
In 2025, businesses are investing heavily in voice AI, but the real challenge isn’t deciding whether to adopt it, it is choosing the right building blocks. Platforms like Superbryn.com and AssemblyAI highlight just how specialized the ecosystem has become. One is engineered for real-time responsiveness, the other for deep audio intelligence.
For product leaders, the decision isn’t simply about “which is better,” but how these platforms complement each other, and how FreJun completes the stack by enabling live, production-grade conversations.
Table of contents
- The Developer’s Infrastructure Gap: Beyond the API Call
- What is AssemblyAI? The Engine for Audio Intelligence
- What is Superbryn.com? The Framework for Real-Time Interaction
- Superbryn.com Vs Assemblyai.com: A Head-to-Head Functional Analysis
- The Missing Piece: Why Your AI Needs a Voice Transport Layer
- Building a Production-Grade Voice Agent: The 2025 Blueprint
- Comparison: The FreJun Advantage vs. DIY Voice Infrastructure
- Final Thoughts: Focus on Your AI’s Logic, Not Its Lungs
- Frequently Asked Questions (FAQ)
The Developer’s Infrastructure Gap: Beyond the API Call
For developers building the next generation of voice AI, the market is filled with powerful and highly specialized platforms. The ultimate goal is to create an AI agent that can listen, comprehend, and converse in real-time with human-like fluidity. This ambition leads developers to a critical evaluation of tools, each promising to unlock a new level of vocal sophistication.
However, a successful voice agent is not merely a combination of a speech-to-text (STT) API and a text-to-speech (TTS) API. The real challenge, the one that separates prototypes from production-grade applications, is the infrastructure connecting these AI services to a user on a live telephone call. This is the domain of telephony, real-time media streaming, and relentless latency optimization.
You may get the most accurate transcription and the fastest conversational AI, but jitter, awkward pauses, or garbled audio ruin the user experience and make the application fail. The debate over Superbryn.com Vs Assemblyai.com is crucial for defining your AI’s capabilities, but it only addresses part of the equation.
Developers must solve the entire voice pipeline, from the moment a user speaks into their phone to the second they hear the AI’s response. This requires looking beyond the AI models and focusing on the foundational transport layer that makes genuine conversation possible.
What is AssemblyAI? The Engine for Audio Intelligence
AssemblyAI has established itself as a mature and robust platform specializing in speech-to-text and deep audio intelligence. For developers, AssemblyAI serves as the powerful “ears” of their application, transforming raw, unstructured audio data into structured, analyzable text and valuable insights.
Its core strength lies in providing enterprise-grade transcription accuracy and scalability. But its true value for many businesses is its comprehensive suite of audio intelligence APIs. These tools allow applications to understand not just what was said, but the context, sentiment, and structure of the conversation.
Key capabilities offered by AssemblyAI include:
- High-Accuracy Transcription: The foundation of its offering, providing reliable speech-to-text conversion for enterprise use cases.
- Advanced Audio Intelligence: Features like summarization, topic detection, and sentiment analysis allow applications to automatically extract key insights from calls.
- Speaker Diarization: The ability to identify and differentiate between multiple speakers in a single audio file, which is critical for analyzing meetings, call center interactions, and interviews.
- Enterprise Scalability: Built to handle large volumes of audio data, making it a trusted choice for industries like healthcare, finance, and media analytics.
Developers select AssemblyAI when their primary objective is to process, understand, and extract deep insights from audio data. It is the definitive solution for building transcription services, compliance monitoring systems, and large-scale call analytics platforms.
Also Read: Vapi.ai Vs Assemblyai.com: Which AI Voice Platform Is Best for Your Next AI Voice Project
What is Superbryn.com? The Framework for Real-Time Interaction
AssemblyAI excels at analyzing audio, while Superbryn.com creates real-time voice experiences. Superbryn.com is an emerging AI voice platform designed for developers who are building interactive and conversational applications. Its architecture is fundamentally optimized for ultra-low latency streaming.
Superbryn.com provides a more holistic framework for live interaction, offering APIs for real-time speech synthesis, transcription, and voice dialogue management. It delivers speed and responsiveness, making it ideal for applications where live conversation drives the experience.
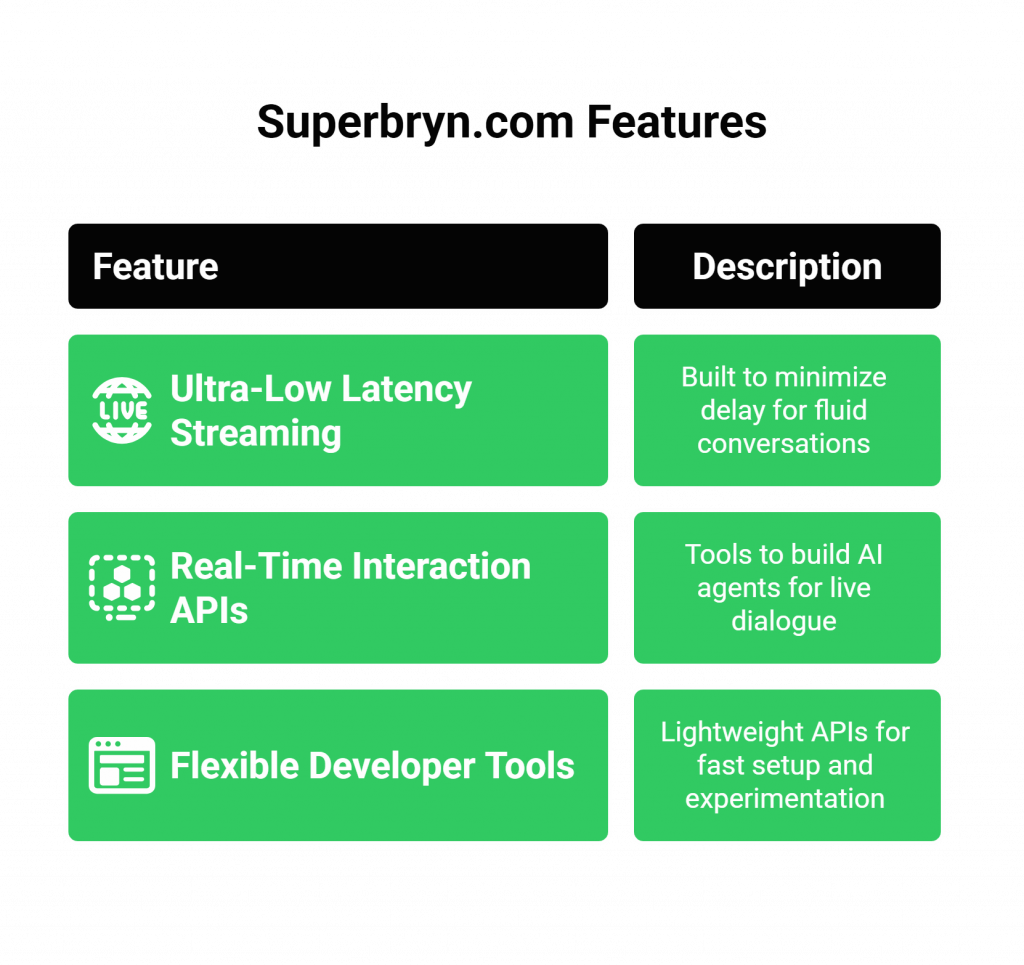
Key strengths of Superbryn.com include:
- Ultra-Low Latency Streaming: The platform minimizes the delay between user input and AI response, ensuring natural, fluid conversations.
- Real-Time Interaction APIs: It provides the tools necessary to build AI agents that can listen and speak in the same session, managing the flow of a live dialogue.
- Flexible Developer Tools: With lightweight APIs and a focus on fast setup, it empowers startups and innovative teams in sectors like gaming and interactive media to experiment and build quickly.
Developers choose Superbryn.com when their goal is to create an interactive, human-like agent that can converse in real time. It is perfect for building AI assistants, gaming characters, and other immersive experiences that require an immediate, live response.
Superbryn.com Vs Assemblyai.com: A Head-to-Head Functional Analysis
Placing Superbryn.com Vs Assemblyai.com in a direct comparison reveals that they are not competitors but rather specialized tools solving different problems for developers. The choice between them depends entirely on the application’s core requirement: deep analysis of recorded audio or live, real-time interaction.
Core Optimization
- AssemblyAI: Optimized for accuracy and analysis. Its infrastructure processes audio data and returns highly accurate transcriptions with rich metadata for post-processing..
- Superbryn.com: Optimized for speed and interactivity. Its infrastructure is built for low-latency, bidirectional streaming to facilitate a live, conversational experience.
Primary Use Cases
- AssemblyAI: Dominates in use cases where audio is processed for insights. This includes call center analytics, compliance monitoring for financial institutions, medical transcription, and media captioning.
- Superbryn.com: Excels in use cases where the AI is an active participant in a live conversation. This includes in-game NPCs, real-time AI customer service agents, and interactive mobile assistants.
Developer Focus
- A developer at an enterprise needing stable, scalable, and highly accurate transcription for analytics and compliance would choose AssemblyAI.
- A developer at a startup building an innovative, interactive voice-driven app would choose Superbryn.com.
The discussion of Superbryn.com Vs Assemblyai.com ultimately illustrates a key principle of modern AI development: you need the right tool for the right job. For a complete voice agent, you might even use both. But a critical question remains unanswered by either platform: how do you connect them to a phone call?
Also Read: Synthflow.ai Vs Deepgram.com: Which AI Voice Platform Is Best for Your Next AI Voice Project
The Missing Piece: Why Your AI Needs a Voice Transport Layer
You’ve made your choice in the Superbryn.com Vs Assemblyai.com debate. You have your AI’s brain and its voice. Now, how do you plug it into the global telephone network?
This is where the concept of a voice transport layer becomes paramount.
AI platforms are experts at processing data, but they are not telecommunication companies. They do not manage phone numbers, interface with global carriers, or handle the raw, real-time streaming of audio packets required for a stable phone call. Attempting to build this infrastructure yourself is a massive and distracting engineering challenge:
- Complex Telephony Integration: Navigating the arcane world of SIP trunks, PSTN gateways, and carrier negotiations.
- Real-Time Media Management: Capturing, encoding, and transmitting audio bi-directionally with sub-second latency.
- Global Scalability and Reliability: Building a fault-tolerant, geographically distributed network to handle thousands of concurrent calls.
- Security and Compliance: Ensuring every conversation is secure and compliant with data privacy regulations.
FreJun handle all the complex voice infrastructure so you can focus 100% on building your AI application. Our platform acts as the reliable, high-speed bridge between a user on a call and your AI services like AssemblyAI and Superbryn.com.
Building a Production-Grade Voice Agent: The 2025 Blueprint
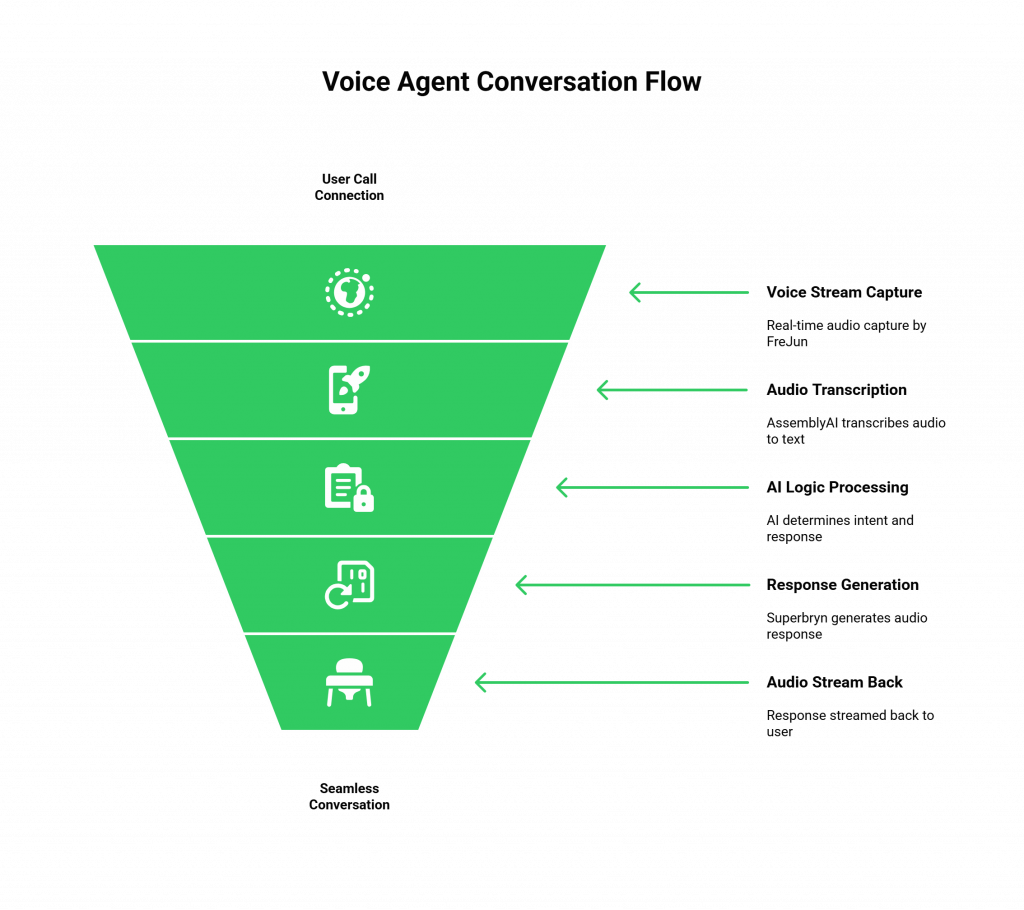
With a dedicated transport layer, the architecture of a sophisticated voice agent becomes clear and manageable. Here is a step-by-step blueprint of how these components work together seamlessly in a production environment, leveraging the best of the Superbryn.com Vs Assemblyai.com ecosystem.
- A Call is Connected via FreJun: A user calls one of your business phone numbers. FreJun’s enterprise-grade telephony infrastructure manages the call connection flawlessly.
- User’s Voice is Streamed in Real-Time: As the user speaks, FreJun’s API captures their voice. We stream this raw, low-latency audio directly to your application’s backend.
- AssemblyAI transcribes audio: Your backend receives the audio stream from FreJun and pipes it to the AssemblyAI API for highly accurate, real-time transcription.
- Your AI Logic Processes the Request: Your core AI logic (e.g., an LLM) receives the transcribed text, determines the user’s intent, and formulates an appropriate response.
- Superbryn.com Generates a Live Response: Your AI logic instructs Superbryn.com to generate a real-time audio response. Superbryn.com’s low-latency platform creates the natural-sounding audio instantly.
- Audio is Streamed Back to the User via FreJun: The generated audio from Superbryn.com is piped back to FreJun’s API. We stream this response back to the user on the call, completing the conversational loop with imperceptible delay.
This entire cycle happens in near real-time, creating a fluid and natural conversation. FreJun acts as the central hub, ensuring data flows between the user and your AI stack with the speed and clarity required for a seamless experience.
Also Read: Synthflow.ai Vs Play.ai: Which AI Voice Platform Is Best for Your Next AI Voice Project
Comparison: The FreJun Advantage vs. DIY Voice Infrastructure
For development teams considering building their own voice infrastructure, it is critical to understand the true cost in terms of time, money, and focus. This decision directly impacts your speed to market and the ultimate quality of your product.
| Feature | Building it Yourself (DIY Approach) | The FreJun Platform (Voice Transport Layer) |
| Time to Market | 6-12+ months of development to build a stable, scalable telephony integration. | Launch your voice agent in days. Our APIs and SDKs are designed for rapid integration, letting you go live immediately. |
| Infrastructure Cost | High upfront and ongoing costs for servers, carrier contracts, and dedicated DevOps personnel to manage the system. | A predictable, scalable, pay-as-you-go model with zero upfront capital expenditure on complex infrastructure. |
| Latency & Quality | A constant struggle to optimize the network stack and minimize latency. Call quality can be inconsistent and unreliable. | Architected for speed and clarity. Our entire stack is obsessively optimized for low-latency media streaming, ensuring natural conversations. |
| Scalability | Scaling to handle traffic spikes or thousands of concurrent calls requires significant, complex engineering effort. | Built on a resilient, geographically distributed infrastructure that scales automatically to meet your demand without any effort on your part. |
| Developer Focus | Your team’s valuable time is split between building your core AI product and managing complex telephony “plumbing.” | Your team focuses 100% on building unique AI features. We handle all the voice infrastructure complexity for you. |
| Support & Expertise | You are on your own. Troubleshooting issues with carriers, networks, or audio codecs is your responsibility. | Dedicated integration support from our team of experts, from pre-launch planning to post-launch optimization and guidance. |
Final Thoughts: Focus on Your AI’s Logic, Not Its Lungs
In 2025, the barrier to creating breakthrough voice AI is no longer the intelligence of the models, but the complexity of deploying them in real-world, real-time scenarios. The emergence of specialized platforms like Superbryn.com and AssemblyAI demonstrates the advanced state of these tools. But these powerful tools cannot function over a telephone network without a robust and specialized delivery mechanism.
The most successful developers focus their resources on what creates a competitive advantage: the intelligence of their AI, the quality of the user experience, and the speed at which they can innovate. Building and maintaining a global, low-latency telephony network is a complex, undifferentiated task that distracts from this core mission.
By choosing FreJun as your voice transport layer, you are making a strategic decision to accelerate your development, guarantee enterprise-grade performance, and future-proof your application. Let us handle the intricate challenges of voice infrastructure. You focus on what matters most: building the future of intelligent conversation.
Also Read: Virtual PBX Phone Systems Setup for Businesses in Mexico
Frequently Asked Questions (FAQ)
No, they serve different primary functions. AssemblyAI delivers highly accurate speech-to-text and audio analysis (input), while Superbryn.com powers real-time, low-latency conversational experiences (interaction/output).They are complementary tools in a modern voice AI stack.
No. FreJun is the voice transport layer, not an AI model provider. Our platform is model-agnostic and acts as the essential bridge that connects AI services like these to the global telephone network, enabling them to function in a live call environment.
Yes. FreJun’s API is designed for complete flexibility. You can integrate any speech-to-text, text-to-speech, or large language model provider you choose, allowing you to build a best-in-class voice stack without vendor lock-in.
The primary advantages are speed, reliability, and focus. FreJun abstracts away the enormous complexity of carrier management, real-time media streaming, and global infrastructure. This allows you to launch a production-grade voice agent in a fraction of the time, with guaranteed performance, and without needing a dedicated team of telecom engineers.