and handling SIP/VoIP protocols. | FreJun manages all telephony, providing a simple API to control inbound and outbound calls. |
| Latency | High risk of cumulative latency from multiple API handoffs. Requires constant optimization. | Entire stack is pre-optimized for low-latency media streaming, ensuring natural conversations. |
| Development Effort | High. Requires expertise in real-time media, telecom, and distributed systems. Months of development. | Low. Developer-first SDKs for web and mobile allow for setup in days. |
| Scalability | Complex and costly. Requires manual scaling of each component and infrastructure management. | Built on resilient, geographically distributed infrastructure designed for high availability and scale. |
| AI Control | Full control, but requires complex orchestration. | Full control. FreJun is model-agnostic, allowing you to bring any STT, LLM, or TTS service you choose. |
| Support | Reliant on community forums and documentation from multiple vendors. | Dedicated integration support from pre-planning to post-launch optimization. |
Your Blueprint for a Flawless Vocal Bot Setup Real-Time with FreJun
With FreJun abstracting away the infrastructure complexity, the process of building a voice agent becomes dramatically simpler. You can focus on the three core logical steps, while our platform ensures the voice speed and clarity.
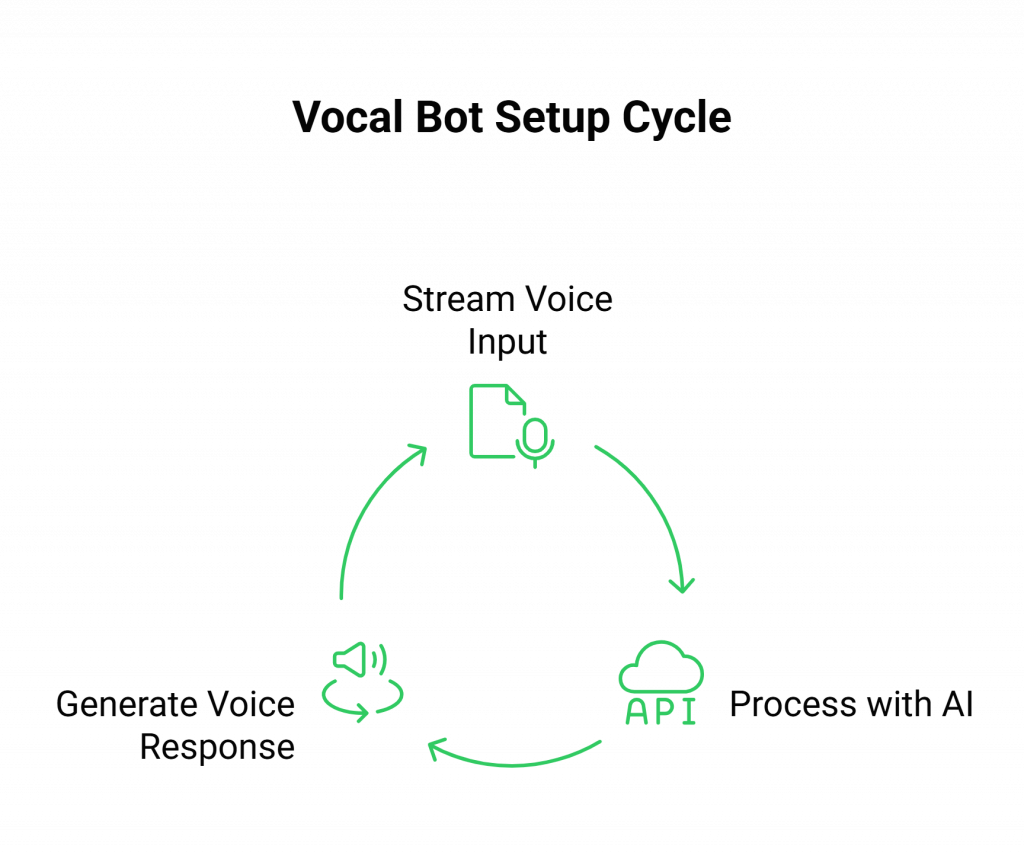
Here’s how a world-class Vocal Bot Setup Real-Time works with FreJun:
Step 1: Stream Voice Input with FreJun
This is the most complex part of a DIY setup, but it’s FreJun’s core strength. Our API captures real-time, low-latency audio from any inbound or outbound phone call.
- How it Works: Using our client-side or server-side SDKs, you initiate or receive a call. FreJun establishes a stable connection and begins streaming the raw audio directly to your application’s endpoint.
- The Benefit: You don’t need to worry about codecs, WebSockets, or packet loss. You get a crystal-clear audio stream, ensuring your STT service receives the highest quality input for accurate transcription.
Step 2: Process with Your AI (Your Stack, Your Control)
FreJun serves as a reliable transport layer, passing the voice data to your systems. Your application maintains full control over the dialogue state and AI logic.
- How it Works: Your backend receives the raw audio stream from FreJun. You pipe this audio to your chosen STT provider (e.g., Deepgram) to get a text transcription. You then pass this text to your LLM (e.g., GPT-4o) to generate a response.
- The Benefit: FreJun is model-agnostic. You are never locked into a specific AI provider. You can swap out STT, LLM, or context management solutions as better technology becomes available, all without changing your voice infrastructure.
Step 3: Generate and Stream the Voice Response via FreJun
Once your LLM has generated a text response, the final step is to convert it to audio and play it back to the user, completing the conversational loop.
- How it Works: You send the text response from your LLM to your chosen TTS service (e.g., ElevenLabs). You then simply pipe the resulting audio output from your TTS service back to the FreJun API.
- The Benefit: FreJun handles the low-latency playback to the user over the active call. This closes the loop instantly, creating a fluid, natural, and responsive conversational experience that keeps users engaged.
Final Thoughts: Move from Concept to Conversation with Confidence
Deploying sophisticated voice agents should be about strategic advantage, not infrastructural headaches. The market demands intelligent, responsive, and scalable voice automation for everything from customer support to proactive sales outreach. A DIY approach, while seemingly flexible, often results in a brittle, high-latency science project that is unfit for production.
A truly effective Vocal Bot Setup Real-Time requires an architecture designed for speed and reliability.
FreJun provides this architecture. By handling the entire voice transport layer, we empower your development teams to do what they do best: build powerful AI. Our model-agnostic API, comprehensive SDKs, and enterprise-grade infrastructure give you the tools to launch real-time voice agents in a fraction of the time, with the confidence that your solution is secure, reliable, and ready to scale.
Start Building the Voice AI Today with FreJun AI!
Further Reading: From Calls to Conversations: Voice-Based Conversational AI
Frequently Asked Questions (FAQ)
A real-time vocal bot requires four key components working in unison: a real-time audio streaming service, a Speech-to-Text (STT) engine, a Large Language Model (LLM) for response generation, and a Text-to-Speech (TTS) engine to create the audio response.
No. FreJun is a specialized voice transport layer. Our platform handles the complex telephony and real-time media streaming infrastructure that connects a phone call to your services. You bring your own STT, LLM, and TTS providers, giving you full control over your AI stack. We are the “plumbing,” not the AI itself.
Our entire platform is engineered for low-latency conversations. We use optimized real-time media streaming protocols and a geographically distributed infrastructure to minimize the delay between user speech, processing, and the voice response. This eliminates the awkward pauses that make conversations with bots feel unnatural.
You need to have your own AI logic and accounts with your preferred third-party services for Speech-to-Text (STT) and Text-to-Speech (TTS). FreJun provides the API and SDKs to seamlessly connect these services to the public telephone network.
Absolutely. FreJun is built on a resilient, high-availability infrastructure engineered to support mission-critical applications at enterprise scale. Our platform is designed to keep your voice agents online and performing reliably, even under heavy load.