
Building reliable voice agents requires more than just connecting speech recognition and a language model – it demands rigorous testing for latency and quality. Delays of even a few hundred milliseconds or poor audio clarity can make conversations feel robotic instead of natural.
This blog explains how to test voice agents step by step, from measuring end-to-end latency to benchmarking audio quality under real-world network conditions.
For founders, product managers, and engineering leads exploring the top programmable voice AI APIs with low latency, this guide provides practical methods to evaluate and optimize performance.
What Latency Means in a Voice Agent
Latency is the time gap between a user finishing their sentence and the agent beginning to respond. While this sounds simple, latency is actually the sum of several smaller delays across the pipeline.
Breaking it down helps teams identify where the bottleneck lies:
| Stage | What Happens | Typical Range (Web) | Typical Range (Telephony) |
| STT | User audio is converted to text | 80–120 ms | 120–200 ms |
| LLM | Text is processed and response tokens are generated | 150–250 ms | 200–400 ms |
| TTS | Response text is converted into audio | 50–100 ms | 80–150 ms |
| Network Transport | Audio travels across WebRTC or PSTN | 80–150 ms | 400–600+ ms |
| End-to-End | Total delay experienced by user | 450–600 ms | 900–1200 ms |
For web-based calls, keeping end-to-end latency under 600 ms is ideal. For telephony and PSTN networks, sub-1000 ms is considered a good benchmark because of extra network hops.
In short: people expect conversations to flow. If an agent consistently takes more than a second to respond, it feels like waiting on hold. In human conversational research, propagation delays between 100 to 300 ms introduce slight hesitation, and delays beyond 300 ms cause speakers to back off – meaning the system must strive to stay well under these thresholds.
How to Measure Latency
The question most teams ask is: how do we actually calculate latency? The answer is by measuring the time between user input and agent output, both at the system level and at the human-perceived level.
Metrics to Track
- Time to First Word (TTFW) – The time between when the user stops speaking and when the first audio word of the agent is heard. This is the single most important metric because it defines the naturalness of turn-taking.
- Turn Latency – The total duration of one interaction cycle: user speech, processing, and agent response.
- Component Latency – The breakdown of delays in STT, LLM, and TTS separately. This is useful for troubleshooting.
- Percentiles (p90, p99) – Averages are misleading. Users remember the worst experiences. Tracking higher percentiles gives a more realistic view of what most people feel.
Methods of Measurement
A solid testing framework uses both internal logs and external observation:
- Timestamp Logging: Each system boundary should record when input arrives and when output is sent. For example, when the last audio frame enters STT and when the transcription is ready.
- End-to-End Audio Loopback: Play a short tone or phrase into the system and measure the time until the agent starts speaking. This gives the real “mouth-to-ear” delay.
- Distributed Tracing: Tag every request with a call ID so logs from STT, LLM, TTS, and the voice transport layer can be correlated later. This prevents blind spots in analysis.
When combined, these approaches help teams see both the technical latency inside the pipeline and the delay that end users actually notice.
What Quality Means in a Voice Conversation
Speed alone is not enough. Even if the system replies quickly, users will abandon the conversation if the audio sounds garbled or if the transcription misses key details. Quality testing ensures that the conversation is both intelligible and accurate.
Objective Measures
Engineers often rely on automated metrics to score audio quality:
- Mean Opinion Score (MOS): A scale from 1 (bad) to 5 (excellent). Automated MOS estimates can be calculated using algorithms such as POLQA or PESQ. The industry standard for voice quality benchmarking is POLQA (ITU-T P.863), which replaced PESQ to better account for wideband and time-varying impairments.
- Jitter: The variation in packet arrival times. High jitter leads to choppy audio.
- Packet Loss: Missing audio packets, often caused by unstable networks. Even a small percentage of loss can reduce clarity.
- Jitter Buffer Delay: Extra buffering added to smooth playback. This reduces stutter but increases latency.
Subjective Measures
Not everything can be measured with algorithms. Human perception still matters:
- Clarity of Speech: Does the voice sound natural or robotic?
- Barge-in Handling: Can the agent handle interruptions gracefully when the user speaks over it?
- Task Success Rate: Did the conversation achieve its intended goal, such as booking an appointment or answering a question?
Balancing objective metrics with real human testing is the only way to ensure reliability at scale.
Explore how Retrieval-Augmented Generation enhances context handling in voice agents for precise, real-time conversations in dynamic customer scenarios
Building a Testing Framework
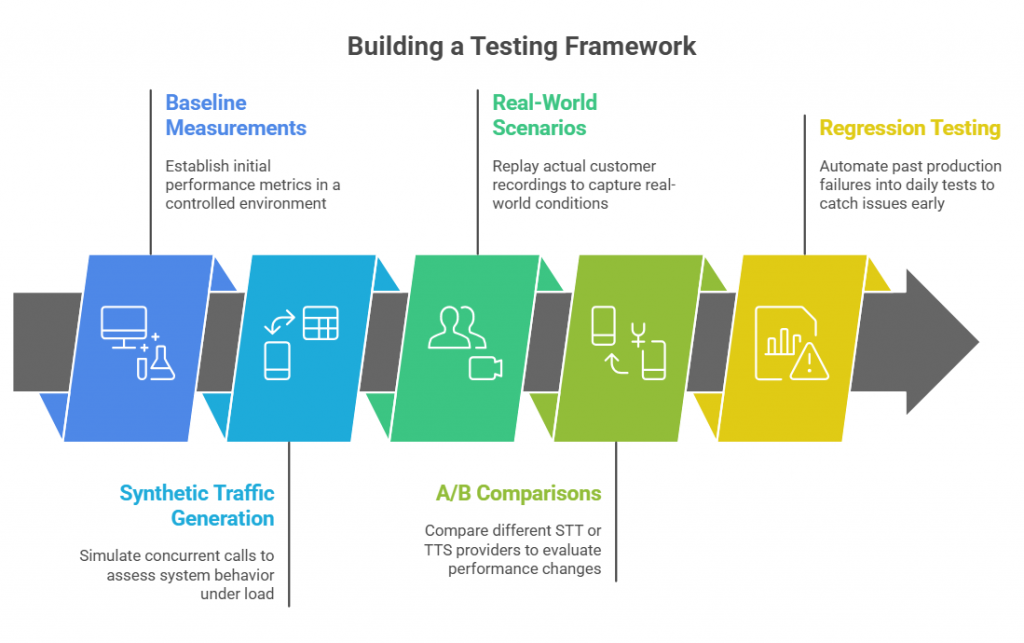
Testing latency and quality is not a one-time task. It requires a repeatable framework that can be applied in development, staging, and production environments.
Steps to Build the Framework
- Baseline Measurements: Start with a controlled lab setup. Use clean audio samples with different accents and speech rates. Measure all component latencies and MOS scores.
- Synthetic Traffic Generation: Simulate concurrent calls using tools like SIPp for telephony and WebRTC clients for browser-based testing. This shows how the system behaves under load.
- Real-World Scenarios: Replay actual customer recordings (with consent) to capture real noise conditions and conversational flows.
- A/B Comparisons: Swap out STT or TTS providers to see how latency and quality change while keeping the rest of the system constant.
- Regression Testing: Convert past production failures into automated tests. Run these daily to catch issues early.
This kind of structure turns testing from a manual exercise into a continuous assurance process.
Handling Real-World Network Conditions
One of the biggest reasons latency and quality fluctuate is network variability. A voice agent that works perfectly in the lab may stumble in real-world environments if the network is unstable.
Factors to test include:
- Telephony vs WebRTC: PSTN adds unavoidable extra hops. Always measure both channels.
- Codec Performance: Different codecs handle loss differently. G.711 is standard, Opus is more resilient, and G.722 offers higher fidelity.
- Jitter and Packet Loss: Introduce controlled packet drops during testing to see how the system adapts.
- Interruption Handling: Test barge-in scenarios where a user talks over the agent to check how quickly the system can stop TTS and restart STT.
By deliberately adding stress to the system, you build confidence that it will survive poor network conditions in production.
Learn proven methods to minimize call drop rates in AI-powered voice systems while maintaining seamless, natural conversations at scale.
Common Latency Killers
Even with careful design, some problems keep recurring across most implementations. Knowing these helps teams test and fix them early.
- Slow Endpointing in STT: Some STT engines take too long to decide when the user has finished speaking. Adjusting endpointing parameters or disabling extra formatting can speed this up.
- Large LLM Response Times: Bigger models often generate responses slowly. Limiting token count, keeping sessions warm, and placing servers closer to the media edge can reduce delay.
- TTS Buffering: If the system waits for the entire response before starting playback, users feel the lag. Streaming audio as soon as the first phonemes are ready improves responsiveness.
- Network Jitter: Unstable networks can force jitter buffers to expand, which adds milliseconds. Monitoring jitter buffer delay is essential.
- Codec Mismatches: Using the wrong codec for the environment can cause unnecessary delays. For example, Opus often outperforms G.711 in lossy networks.
Advanced Testing Strategies for Voice Agents
Once the basics of latency and quality testing are in place, the next step is to make the process scalable and reliable for continuous deployment. Voice agents are not static; their performance changes with new LLM updates, different TTS/STT providers, and evolving network conditions.
To handle this, organizations need structured advanced testing.
Multi-Phase Testing Approach
- Baseline and Benchmarking: Establish a clear baseline using lab conditions. Record end-to-end latency, MOS scores, and task completion rates. Use these as your reference points.
- A/B Provider Comparisons: Test multiple STT, LLM, and TTS providers in identical scenarios. Measure differences in latency, word error rate, and naturalness. This allows you to choose the optimal balance of cost, speed, and accuracy.
- Load and Scale Testing: Use SIPp or similar tools to simulate thousands of concurrent calls. Monitor p90 and p99 latency under load. This shows whether the system can handle peak usage without degradation.
- Network Stress Testing: Introduce jitter, packet loss, and codec mismatches deliberately. This validates whether the agent can maintain intelligibility and responsiveness in poor conditions.
- Regression Packs: Turn past failures into automated regression tests. For example, if a user’s address was transcribed incorrectly in production, create a test case for it. Run these daily or before each deployment.
- Real-World Canaries: Roll out new versions to a small percentage of traffic first. Compare key metrics (latency, MOS, task success) before full rollout.
This layered approach transforms testing from a one-off activity into an ongoing quality assurance pipeline.
Setting Service Level Objectives (SLOs)
Clear SLOs help teams define what “good enough” means. Without them, testing has no anchor and optimization never ends.
Latency SLOs
- Web-based calls (WebRTC, apps):
- p90 latency under 600 ms
- p99 latency under 900 ms
- p90 latency under 600 ms
- Telephony (PSTN, SIP):
- p90 latency under 1000 ms
- p99 latency under 1400 ms
- p90 latency under 1000 ms
Quality SLOs
- Mean Opinion Score (MOS) ≥ 3.8 on clean networks
- MOS ≥ 3.2 when up to 2% packet loss is introduced
- Word Error Rate (WER) ≤ 7% for standard names and numbers
- Interruption handling success ≥ 97%
- Tool-call or workflow completion success ≥ 99%
Operational SLOs
- No more than 0.1% of conversational turns should exceed 3 seconds
- Alert if p99 latency regresses by more than 100 ms after a deployment
By publishing these SLOs, teams create a measurable contract with stakeholders. Engineering can test against them, and product managers can confidently communicate expected performance to customers.
Where FreJun Teler Fits in Latency and Quality Testing
Most programmable voice platforms stop at basic telephony, offering APIs for calling but limiting how developers integrate AI components. This creates rigid pipelines where experimentation with different speech-to-text, language models, or text-to-speech engines is difficult.
FreJun Teler is built differently: it serves as a global voice infrastructure layer for AI agents. Teler handles real-time streaming of inbound and outbound calls across both WebRTC and PSTN, while developers retain full control over dialogue state and business logic. This separation makes testing more effective.
Teams can keep Teler constant as the voice layer and swap out AI components to directly compare latency and quality – whether evaluating two STT providers, testing lightweight versus large LLMs, or benchmarking different TTS voices. Engineered for low latency and stability, Teler reduces network variability and makes performance insights clearer. For teams seeking top programmable voice AI APIs with low latency, Teler is the voice API for developers.
Creating a Practical Testing Roadmap
Bringing together all the concepts, here is a step-by-step roadmap that teams can follow:
- Define Benchmarks
- Decide your latency and quality SLOs before testing begins.
- Decide your latency and quality SLOs before testing begins.
- Baseline Testing
- Run controlled lab tests with synthetic audio across clean networks.
- Run controlled lab tests with synthetic audio across clean networks.
- A/B Comparisons
- Swap out AI components (STT, LLM, TTS) and measure differences while keeping Teler constant.
- Swap out AI components (STT, LLM, TTS) and measure differences while keeping Teler constant.
- Network Stress Tests
- Introduce jitter, packet loss, and codec variations to see how the system behaves under strain.
- Introduce jitter, packet loss, and codec variations to see how the system behaves under strain.
- Load Testing
- Use SIPp and WebRTC clients to simulate peak concurrent calls.
- Use SIPp and WebRTC clients to simulate peak concurrent calls.
- Regression Testing
- Add real-world failure cases into automated test suites.
- Add real-world failure cases into automated test suites.
- Canary Rollouts
- Deploy changes to a small percentage of calls first. Compare metrics before full rollout.
- Deploy changes to a small percentage of calls first. Compare metrics before full rollout.
This roadmap ensures that latency and quality are tested across both ideal and adverse conditions, reducing surprises when scaling to thousands of users.
Conclusion
Latency and quality are the foundations of a successful voice agent. Achieving both requires more than surface-level checks – it demands a disciplined approach with baselines, percentile tracking, stress tests, and regression packs. By setting clear SLOs and testing systematically, product teams can release updates with confidence, knowing conversations will remain natural and reliable.
FreJun Teler makes this process easier by acting as the global voice infrastructure layer that keeps transport stable while allowing you to integrate any STT, LLM, or TTS of your choice. This flexibility ensures accurate benchmarking, faster optimization, and scalable deployments.
If you are looking for a voice API for developers built for low latency and enterprise reliability, schedule a demo with Teler today.
FAQs –
1. What is considered low latency for a voice AI agent?
Low latency for voice agents means under 600 ms on web and under 1000 ms on telephony, ensuring natural conversations.
2. How do you test voice quality in AI-powered calls?
Voice quality testing uses MOS scores, jitter and packet loss analysis, plus human evaluations for clarity, barge-in, and task success.
3. Why do percentile metrics like p90 and p99 matter in latency testing?
Percentiles show worst-case performance; p90 and p99 reveal delays users actually notice, unlike averages that often hide real experience.
4. Can developers integrate any AI model with a programmable voice API?
Yes. APIs like FreJun Teler let developers integrate any STT, LLM, or TTS while maintaining consistent low-latency voice transport.