
As users demand more natural and efficient interactions, traditional app interfaces are no longer enough. Typing, navigating menus, or waiting for responses slows workflows and reduces engagement. Modern voice-enabled systems, powered by local LLM voice assistants and advanced recognition SDKs, allow developers to create applications that feel human-like, responsive, and contextually aware. By leveraging edge execution and reliable VoIP network solutions, apps can deliver low-latency, multi-turn conversations without compromising privacy or performance.
This article explores how smarter voice SDKs and voice agents enhance user experience, reduce friction, and enable scalable, real-time conversational applications.
Why Are Traditional App Interfaces No Longer Enough For Modern Users?
Modern applications are powerful, yet user interaction is often the weakest link. While features continue to grow, the way users interact with apps has barely evolved. Touch-based navigation, text inputs, and layered menus still dominate. However, these methods introduce friction, especially when speed, accessibility, or multitasking matters.
By 2025, the number of voice assistants deployed globally is estimated at 8.4 billion devices, surpassing the human population – underscoring the ubiquity of voice‑driven interaction points across mobile, wearable, and connected device ecosystems.
As a result, users expect faster and more natural interactions. They want to speak, not search. They want responses, not workflows. This is where voice enters the picture again – but this time with far more intelligence behind it.
Voice interfaces are no longer limited to basic commands. Instead, they are becoming conversational. Because of this shift, the question is no longer whether voice improves experience, but how well it is implemented.
What Is A Voice Recognition SDK, And Why Is It More Than Just Speech-To-Text?
At a basic level, a voice recognition SDK converts spoken audio into text. However, that definition is no longer sufficient. In modern applications, a voice recognition SDK acts as the entry point of a real-time conversational system.
A smarter voice recognition SDK typically handles:
- Real-time audio capture from microphones or calls
- Streaming audio instead of batch uploads
- Noise handling and voice activity detection
- Partial and final transcription delivery
- Low-latency handoff to downstream systems
Because of this, speech-to-text is only one part of the process. What matters more is how fast, how continuously, and how reliably audio is processed.
In other words, recognition without context is not useful. Recognition without speed breaks conversations. Therefore, smarter SDKs focus on streaming, timing, and stability, not just accuracy scores.
How Does A Smarter Voice SDK Improve App Experience?
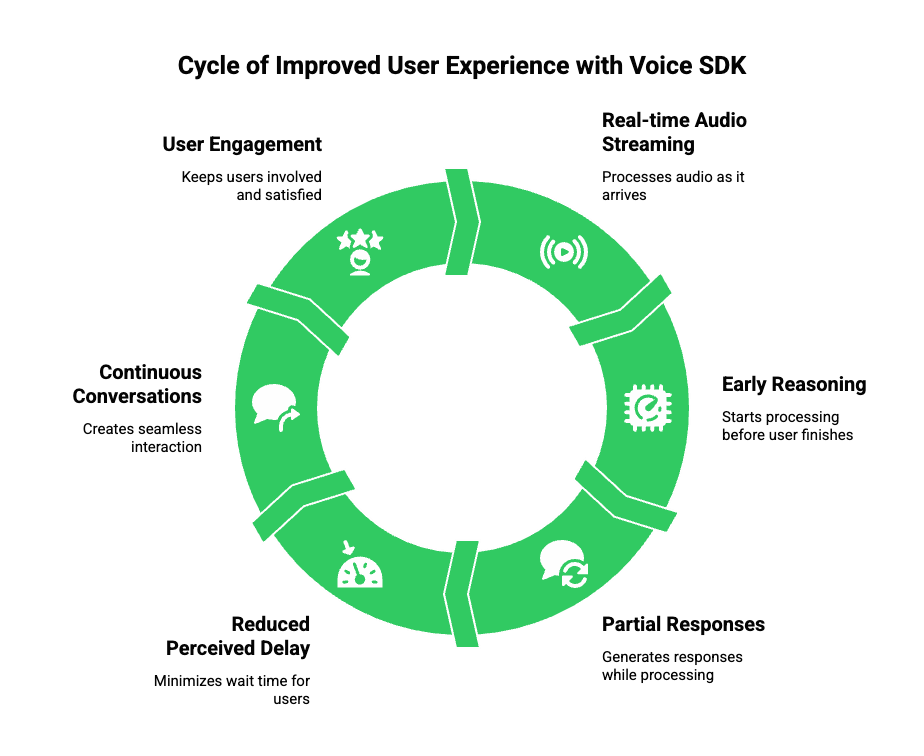
A smarter voice recognition SDK directly impacts how users perceive an application. While accuracy is important, responsiveness defines trust. If an app responds late, users disengage, even if the response is correct.
With smarter SDKs:
- Conversations feel continuous instead of fragmented
- Users can interrupt, clarify, or change direction
- Responses feel immediate, not queued
- The app behaves more like a human interaction
From a technical perspective, this improvement comes from real-time audio streaming rather than request-response APIs. Instead of waiting for the user to finish speaking, the system processes audio as it arrives.
As a result, apps can:
- Start reasoning earlier
- Generate partial responses
- Reduce perceived delay
This is especially important for voice-first applications such as support, operations, and real-time assistance.
What Are Voice Agents, And How Are They Built Under The Hood?
Voice agents are often misunderstood as single systems. In reality, they are orchestrated pipelines made up of multiple independent components.
A typical voice agent consists of:
| Component | Role |
| STT (Speech-To-Text) | Converts live audio into text |
| LLM | Interprets intent and generates responses |
| RAG | Supplies domain-specific knowledge |
| Tool Calling | Executes actions or fetches data |
| TTS (Text-To-Speech) | Converts responses back to audio |
Together, these components form a voice agent. However, none of them alone is sufficient.
Because of this, the quality of a voice agent depends on:
- How well components communicate
- How fast data moves between them
- How context is preserved across turns
This is why a voice recognition SDK is not just a feature. Instead, it is the foundation of the entire voice agent pipeline.
Why Does Latency Break Voice Experiences More Than Accuracy?
Latency is the most underestimated problem in voice systems. While users can tolerate minor transcription errors, they do not tolerate silence. Even a delay of 500 milliseconds feels unnatural in conversation.
Latency affects voice systems at multiple points:
- Audio capture delay
- Network transfer time
- STT processing time
- LLM response time
- TTS generation time
If these delays stack up, the conversation collapses.
Therefore, modern voice systems rely on:
- Streaming audio packets
- Partial transcriptions
- Early response generation
- Duplex audio channels
By processing speech while it is still being spoken, systems reduce waiting time. As a result, responses feel immediate, even if full processing continues in the background.
This approach is critical for any real-time voice agent.
How Can Voice Agents Run On Edge Networks Locally?
Running voice agents on edge networks means executing part of the pipeline closer to the user, rather than fully in the cloud. This approach is increasingly popular for performance and privacy reasons.
A local or edge-based voice setup may include:
- On-device or nearby STT
- A local LLM voice assistant
- Cached RAG data
- Limited cloud dependency
Because inference happens locally, latency drops significantly. In addition, sensitive audio data does not need to leave the device or local network.
There are several deployment patterns:
Fully Local Execution
- STT, LLM, and TTS run locally
- Lowest latency
- Higher hardware requirements
Hybrid Edge Execution
- Local STT + cloud LLM
- Or local LLM + cloud TTS
- Balanced performance and cost
Cloud-Controlled With Edge Streaming
- Audio streams locally
- Reasoning happens remotely
- Requires strong voice infrastructure
Each approach has trade-offs. However, edge execution consistently improves responsiveness and reliability.
What Challenges Arise When Running Voice Agents Locally?
Although edge execution offers clear benefits, it also introduces challenges. Many teams underestimate the complexity involved.
Common challenges include:
- Handling unstable network conditions
- Managing real-time audio streams
- Maintaining call continuity
- NAT and firewall traversal
- Synchronizing audio and AI responses
Moreover, voice agents do not operate in isolation. They often need to interact with VoIP network solutions, phone systems, or enterprise telephony.
This is where many teams struggle. While AI logic may run locally, voice transport still requires robust infrastructure. Without it, conversations break, audio drops, or latency spikes.
As a result, teams realize that building AI is only half the problem. Delivering it over real-world voice networks is the other half.
Why Do Most Teams Struggle With Voice Infrastructure At Scale?
By this stage, many teams understand how to build AI logic. They can fine-tune models, deploy a local LLM voice assistant, and even integrate RAG pipelines. However, when it comes to voice, progress slows down quickly.
The reason is simple. Voice is not just AI. Voice is infrastructure.
Most engineering teams face challenges such as:
- Dropped audio during live conversations
- Delayed responses due to network hops
- Difficulty handling inbound and outbound calls
- Lack of control over real-time media streams
- Poor observability into call-level performance
While AI systems can run locally, voice still needs to travel across real networks. Because of this, problems often appear outside the AI stack.
In many cases, teams rely on traditional calling platforms. However, these platforms were designed for humans, not AI-driven conversations. As a result, they struggle with streaming, low-latency feedback, and context preservation.
How Are Calling Platforms Different From Voice Infrastructure For AI?
This distinction is critical and often overlooked.
Traditional calling platforms focus on:
- Call setup and teardown
- Agent routing
- IVR trees
- Recording and compliance
While these features are useful, they are call-centric, not conversation-centric.
In contrast, AI voice agents require:
- Continuous, bidirectional audio streaming
- Millisecond-level latency control
- Stable transport for long conversations
- Direct integration with AI pipelines
- Full control over conversational state
Because of this mismatch, teams end up forcing AI workflows into systems that were never designed for them. Eventually, scaling becomes painful.
Therefore, modern voice agents require voice infrastructure, not just calling APIs.
How Does FreJun Teler Enable Edge-Ready Voice Agents Without Lock-In?
This is where FreJun Teler fits into the architecture.
FreJun Teler is not an AI platform and does not compete with LLMs or agent frameworks. Instead, it acts as the real-time voice transport layer that connects AI systems to real-world voice networks.
From a technical perspective, Teler focuses on:
- Real-time media streaming over VoIP
- Low-latency audio ingestion and playback
- Stable connections for long-running conversations
- Compatibility with any LLM, STT, or TTS
- Model-agnostic and infrastructure-first design
Because of this approach, teams can run:
- A fully local LLM voice assistant
- A hybrid edge-cloud AI pipeline
- Or a cloud-based reasoning system
All while maintaining reliable voice delivery.
Importantly, Teler does not control AI logic. Instead, it transports voice reliably, allowing developers to keep full ownership of intelligence, context, and decision-making.
What Does A Typical Edge-Based Voice Agent Architecture Look Like?
To understand how everything fits together, it helps to walk through a typical flow.
Step-By-Step Architecture Flow
- Call Initiation
- An inbound or outbound call is established
- Voice media begins streaming immediately
- An inbound or outbound call is established
- Real-Time Audio Streaming
- Audio packets are streamed continuously
- No waiting for full utterances
- Low jitter and packet loss handling
- Audio packets are streamed continuously
- Speech-To-Text Processing
- STT runs locally or at the edge
- Partial transcriptions are emitted
- Intent detection begins early
- STT runs locally or at the edge
- LLM Reasoning
- A local or remote LLM processes text
- Context is maintained by the application
- Tool calls or RAG queries are triggered
- A local or remote LLM processes text
- Text-To-Speech Generation
- Response audio is generated
- Streaming playback begins immediately
- Response audio is generated
- Audio Playback To Caller
- Voice response is streamed back
- Conversation continues without reset
- Voice response is streamed back
In this setup, Teler handles steps 1, 2, and 6. Meanwhile, developers control everything else.
This separation keeps systems flexible, scalable, and future-proof.
How Does This Architecture Support Local And Hybrid AI Execution?
One major advantage of this design is adaptability.
Teams can start small:
- Cloud-based LLM
- Edge-based STT
- Streaming voice delivery
Later, they can evolve toward:
- Fully local inference
- Regional edge clusters
- Private deployments
Because the voice layer remains constant, changes in AI strategy do not require reworking telephony systems.
As a result, engineering teams avoid lock-in and reduce long-term risk.
Which Use Cases Benefit Most From Edge-Based Voice Agents?
While many applications benefit from voice, some gain more than others.
High-Impact Use Cases
- Customer Support
- Faster response times
- Reduced queue frustration
- Natural problem resolution
- Faster response times
- Logistics And Operations
- Hands-free updates
- Real-time status checks
- Low-latency confirmations
- Hands-free updates
- Healthcare
- Privacy-sensitive conversations
- Local processing requirements
- Always-on availability
- Privacy-sensitive conversations
- Fintech And Compliance
- Reduced data exposure
- Controlled inference environments
- Reliable call handling
- Reduced data exposure
In each case, latency, reliability, and privacy matter more than novelty. Therefore, edge-based execution combined with strong voice infrastructure becomes essential.
What Should Founders And Engineering Leaders Evaluate Before Building?
Before committing to a voice agent strategy, teams should assess a few critical areas.
Key Evaluation Questions
- Where should AI inference run: local, edge, or cloud?
- How much latency is acceptable for users?
- Do we control conversational context fully?
- Can voice scale independently of AI models?
- Is voice infrastructure flexible enough for future changes?
Answering these questions early prevents costly rewrites later.
Moreover, teams should avoid building voice infrastructure from scratch. While tempting, it often leads to fragile systems that fail under real-world conditions.
Can A Smarter Voice Recognition SDK Truly Transform App Experience?
The answer is yes – but only when paired with the right architecture.
A smarter voice recognition SDK improves experience by:
- Reducing friction
- Speeding up interactions
- Enabling real conversations
However, SDKs alone are not enough. Voice agents require:
- Low-latency streaming
- Stable transport
- Flexible infrastructure
- Clear separation of concerns
When these elements work together, voice becomes a primary interface rather than an add-on.
As edge computing and local AI adoption grow, this approach will only become more important. Teams that invest early in proper voice infrastructure will be better positioned to build reliable, scalable, and human-like voice experiences.
Final Takeaway
Modern applications demand interactions that are fast, natural, and reliable. A smarter voice recognition SDK, when combined with local LLM voice assistants and edge execution, transforms app experience by enabling real-time, conversational interactions while minimizing latency and preserving context. Voice agents are no longer experimental; they are central to user engagement, operational efficiency, and enterprise scalability.
However, delivering this experience requires robust voice infrastructure capable of handling low-latency media streaming over VoIP networks, while giving developers full control of AI logic. FreJun Teler provides this foundation – enabling seamless voice transport, reliable real-time streaming, and integration with any AI, STT, or TTS system.
Explore how Teler can power your AI voice agents. Schedule a demo today.
FAQs –
- What is a voice recognition SDK?
A voice recognition SDK converts speech to text and streams audio efficiently, enabling real-time, low-latency voice interactions in apps. - How does a local LLM voice assistant work?
It processes speech locally, generates AI responses, maintains context, and reduces latency without depending fully on cloud servers. - Can voice agents work offline?
Yes, with edge deployment and local AI, voice agents can run offline, preserving privacy and responsiveness even without internet. - Why is latency critical for voice agents?
Even minimal delays disrupt conversational flow. Low-latency systems ensure natural, human-like interactions without awkward pauses or interruptions. - What role does TTS play in voice agents?
Text-to-Speech converts AI responses to audio, enabling seamless communication between AI systems and users over calls or apps. - What is RAG in voice agents?
RAG integrates external knowledge with AI reasoning, improving accuracy of responses while keeping the agent contextually aware. - Why should developers use edge networks for voice agents?
Edge networks reduce latency, enhance reliability, and maintain privacy while running AI logic closer to the user or device. - Can any LLM be integrated with voice agents?
Yes, platforms like Teler are model-agnostic, supporting integration with any AI or LLM for speech processing and responses. - What challenges exist in scaling voice agents?
Scaling challenges include maintaining audio quality, context consistency, network reliability, and real-time streaming across multiple users. - How does FreJun Teler improve voice agent reliability?
Teler handles low-latency voice transport, VoIP integration, and stable streaming, allowing AI logic to operate seamlessly without infrastructure concerns.