
Real-time voice conversations are becoming the next leap in automation, and customers now expect AI to handle phone calls with the same fluency as live agents. But while AI models can think fast, building a system that lets them speak in real-time is far from trivial. FreJun solves this by providing a low-latency voice infrastructure that connects your AI to the public phone network seamlessly. This guide explains how to build and launch a reliable AI Voice Assistant using FreJun.
Table of contents
- The Next Leap in Automation: Real-Time Conversational AI
- The Hidden Challenge: Why DIY Voice Infrastructure Fails
- FreJun: The Infrastructure Layer for Your AI Voice Assistant
- Key Features for Building Production-Grade Voice AI
- The DIY Approach vs. The FreJun Advantage
- How to Deploy Your AI Voice Assistant with FreJun: A 4-Step Guide?
- Final Thoughts: Move from Concept to Conversation with Confidence
- Frequently Asked Questions
The Next Leap in Automation: Real-Time Conversational AI
The promise of artificial intelligence has always been to create systems that can interact with us as naturally as humans do. With the arrival of powerful multimodal AI models, that promise is finally being realized in real-time voice conversations. Businesses now have the potential to deploy a sophisticated conversational AI Voice Assistant capable of understanding context, detecting emotion, and responding instantly.
Imagine an AI that doesn’t just follow a rigid script but engages in a fluid, natural dialogue. It can handle complex customer inquiries, qualify leads with nuanced questions. It can also schedule appointments, all without the awkward pauses and robotic cadence of traditional systems. This isn’t science fiction; it’s the new frontier of business communication, made possible by direct speech-to-speech models that drastically reduce latency and enhance the conversational flow.
But while the AI models have become incredibly powerful, a critical and often underestimated challenge remains: how do you reliably connect this brilliant AI to a real-world phone call? The answer lies not in the AI itself, but in the underlying infrastructure that carries the conversation.
The Hidden Challenge: Why DIY Voice Infrastructure Fails
As engineering teams rush to integrate cutting-edge AI, they often discover that the biggest hurdle is not the AI logic, it’s the voice plumbing. Building a robust, low-latency, and scalable voice transport layer is a monumental task that distracts from the core objective of creating a superior AI experience.
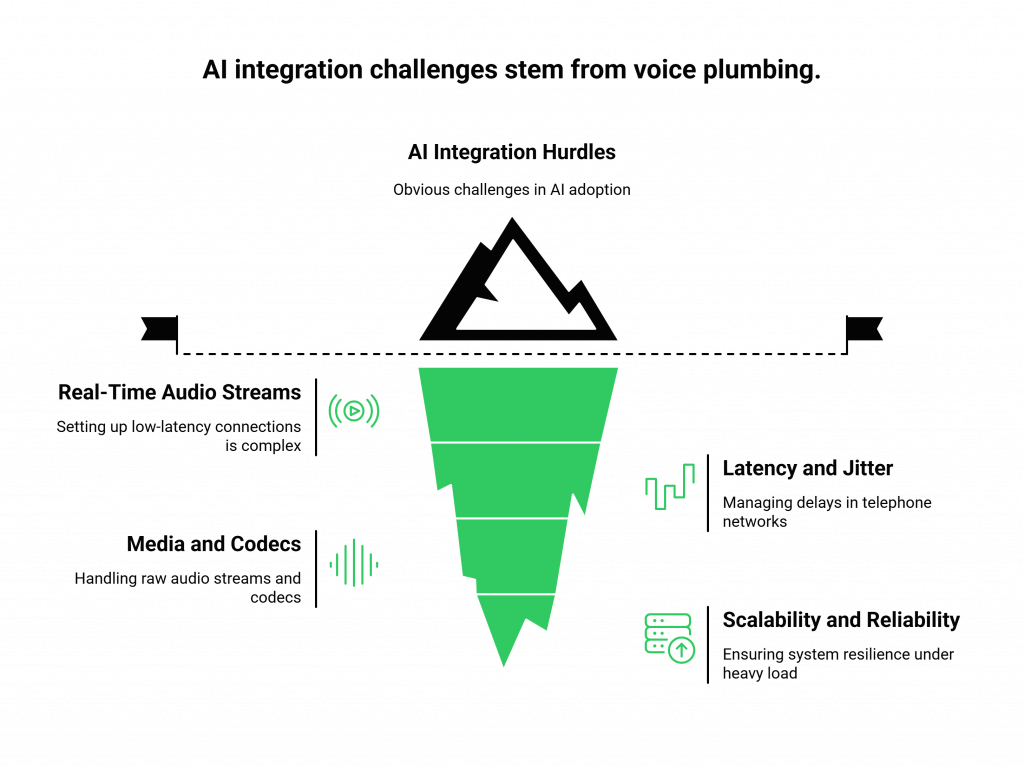
Attempting to build this infrastructure in-house or by stitching together generic telephony APIs introduces significant complexity and risk. Here’s what that looks like:
- Establishing Real-Time Audio Streams: You must set up and manage a persistent, low-latency connection between the telephone network and your backend application. This involves navigating the complexities of WebSockets for server-side agents or WebRTC for browser-based ones, each with its own set of protocols and failure points.
- Managing High Latency and Jitter: The telephone network is not the internet. It has unique challenges. Even milliseconds of delay can lead to unnatural pauses, causing callers to talk over the AI or hang up in frustration.
- Handling Raw Media and Codecs: Your application needs to receive a raw audio stream, process it, and send it to your AI. This requires handling various audio codecs, managing packet loss, and ensuring cross-platform compatibility,technical overhead that has nothing to do with your AI’s intelligence.
- Scalability and Reliability: What works for a single test call will crumble under the pressure of hundreds or thousands of concurrent calls. Building a system that is geographically distributed, resilient to outages, and capable of scaling on demand requires a dedicated team of infrastructure and telephony experts.
This DIY approach forces your best engineers to spend their time solving complex telephony problems instead of refining the conversational AI voice bot assistant.
Also Read: WhatsApp Chat Handling Strategies for Medium-Sized Enterprises in Iraq
FreJun: The Infrastructure Layer for Your AI Voice Assistant
There is a smarter way to build. Instead of diverting resources to reinvent the wheel of voice infrastructure, you can leverage a platform designed specifically for this purpose.
FreJun provides the critical transport layer that connects your AI to the world. Our architecture primarily focuses on: to handle the complex voice infrastructure with a relentless focus on speed and clarity, so you can focus exclusively on building the best possible AI.
We operate on a simple, powerful premise: Bring Your Own AI.
FreJun is model-agnostic. Whether you’re using OpenAI’s Realtime API, a custom-trained model, or a solution from ElevenLabs, our platform serves as the reliable and ultra-low-latency bridge between your AI logic and the end-user on the call. We manage the messy, complicated world of real-time media streaming, call management, and enterprise-grade reliability, turning your text-based or speech-to-speech AI into a powerful, production-ready voice agent.
Key Features for Building Production-Grade Voice AI
FreJun provides a complete toolkit designed to move your AI Voice Assistant from concept to production, backed by robust infrastructure and developer-first tooling.
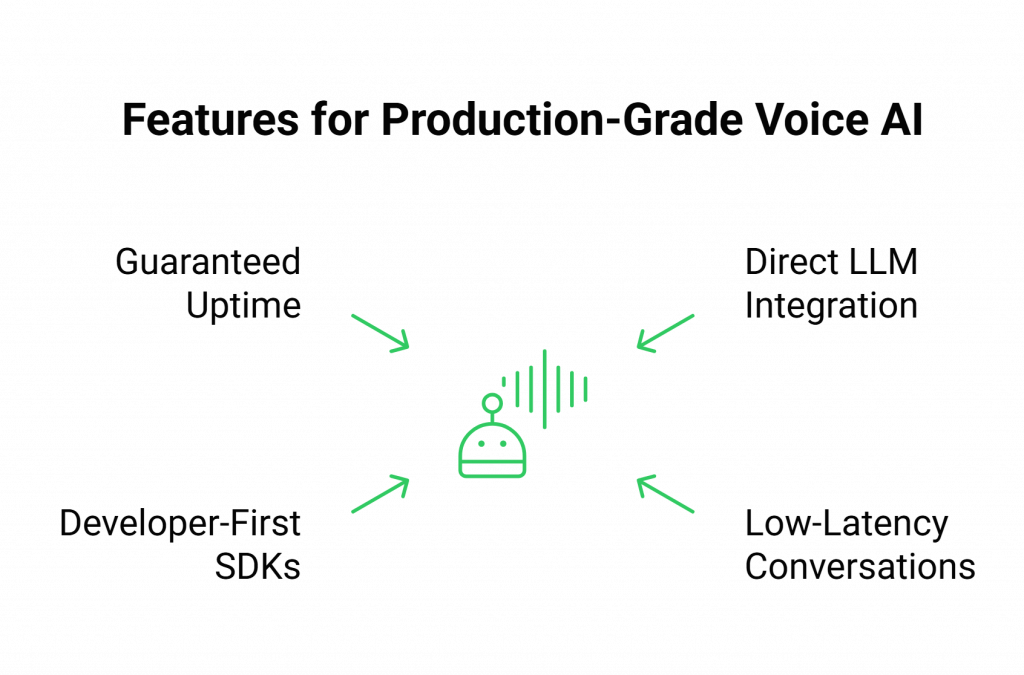
- Direct LLM & AI Integration: Our API is intentionally model-agnostic. You connect your chosen AI chatbot or Large Language Model, maintaining full control over the dialogue state, context management, and conversational logic. We handle the voice layer; you command the intelligence.
- Engineered for Low-Latency Conversations: Real-time media streaming is at the core of our platform. We have optimized every component of our stack, from carrier interconnects to our API delivery. It minimize the round-trip latency between user speech, AI processing, and voice response. This eliminates the awkward pauses that kill conversational flow and make AI interactions feel unnatural.
- Developer-First SDKs: Accelerate your development with our comprehensive client-side and server-side SDKs. You can easily embed voice capabilities into your web and mobile applications or manage call logic entirely from your backend.
- Guaranteed Uptime & Reliability: Mission-critical applications require a platform you can trust. FreJun is built on a resilient, geographically distributed infrastructure engineered for high availability. We ensure your voice agents remain online and accessible, providing the enterprise-grade security and reliability your business demands.
Also Read: Softphone Implementation for Business Growth in Remote Teams in Argentina
The DIY Approach vs. The FreJun Advantage
Choosing the right foundation for your conversational AI Voice Assistant is a strategic decision. The table below outlines the clear differences between a do-it-yourself approach and leveraging FreJun’s specialized infrastructure.
| Feature / Aspect | DIY / Native Approach | The FreJun Advantage |
| Infrastructure Management | You must build, manage, and scale complex WebRTC/WebSocket servers and telephony integrations. | Fully managed, robust voice infrastructure designed for real-time AI. |
| Development Focus | Your team’s focus is split between telephony engineering and AI development. | Your team focuses 100% on building and refining your AI’s conversational logic. |
| Conversational Latency | High risk of network and processing delays, leading to unnatural pauses and a poor user experience. | The entire stack is optimized for minimal latency, ensuring fluid, human-like conversations. |
| AI Model Flexibility | Often locked into a specific provider’s ecosystem or requires complex custom integrations. | Completely model-agnostic. Bring any STT, TTS, or LLM to our platform. |
| Scalability & Reliability | Requires a dedicated DevOps team and significant investment to build a resilient, scalable system. | Built on geo-distributed, high-availability infrastructure that scales with your needs. |
| Time-to-Market | Months of development and testing to build a production-ready system. | Launch sophisticated, real-time voice agents in days, not months. |
| Security & Compliance | You are responsible for implementing all security protocols and ensuring regulatory compliance. | Security is built into every layer of the platform, with guidance on compliance needs. |
How to Deploy Your AI Voice Assistant with FreJun: A 4-Step Guide?
Integrating your custom AI with FreJun is a straightforward process designed to get you running quickly. This guide demonstrates how FreJun simplifies the infrastructure so you can focus on the AI implementation.
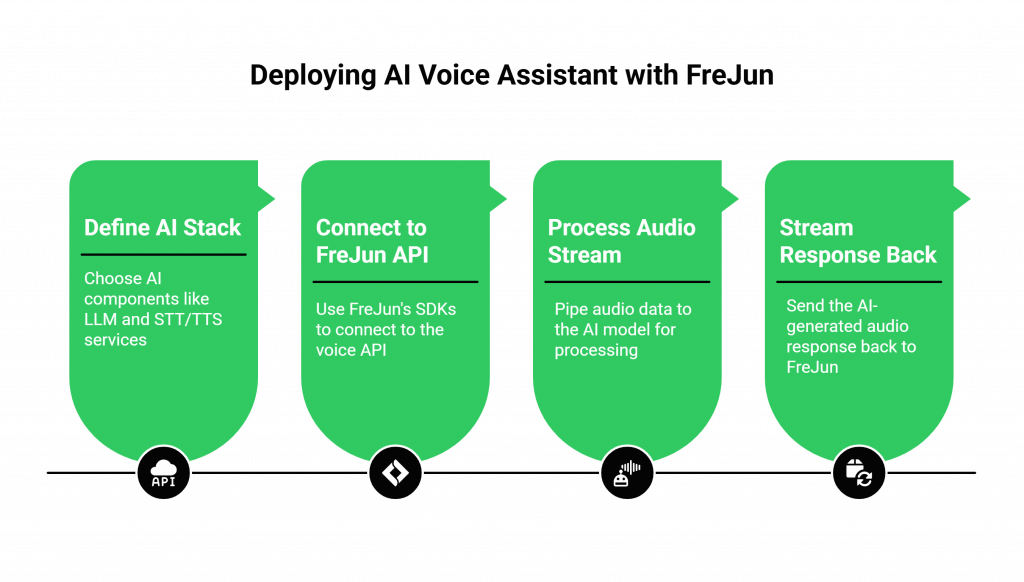
Step 1: Define and Configure Your AI Stack
First, choose the components for your AI Voice Assistant. This includes your core Large Language Model (e.g., OpenAI, Anthropic), your Speech-to-Text (STT) service, and your Text-to-Speech (TTS) service. For the most advanced experience, you can use a multimodal model like OpenAI’s Realtime API, which handles speech-to-speech conversion directly.
Because FreJun is model-agnostic, you have the complete freedom to select best-in-class services that fit your budget and use case.
Step 2: Connect Your Application to FreJun’s Voice API
This is where FreJun replaces months of complex infrastructure work. Instead of building your own connections to telephony carriers and managing raw media streams, you simply use FreJun’s developer-first SDKs.
With just a few lines of code, you can provision a phone number and instruct FreJun to begin streaming live call audio directly to your backend application endpoint.
Step 3: Process the Audio Stream with Your AI
Your application now receives a clear audio stream from the active call. You pipe this audio data directly into your chosen AI model. For example, if you are using a multimodal agent, you would pass the stream to the model for processing.
Step 4: Stream the Voice Response Back to the Caller
Once your AI generates an audio response, you simply pipe this new audio stream back to FreJun’s API. Our platform handles the immediate, low-latency delivery of the response to the user on the call, completing the conversational AI voice bot loop seamlessly.
That’s it. You have successfully deployed a real-time AI Voice Assistant without writing a single line of complex telephony infrastructure code.
Also Read: WhatsApp Chat Handling Strategies for Medium-Sized Enterprises
Final Thoughts: Move from Concept to Conversation with Confidence
The ability to deploy a powerful, conversational AI Voice Assistant is no longer limits to capabilities of AI models. The true bottleneck has shifted to the underlying voice infrastructure required to make these models work reliably in real world.
Building this infrastructure yourself is a costly, time-consuming distraction that pulls your focus away from your core mission: creating an intelligent and effective AI experience.
FreJun offers a clear strategic advantage. By abstracting away the immense complexity of real-time voice communication, we empower you to channel all resources into what you do best. You can experiment with different AI models, refine conversational scripts, and perfect your application’s logic, all with the confidence that the underlying voice layer is secure, scalable, and engineered for performance.
Don’t just build an AI prototype that works in a lab. Deploy a production-grade voice agent that can handle the demands of your business. The future of voice automation requires a brilliant “brain”, your AI, and a flawless “nervous system” to connect it to your customers. FreJun is that nervous system.
Start Your Journey with FreJun AI!
Frequently Asked Questions
No, and this is a key advantage of our platform. FreJun is a model-agnostic voice transport layer. We believe you should have the freedom and control to choose the best AI services for your specific needs.
Our entire platform is architected for speed. We use real-time media streaming protocols and have optimized every step of the process, from the connection with the telephone network to our API. This relentless focus on minimizing latency ensures that the conversation between the caller and your AI Voice Assistant feels fluid and natural.
Absolutely. Security and reliability are our top priorities. Our platform is built on resilient, geographically distributed infrastructure to guarantee high availability. We embed robust security protocols into every layer to ensure the integrity and confidentiality of your data, making it suitable for mission-critical enterprise applications.
Yes. Our infrastructure can handle both inbound and outbound call scenarios. You can deploy an AI Voice Assistant to act as an intelligent receptionist for incoming calls or to automate outbound campaigns for lead qualification, appointment reminders, and more.
To start, you will need an account with your chosen AI provider(s) (e.g., OpenAI, ElevenLabs) and a FreJun account. Our developer-first SDKs and comprehensive documentation make the integration process simple, allowing you to connect your AI logic to our voice API and get your agent talking in days, not months.