
Everyone wants to build voice AI. While fewer realize how quickly it turns into an infrastructure nightmare. At first, it seems straightforward: plug in a speech-to-text API, run it through your AI model, generate a response, and push it to text-to-speech. Done, right? Not quite.
The real challenge isn’t the intelligence of your bot, it is getting that intelligence to work over a live phone call, in real time, without latency, audio glitches, or dropped connections. That means building and maintaining a real-time voice transport layer, something even experienced teams underestimate.
Table of contents
- Why Building Voice AI from Scratch Is an Infrastructure Nightmare
- The Hidden Complexity of the Voice Transport Layer
- FreJun: The Infrastructure Layer for Production-Grade Voice AI
- How Does FreJun Simplifies Voice Chat Bot Integration?
- DIY vs. FreJun: A Head-to-Head Comparison
- A Practical Guide to Integrating Your AI with FreJun’s Voice Layer
- Best Practices for a Flawless Voice Agent Experience
- Final Thoughts: Focus on Your AI, Not Your Plumbing
- Frequently Asked Questions
FreJun AI exists to solve exactly this problem. We handle the messy, low-level engineering that makes voice AI work at scale: capturing and streaming audio, managing telephony, and ensuring sub-second latency from user speech to AI response. You bring the AI, we handle the call.
This guide will show you why voice infrastructure is the missing piece in most bot stacks, and how FreJun lets your team ship production-grade voice agents in days, not months.
Why Building Voice AI from Scratch Is an Infrastructure Nightmare
Every forward-thinking business recognizes the potential of voice AI. The goal is clear: create intelligent, responsive voice agents that can handle customer queries, automate outbound campaigns, and provide a seamless, human-like conversational experience. The allure lies in the sophistication of the AI, the Large Language Model (LLM) that understands context, the nuance of the dialogue, and the speed of the response.
However, a critical and often underestimated challenge lurks beneath the surface. Before your brilliant AI can utter a single word, you must solve the daunting engineering problem of real-time voice communication. This involves capturing audio from a live phone call, streaming it for processing, and returning a spoken response, all with near-zero latency.
Building this complex voice infrastructure from the ground up is not just difficult; it’s a resource-draining detour that diverts your focus from what truly matters: the intelligence of your bot.
The Hidden Complexity of the Voice Transport Layer
Many development teams embark on their Voice Chat Bot Integration journey by attempting to stitch together a patchwork of disparate services. They source a Speech-to-Text (STT) provider, a Text-to-Speech (TTS) service, and perhaps a separate API for managing the call itself. While this approach seems plausible in theory, it quickly unravels in practice.

The core problem is that these components were never designed to work together in a low-latency, conversational loop. The result is a clunky, unreliable system plagued by issues that are fatal to a good user experience:
- Awkward Pauses: The delay between the user finishing their sentence, your AI processing the text, and the audio response playing back creates jarring silence that breaks the flow of conversation.
- Poor Audio Quality: Jitter, packet loss, and poor encoding can lead to garbled audio, causing the STT engine to produce inaccurate transcriptions and derailing the entire dialogue.
- Scalability Nightmares: A system cobbled together for a single demo call will buckle under the pressure of hundreds or thousands of concurrent calls. Managing this scale requires a robust, geographically distributed infrastructure.
- Complex State Management: Maintaining the context of a conversation over a fragile connection is a significant challenge. If the transport layer is unreliable, your AI loses its place, and the user is forced to repeat themselves.
This DIY approach forces your best engineers to become telecom experts, spending valuable time managing complex media streams and troubleshooting call connectivity instead of refining your AI’s logic and performance.
FreJun: The Infrastructure Layer for Production-Grade Voice AI
This is precisely the problem FreJun was built to solve. We believe that building powerful voice agents should be about the AI, not the plumbing. FreJun provides a robust, developer-first voice infrastructure that handles all the complexities of real-time communication, allowing you to focus exclusively on building your bot’s intelligence.
We design our architecture with one primary purpose: to serve as a high-speed, high-clarity transport layer that connects your end-user to your AI. We manage the messy, complicated world of telephony so you don’t have to. With FreJun, you bring your own AI, be it from OpenAI, Rasa, or a custom-built model, and we provide the reliable pathway for it to listen and speak.
By abstracting away the voice layer, FreJun accelerates your time-to-market from months to days. You can bypass the entire infrastructure build-out and plug your existing text-based AI directly into our platform to create a production-grade voice agent.
How Does FreJun Simplifies Voice Chat Bot Integration?
FreJun’s platform is engineered to create a seamless, low-latency conversational loop. The process is elegant in its simplicity, with our infrastructure handling the heavy lifting at every stage.
- Stream Voice Input in Real-Time: When a call is initiated whether inbound or outbound, FreJun’s API captures the user’s voice. Our real-time media streaming technology captures every word with crystal clarity and sends it to your backend with minimal delay. This raw audio stream is ready to be fed into your STT service of choice.
- Process with Your AI (Full Control): This is where you work your magic. FreJun acts as a stable transport layer, reliably delivering the audio data. Your application receives the audio, transcribes it using your preferred STT engine, and sends the resulting text to your LLM or conversational AI. You maintain complete control over the dialogue state and context management.
- Generate Voice Response Instantly: Once your AI generates a text response, you pipe it through your chosen TTS service. You then send the resulting audio response back to the FreJun API, which plays it back to the user over the call with exceptionally low latency. This closes the conversational loop, creating a fluid and natural interaction.
This streamlined workflow is the essence of a successful Voice Chat Bot Integration, and FreJun perfects it by optimizing the entire stack for speed and reliability.
DIY vs. FreJun: A Head-to-Head Comparison
When considering how to empower your AI with voice, the choice of infrastructure has profound implications for development time, cost, and final user experience. Here’s how the traditional DIY approach stacks up against FreJun’s specialized platform.
| Feature | DIY (Do-It-Yourself) Approach | FreJun’s Voice Infrastructure |
| Core Focus | Engineers spend time on telecom infrastructure, media servers, and latency issues. | Engineers focus 100% on AI logic, conversation design, and business value. |
| Latency | High and unpredictable. Stitching together multiple APIs creates significant delays. | Ultra-low latency. The entire stack is optimized for real-time conversational flow. |
| Scalability | Difficult and expensive. Requires manual provisioning and management of servers. | Built for enterprise scale with geographically distributed, high-availability infrastructure. |
| Development Time | Months. Involves complex integration of STT, TTS, and separate call management APIs. | Days. A single, robust API and developer-first SDKs accelerate the entire process. |
| Reliability | Prone to connection drops, jitter, and packet loss, leading to a poor user experience. | Guaranteed uptime and reliability, ensuring your voice agents are always online. |
| AI Control | Full control, but the developer is responsible for the entire, fragile tech stack. | Full control over your AI model. FreJun is model-agnostic and handles only the voice layer. |
| Support | No dedicated support. You are responsible for troubleshooting every component. | Dedicated integration support from pre-planning to post-launch optimization. |
A Practical Guide to Integrating Your AI with FreJun’s Voice Layer
Moving from a text-based chatbot to a fully functional voice agent is remarkably straightforward with FreJun. Our developer-first SDKs and clear API structure make the Voice Chat Bot Integration process intuitive.
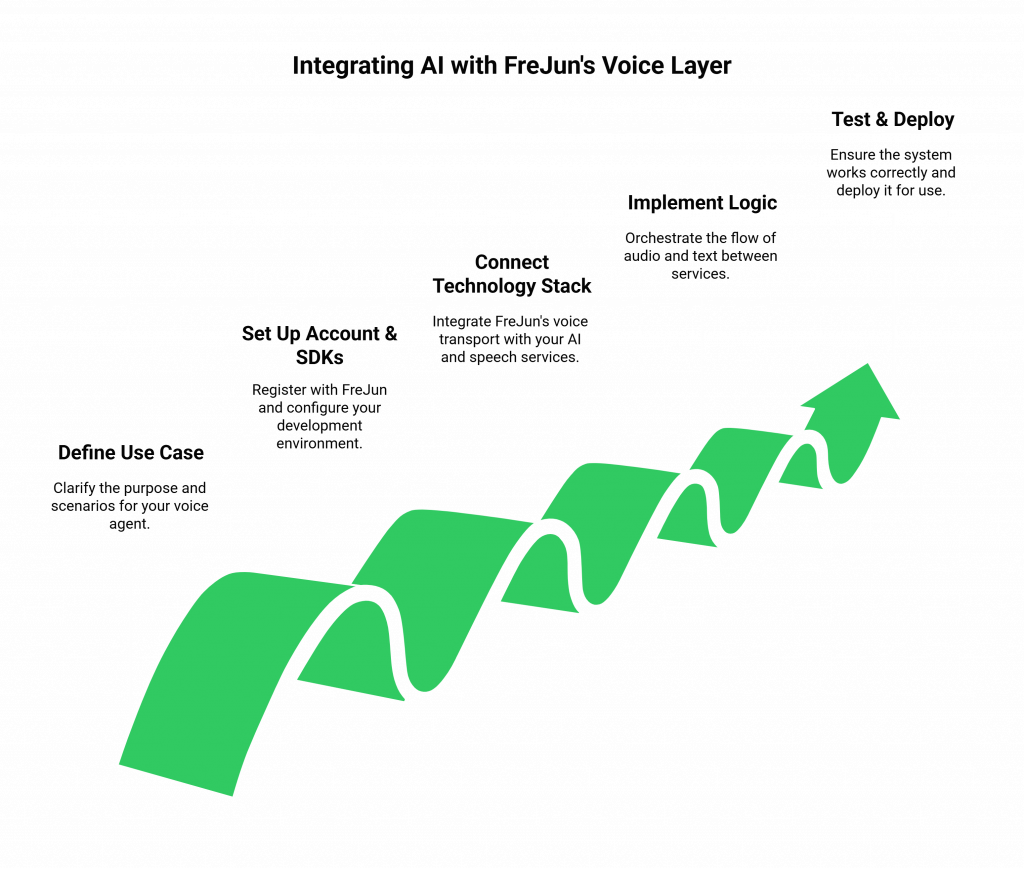
Step 1: Define Your Use Case and Platform
First, clarify the primary goal of your voice agent. Is it an AI-powered receptionist for inbound calls, an outbound agent for lead qualification, or a 24/7 customer support bot? Define the key scenarios and user intents it needs to handle. FreJun’s platform is flexible, allowing you to embed voice capabilities into web applications, mobile apps, or simply manage call logic on your backend for traditional phone calls.
Step 2: Set Up Your FreJun Account and SDKs
Sign up for FreJun and get your API keys. Using our comprehensive client-side and server-side SDKs, you can quickly set up your development environment. Our documentation provides clear examples for Node.js, Python, and other popular languages, helping you establish a connection to our platform in minutes.
Step 3: Connect Your Core Technology Stack
This is where the “Bring Your Own AI” philosophy comes to life. Your backend application will be the central hub that coordinates three key services:
- FreJun’s Voice Transport: To handle the real-time audio streaming from and to the user.
- Your STT Service: (e.g., Deepgram, Google Speech-to-Text). You will stream the audio from FreJun to this service for transcription.
- Your AI/LLM Engine: (e.g., OpenAI, Rasa, a custom model). The transcribed text is sent here for processing.
- Your TTS Service: (e.g., Cartesia, Amazon Polly). The text response from your AI is converted back into audio here.
Step 4: Implement the Conversational Logic
Your backend application orchestrates the flow:
- Receive the inbound audio stream from the FreJun API.
- Forward this stream to your STT service.
- Receive the transcribed text.
- Send the text to your AI engine, along with any relevant context from the ongoing conversation.
- Receive the text response from your AI.
- Send this response to your TTS service to generate audio.
- Stream the response audio back to the FreJun API to be played to the user.
FreJun’s stable connection ensures this entire loop completes with minimal delay, preserving the natural rhythm of a human conversation. The powerful Voice Chat Bot Integration is achieved by letting each component do what it does best.
Step 5: Test, Deploy, and Monitor
Thoroughly test the end-to-end flow. Check for transcription accuracy, response relevance, and audio clarity. Use FreJun’s robust infrastructure to deploy your voice agent with confidence. Once live, you can monitor performance and iterate on your AI’s conversational design, knowing the underlying voice transport is secure, reliable, and scalable.
Best Practices for a Flawless Voice Agent Experience
A successful voice bot is more than just functional, it is engaging and feels natural. Here are some best practices to keep in mind:
- Design for Conversation, Not Commands: Avoid rigid, robotic scripts. Your dialogue flows should be flexible, allowing users to speak naturally. Design clear fallback strategies for when your AI doesn’t understand a request.
- Optimize for Speed: The single biggest factor in a positive voice experience is low latency. Choosing a platform like FreJun, which is engineered from the ground up for speed, is the most critical decision you can make. This eliminates the awkward pauses that kill conversational flow.
- Maintain Context: Your application must track the conversational context independently. FreJun provides the reliable channel needed to do this effectively, ensuring the connection remains stable while your backend manages the dialogue state.
- Prioritize Security: Voice data is sensitive. FreJun is built with security by design, employing robust protocols to ensure the integrity and confidentiality of all data passing through our platform.
Final Thoughts: Focus on Your AI, Not Your Plumbing
The future of customer interaction is in voice, but the path to deploying effective voice AI is paved with infrastructure challenges. Attempting a DIY Voice Chat Bot Integration forces your team to solve complex real-time communication problems that have already been perfected by specialists.
FreJun offers a strategic shortcut. By providing an enterprise-grade voice transport layer, we empower you to pour all your energy, talent, and resources into what makes your solution unique: the intelligence and personality of your AI. You can create sophisticated, human-like voice agents that scale effortlessly, without ever having to worry about the underlying plumbing.
Also Read: PBX vs VoIP: Understanding Modern Business Phone Systems
Frequently Asked Questions
No. FreJun is model-agnostic and serves as the voice infrastructure layer. You bring your own AI, whether it’s from a provider like OpenAI, an open-source framework like Rasa, or a custom model built in-house. This gives you complete control over your bot’s logic and intelligence.
Yes. FreJun is a voice transport platform. We provide the real-time, low-latency audio stream from the call. You then send this stream to your chosen STT service for transcription. Similarly, you use your preferred TTS service to convert your AI’s text response back into audio, which you then stream back to our API for playback.
The primary advantages are speed, reliability, and focus. Building and maintaining a low-latency, scalable voice infrastructure is incredibly complex and resource-intensive. FreJun has already solved this problem. By using our platform, you can launch a production-grade voice agent in days instead of months and focus your engineering efforts on your core AI product, not on telephony.
Our entire technology stack is engineered for speed. We use real-time media streaming protocols and have optimized every component to minimize the delay between the user speaking, your AI processing the request, and the voice response being delivered. This eliminates the awkward pauses common in less optimized systems.
Absolutely. FreJun provides comprehensive client-side and server-side SDKs that make it easy to embed voice capabilities directly into your web and mobile applications, as well as manage call logic on your backend.