
The goal of creating a truly conversational AI, one that can listen, understand, and respond in real-time over a phone call, has moved from science fiction to a business imperative. Companies across the globe are racing to deploy sophisticated Chatbot Speech Recognition agents for everything, from 24/7 customer support to proactive outbound sales.
Table of Contents
- Table of Contents
- What is Chatbot Speech Recognition?
- The Real Challenge: Why Streaming Voice Infrastructure is the Hardest Part
- FreJun: The Transport Layer for Production-Grade Voice AI
- A Modern Workflow: How FreJun Connects Calls to Your AI
- DIY Infrastructure vs. FreJun’s Managed Platform: A Head-to-Head Comparison
- How to Build Your Voice Agent: A 5-Step Guide with FreJun
- Best Practices for a Flawless Conversational Experience
- Final Thoughts: Building the Future of Voice on a Solid Foundation
- Frequently Asked Questions (FAQ)
The core technology enabling this revolution is Chatbot Speech Recognition, a complex synergy of modules that transforms spoken words into intelligent action.
However, many development teams dive in, focusing exclusively on perfecting their AI models, the Speech-to-Text (STT), Natural Language Processing (NLP), and Text-to-Speech (TTS) components. They soon hit an unexpected and formidable wall: the infrastructure. The real-world challenge isn’t just about the AI’s intelligence; it’s about reliably getting voice data from a user on a phone call to the AI and back again, in milliseconds. This is where most voice AI projects falter, bogged down by the immense complexity of real-time voice transport.
What is Chatbot Speech Recognition?
At its heart, Chatbot Speech Recognition technology combines several components to create a seamless, interactive conversation. First, Automatic Speech Recognition (ASR) captures the user’s spoken audio and converts it into machine-readable text. This text is then fed to a Natural Language Processing (NLP) engine, often a Large Language Model (LLM), which interprets the user’s intent and formulates a response. Finally, a Text-to-Speech (TTS) service converts that text response back into audible speech for the user.
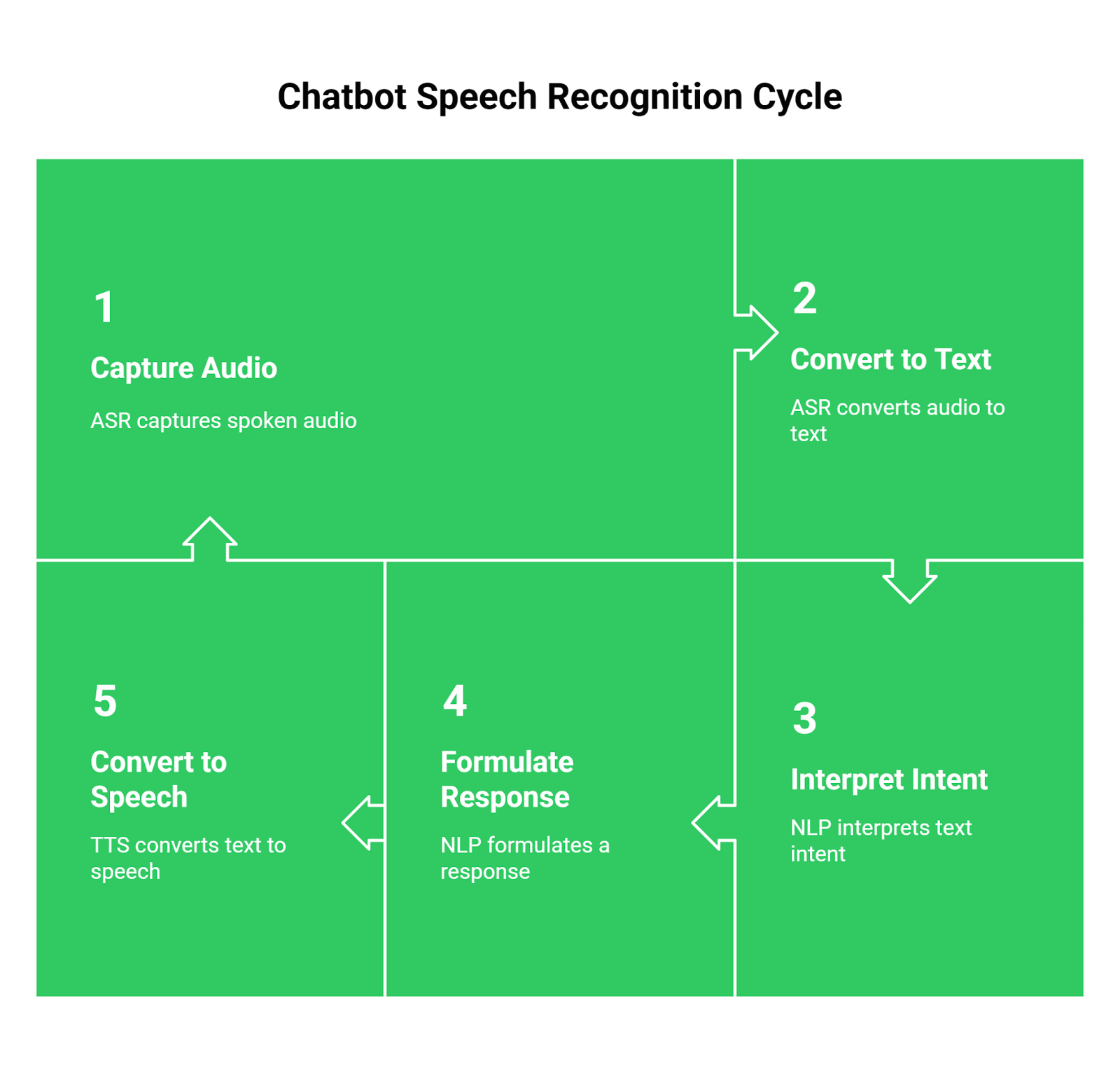
This technology is the engine behind the next generation of user interfaces, offering unparalleled accessibility and enabling hands-free, natural language interactions for customer support bots, virtual assistants, and smart devices.
The Real Challenge: Why Streaming Voice Infrastructure is the Hardest Part
While APIs for STT, NLP, and TTS are readily available from providers like Google, OpenAI, and Microsoft, they solve only one piece of the puzzle. These APIs are brilliant at processing data, but they don’t solve the problem of transporting that data from a live phone call.
Building this transport layer yourself means grappling with a host of complex, low-level challenges that have nothing to do with AI and everything to do with telephony and network engineering:
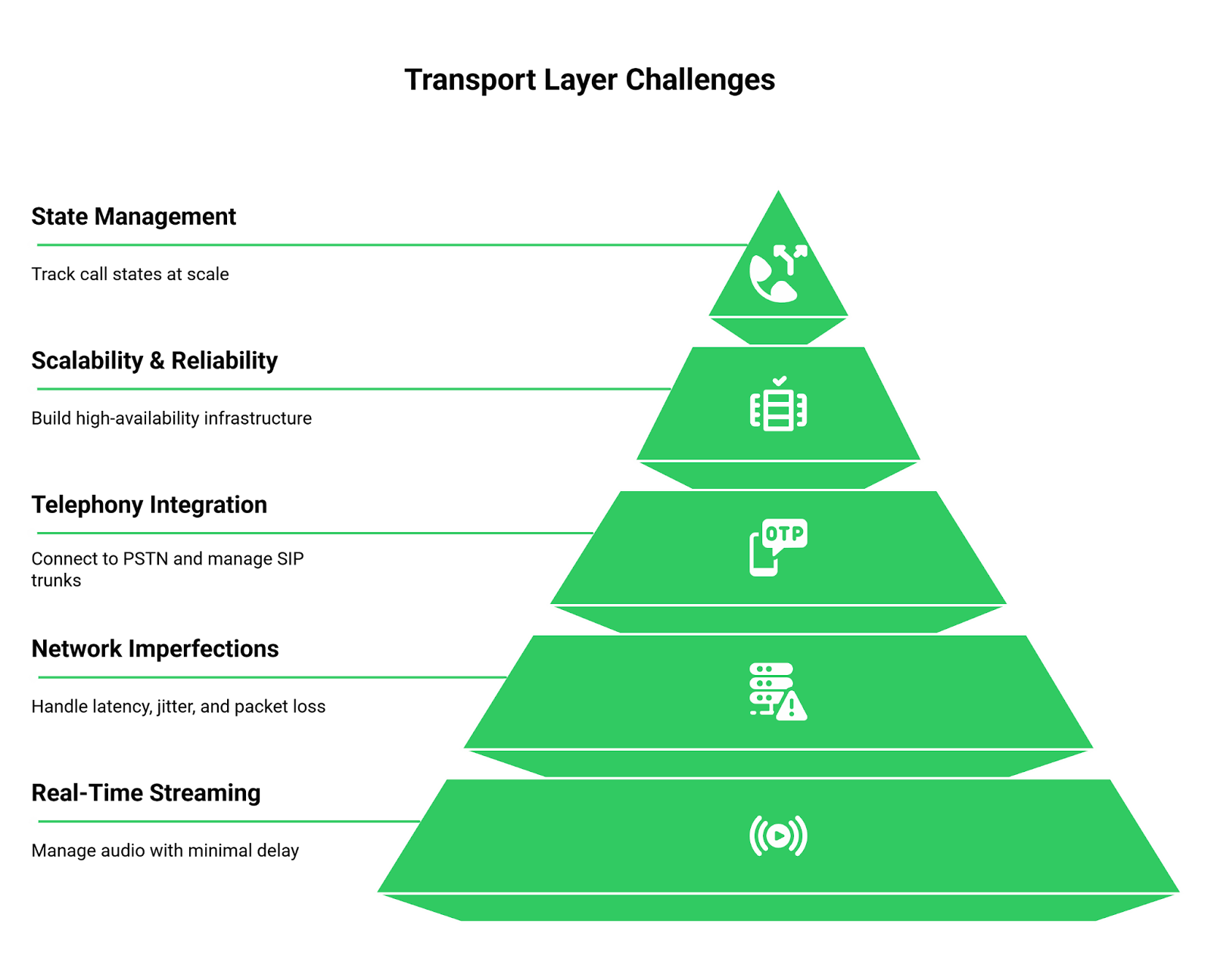
- Real-Time Media Streaming: You need to capture raw audio from a phone call (inbound or outbound) and stream it with minimal delay. This requires managing persistent, bi-directional connections like WebSockets or streaming HTTP/2.
- Latency, Jitter, and Packet Loss: A phone call is not a perfect data stream. You must build systems to handle network imperfections that can create awkward pauses, garbled audio, and a broken conversational flow.
- Telephony Integration: Connecting your application to the Public Switched Telephone Network (PSTN) is notoriously complex. It involves managing SIP trunks, phone number provisioning, and complying with regional telecom regulations.
- Scalability and Reliability: A prototype that works for one call will crumble under the pressure of hundreds or thousands of concurrent calls. Building a geographically distributed, high-availability infrastructure is a massive engineering undertaking.
- State Management: Your application needs to track the state of every single call, is it ringing, in progress, on hold, or completed? This becomes exponentially harder at scale.
Developers who attempt to build this “plumbing” themselves find their focus diverted from their core mission: creating a brilliant AI. They spend months wrestling with voice infrastructure instead of refining their Chatbot Speech Recognition logic.
FreJun: The Transport Layer for Production-Grade Voice AI
This is precisely the problem FreJun was built to solve. We handle the complex, messy, and mission-critical voice infrastructure so you can focus on what you do best: building your AI.
FreJun is not another STT or TTS provider. We are the model-agnostic, developer-first platform that serves as the reliable transport layer for your voice AI project. Our architecture is designed from the ground up for one purpose: to stream audio between a live phone call and your application with maximum speed and clarity.
Think of it this way: if your STT, LLM, and TTS services are the engine of your voice agent, FreJun is the chassis, transmission, and fuel system that makes it move. We provide the robust foundation that turns your text-based AI into a powerful, production-grade voice agent.
A Modern Workflow: How FreJun Connects Calls to Your AI
Integrating your AI with FreJun is designed to be straightforward, abstracting away the underlying telephony complexities. The end-to-end workflow is simple and gives you full control over your AI logic.
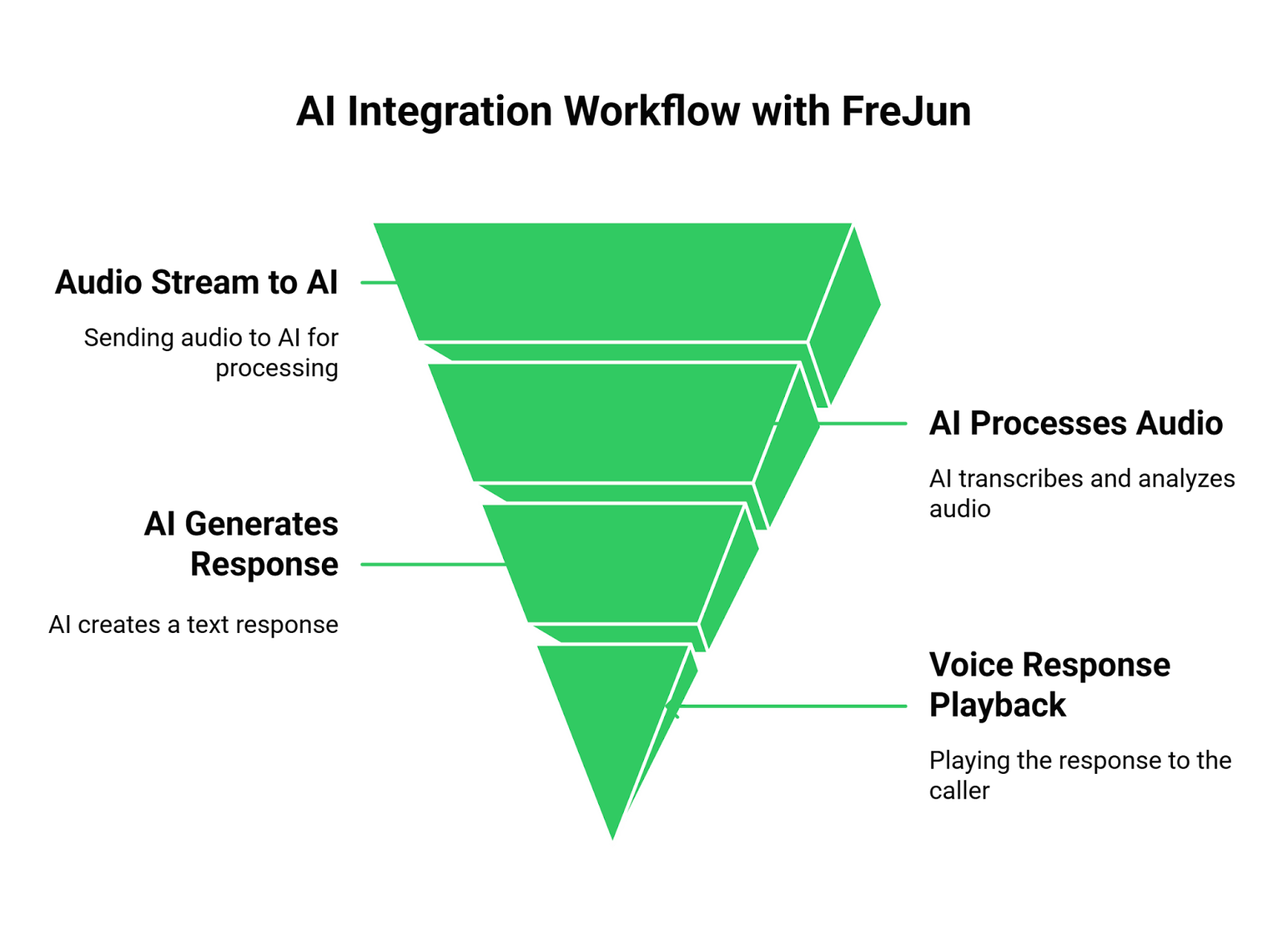
- Stream Voice Input: Our API captures real-time, low-latency audio from any inbound or outbound call. This raw audio stream is forwarded directly to your application’s designated endpoint, ensuring every word is captured clearly.
- Process with Your AI: Your application receives the audio stream from FreJun. From here, you are in complete control. You pipe this audio to your chosen STT service (like Google Speech-to-Text or AssemblyAI) to get a transcription. You then pass this text to your NLP or LLM to generate a response. FreJun acts as the stable connection, reliably managing the call’s state while your backend manages the conversational context.
- Generate Voice Response: Once your AI generates a text response, you send it to your chosen TTS service. You then pipe the resulting audio output back to the FreJun API, which plays it back to the user over the call with minimal latency, completing the conversational loop.
This process allows for a powerful and flexible Chatbot Speech Recognition implementation, where you can swap out STT, LLM, or TTS providers without ever having to touch your voice infrastructure.
DIY Infrastructure vs. FreJun’s Managed Platform: A Head-to-Head Comparison
| Feature | The DIY Approach | The FreJun Platform |
| Infrastructure Management | You build, manage, and scale your own voice servers, SIP trunks, and network protocols. | Fully managed. FreJun handles all telephony, streaming, and server infrastructure. |
| Latency Optimization | You are responsible for optimizing the entire stack to minimize audio delays. | Our entire stack is engineered for low-latency, real-time media streaming. |
| Scalability & Reliability | Scaling to handle high call volumes requires significant engineering and cost. | Built on resilient, geographically distributed infrastructure for guaranteed uptime. |
| Development Time | Months, often spent on non-core infrastructure challenges. | Days. Launch a sophisticated voice agent in a fraction of the time. |
| Focus | Divided between building voice infrastructure and building the AI. | 100% focused on your AI logic, context management, and user experience. |
| Telephony Integration | You manage complex PSTN connectivity, number porting, and compliance. | Seamless integration. We handle number provisioning and regulatory compliance. |
Key Takeaway
Building a production-grade voice AI is a two-part problem: the AI and the infrastructure. Attempting to solve both is inefficient and costly. The most effective strategy is to use a specialized platform like FreJun to handle the voice transport layer. This allows you to focus your resources on your core competency, the AI, and get to market faster with a more reliable and scalable product. A successful Chatbot Speech Recognition system depends on this clear division of focus.
How to Build Your Voice Agent: A 5-Step Guide with FreJun
This practical guide demonstrates how to architect a real-time voice agent using FreJun’s infrastructure and your preferred AI services.
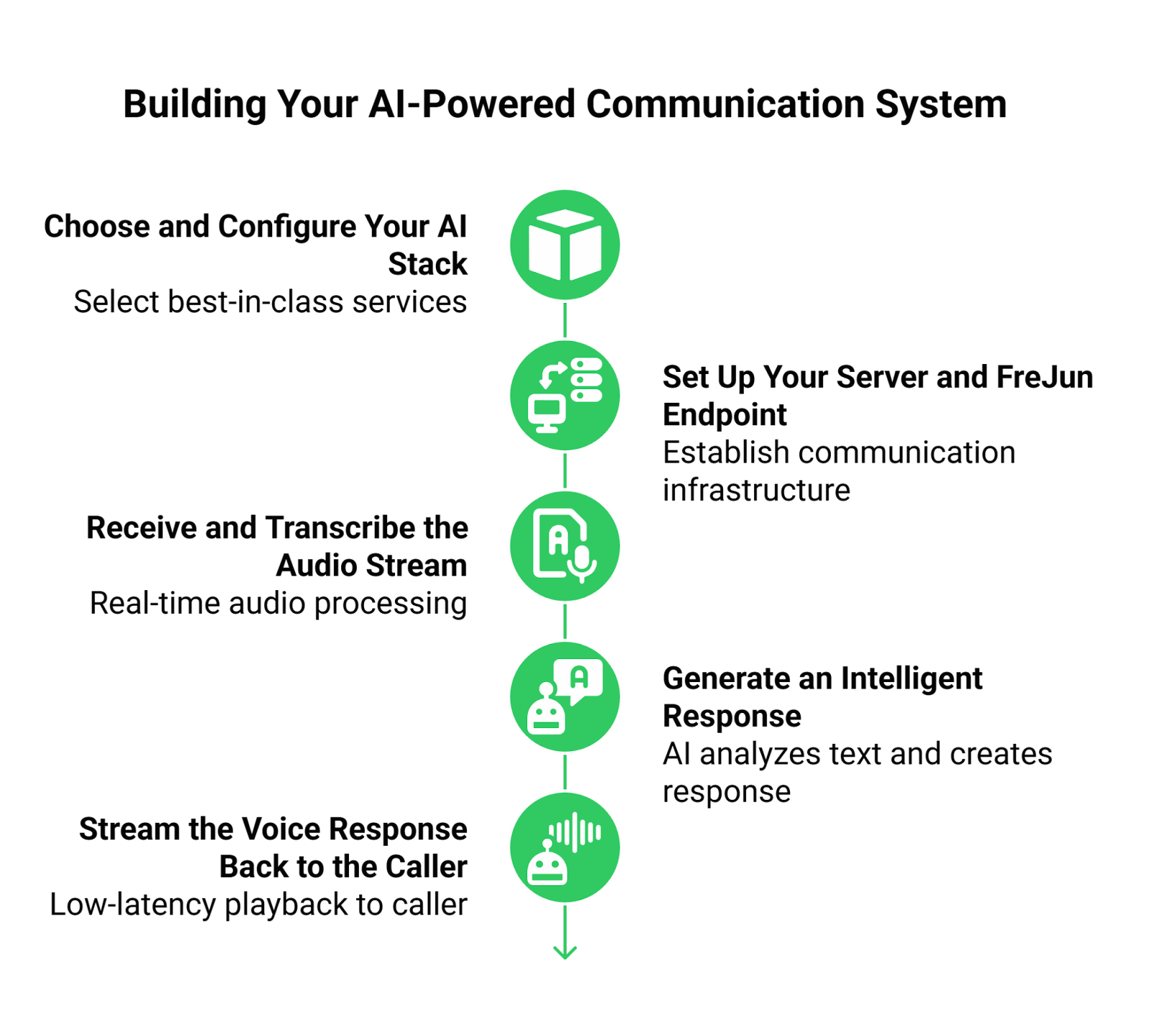
Step 1: Choose and Configure Your AI Stack
Select the best-in-class services for your needs. This is your “bring your own AI” stack.
- For Speech-to-Text (STT): Google Cloud Speech-to-Text, AssemblyAI, or Microsoft Azure.
- For Chatbot Logic (LLM/NLP): OpenAI, Anthropic, or a custom in-house model.
- For Text-to-Speech (TTS): ElevenLabs, Play.ht, or OpenAI’s TTS.
Step 2: Set Up Your Server and FreJun Endpoint
Your server will be the brain of the operation. Using technologies like Node.js or Python, you’ll set up an endpoint (often a WebSocket server) to communicate with FreJun. In your FreJun dashboard, you simply point your FreJun virtual number to this endpoint.
Step 3: Receive and Transcribe the Audio Stream
When a call comes in, FreJun establishes a connection and begins streaming the caller’s raw audio to your server. Your code receives this audio and immediately pipes it to your chosen STT provider’s streaming API. The STT service will send back transcripts in real-time.
Step 4: Generate an Intelligent Response
As you receive the finalized transcript from the STT service, you send this text to your chatbot or LLM. The AI analyzes the text, understands the intent, and generates the appropriate response. This is where the magic of your unique Chatbot Speech Recognition logic shines.
Step 5: Stream the Voice Response Back to the Caller
Take the text response from your AI and send it to your TTS API to synthesize voice audio. As you receive the audio from the TTS service, you stream it directly back to FreJun through our API. We handle the low-latency playback to the caller, ensuring the conversation flows naturally without awkward pauses.
Best Practices for a Flawless Conversational Experience
Once FreJun handles the infrastructure, you can fine-tune the user experience. Here are some best practices to consider for your AI application:

- Provide Real-Time Feedback: Use the partial transcripts from your STT service to provide user feedback, like a “thinking” indicator, to manage expectations and show the system is listening.
- Handle Interruptions Gracefully: Design your system so a user can interrupt the bot’s response. FreJun’s bi-directional streaming makes this possible, allowing you to stop the outgoing audio and immediately process the new incoming speech.
- Design for Imperfection: The real world is noisy. Your system should be designed to handle background noise, different accents, and out-of-vocabulary words gracefully, perhaps with fallback responses like “I’m sorry, I didn’t quite catch that.”
- Ensure Data Privacy: Voice data is sensitive. Ensure your application handles data securely, uses encryption, and complies with all relevant data protection regulations like GDPR.
Final Thoughts: Building the Future of Voice on a Solid Foundation
The field of voice AI is advancing at an incredible pace. We are seeing the rise of hyper-personalized bots that adapt to a user’s speaking style, multimodal AI that can understand voice and images simultaneously, and real-time translation that breaks down language barriers.
To capitalize on these future trends, you need a technical foundation that is robust, scalable, and flexible. By trying to build your own voice infrastructure, you risk creating a brittle system that is difficult to maintain and impossible to scale. You divert precious resources away from innovation and toward maintenance.
Choosing FreJun is a strategic decision to build on solid ground. We provide the enterprise-grade infrastructure that frees you to build the best possible Chatbot Speech Recognition experience. While you perfect your AI’s conversational skills, we ensure every word is delivered with speed and clarity. In the race to build the future of voice, the smartest teams aren’t the ones who build everything themselves, they are the ones who build on a platform designed for success.
Further Reading – AI for Sales: Best Tools, Strategies & Benefits
Frequently Asked Questions (FAQ)
No. FreJun is a voice transport platform. We provide the critical infrastructure to stream audio from a phone call to your application in real-time. You bring your own STT, chatbot, and TTS services, giving you full control and flexibility over your AI stack.
You can use any AI model or platform. Our API is model-agnostic, meaning it can connect to any AI chatbot, Large Language Model (LLM), or custom-built NLP engine.
Our entire platform is engineered for low-latency conversations. We use real-time media streaming at our core and have optimized every component, from call capture to audio playback, to minimize delays and eliminate the awkward pauses that break conversational flow.
A streaming STT API only transcribes an audio stream you provide. It does not solve the problem of getting that audio from a live phone call in the first place. FreJun handles the entire telephony layer: provisioning phone numbers, managing calls on the PSTN network, handling thousands of concurrent connections, and streaming the audio to you reliably.
With FreJun, it’s simple. You configure your FreJun number to point to your server’s endpoint. When a call is active, our API automatically captures the audio and streams it to you via a persistent connection like a WebSocket. You don’t have to build any of the underlying telephony or streaming logic yourself.