
Voice API integration is no longer just about placing and receiving calls. Today, it requires handling thousands of real-time events – speech, intent, silence, and call state – without breaking conversational flow. As AI voice agents become more common across support, sales, and operations, teams must design systems that react instantly and scale reliably. This is where scalable voice webhooks and event-based voice APIs become critical.
In this guide, we break down how to design a webhook architecture that supports real-time voice workloads, integrates cleanly with LLMs and speech systems, and remains stable under production traffic. The goal is simple: help engineering and product teams build voice systems that scale predictably.
Why Do Voice APIs Need Scalable Webhooks In The First Place?
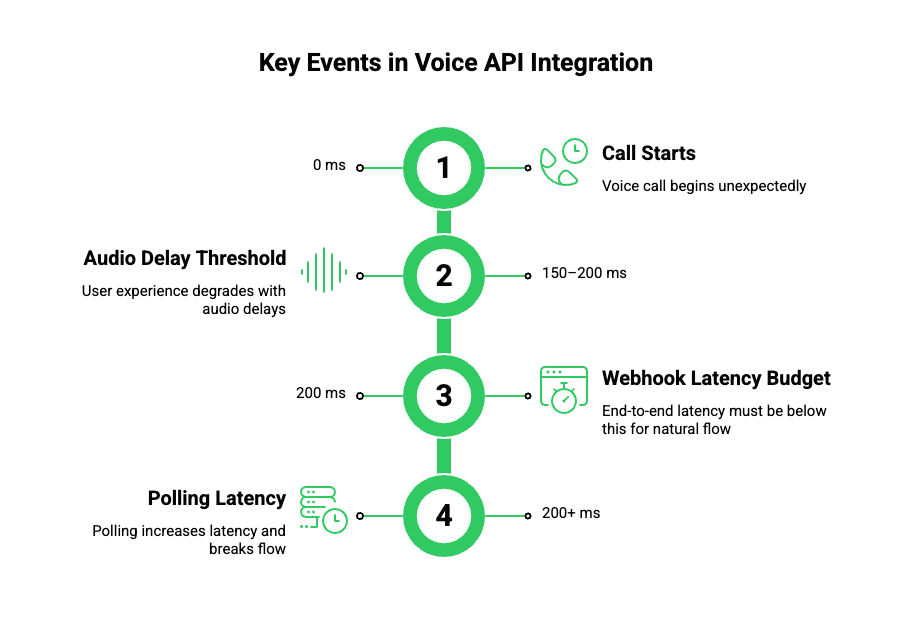
Voice systems behave very differently from traditional web applications. Unlike REST APIs, voice APIs are not request-driven. Instead, they are event-driven systems where actions happen continuously and unpredictably.
User experience research shows that one-way audio delays above 150–200 ms noticeably degrade interactive conversations, which means webhook and streaming latency budgets must be sub-200 ms end-to-end for natural voice flows.
For example:
- A call starts without warning
- A user speaks mid-call
- Silence is detected
- Speech is transcribed
- An intent is identified
- The call ends unexpectedly
Because of this, voice API integration depends heavily on scalable voice webhooks to deliver these events in real time.
Why Polling Does Not Work For Voice
Polling forces your system to repeatedly ask, “Did something happen?”
However, voice workloads demand immediate responses.
Polling fails because:
- It increases latency
- It wastes infrastructure resources
- It does not scale during call spikes
- It breaks conversational flow
Therefore, webhooks become the only practical solution. They push events the moment something happens. As a result, your backend stays reactive instead of wasteful.
Transitioning from polling to webhooks is the first architectural shift teams must make when building voice systems.
What Is An Event-Based Voice API And How Do Webhooks Fit Into It?
An event-based voice API emits structured events whenever something meaningful occurs during a call lifecycle.
Instead of returning static responses, the system continuously streams events outward.
Common Voice Events
Some standard events include:
- call.started
- media.stream.connected
- speech.detected
- speech.transcribed
- intent.matched
- call.ended
Each of these events triggers a webhook call to your backend. In other words, webhooks are the delivery mechanism for voice intelligence.
How Event-Based Voice APIs Work
Voice Platform → Event Generated → Webhook Triggered → Your Backend
Because of this structure:
- Business logic lives outside the voice layer
- AI pipelines remain independent
- Systems scale independently
As a result, event-based voice APIs offer better reliability and flexibility than tightly coupled architectures.
What Does “Scalable Webhook Architecture” Mean For Voice API Integration?
Scalability in voice systems does not mean “more requests per second.” Instead, it means handling unpredictable bursts of concurrent voice events without loss or delay.
Voice Workloads Are Spiky
Voice traffic is rarely smooth:
- Outbound campaigns cause sudden spikes
- Support lines flood during incidents
- Global users introduce timezone-driven bursts
Therefore, webhook architecture must absorb these spikes gracefully.
What Scalability Actually Requires
A scalable webhook architecture must:
- Handle thousands of events per second
- Prevent event loss during failures
- Retry safely without duplication
- Maintain low latency under load
Without these guarantees, voice API integration becomes unreliable and hard to operate.
What Are The Core Components Of A Scalable Voice Webhook Architecture?
Before writing code, teams must understand the moving parts. Voice webhook systems work best when event production and event delivery are decoupled.
High-Level Architecture
Voice Events
↓
Event Queue
↓
Webhook Dispatcher
↓
Worker Pool
↓
Customer Endpoints
Core Components Explained
| Component | Responsibility |
| Voice Event Producer | Generates call, speech, and media events |
| Event Queue | Buffers events and absorbs traffic spikes |
| Webhook Dispatcher | Assigns events to delivery workers |
| Worker Pool | Sends HTTP requests asynchronously |
| Persistence Store | Tracks retries, failures, and status |
| Client Endpoints | Receive and process webhook payloads |
Because these components are independent, each one can scale without impacting the others.
How Should Voice Events Be Generated And Normalized For Webhooks?
Webhook scalability starts with event design, not delivery.
Why Event Normalization Matters
Without consistent payloads:
- AI pipelines become brittle
- Downstream systems break silently
- Version upgrades become risky
Therefore, every voice event must follow a predictable structure.
Recommended Webhook Payload Structure
At a minimum, include:
- event_type
- event_id
- timestamp
- call_id
- sequence_number
- payload
Example Payload (Simplified)
{
“event_type”: “speech.transcribed”,
“event_id”: “evt_123”,
“call_id”: “call_456”,
“sequence”: 42,
“timestamp”: “2026-01-21T10:15:00Z”,
“payload”: {
“text”: “I want to reschedule my appointment”,
“confidence”: 0.93
}
}
Because payloads are normalized, AI, analytics, and CRM systems can evolve independently.
How Do You Handle High-Throughput Voice Events Without Dropping Webhooks?
Direct webhook delivery does not scale. Instead, asynchronous delivery is mandatory.
Why Synchronous Delivery Fails
Synchronous webhooks fail because:
- Client endpoints respond slowly
- Network latency varies
- Retries block upstream processing
As traffic grows, the entire system slows down.
Queue-Based Delivery Model
To fix this, teams insert a queue between event creation and delivery.
| Without Queue | With Queue |
| Events block on delivery | Events buffered safely |
| Failures cascade | Failures isolated |
| Limited throughput | Horizontal scaling |
Because of this, queues act as shock absorbers for voice traffic.
How Do Retries, Idempotency, And Failure Handling Work For Voice Webhooks?

Failures are normal in distributed systems. Therefore, webhook architecture must assume failure.
Retry Strategy
A proper retry system includes:
- Exponential backoff
- Maximum retry count
- Timeout enforcement
Idempotency Is Mandatory
Voice events will be retried. As a result, client systems must safely handle duplicates.
Use:
- event_id for deduplication
- Idempotent database writes
- Stateless webhook handlers
Failure Isolation
When retries fail repeatedly:
- Move events to a Dead Letter Queue (DLQ)
- Alert engineering teams
- Preserve payloads for replay
This approach ensures no voice event is silently lost.
How Do You Secure Webhooks In Voice API Integrations?
Once webhook delivery scales, security becomes non-negotiable. Voice APIs carry sensitive data such as phone numbers, speech content, and intent signals. Therefore, webhook architecture must be secure by default.
Enforce HTTPS Everywhere
First and foremost, webhook endpoints must only accept HTTPS. This ensures:
- Encrypted payloads in transit
- Protection against man-in-the-middle attacks
- Compliance with enterprise security standards
Without HTTPS enforcement, voice API integration should be considered unsafe.
Payload Signing And Verification
Next, webhook providers should sign payloads using a shared secret. On the receiving side, your backend must verify this signature before processing the event.
This approach:
- Prevents spoofed webhook calls
- Ensures payload integrity
- Confirms the sender’s identity
Because webhook endpoints are public by nature, signature verification is essential.
Rate Limiting And Abuse Protection
Even valid webhook sources can misbehave due to retries or bugs. Therefore:
- Apply rate limits per source
- Reject payloads exceeding size limits
- Enforce strict timeouts on webhook handlers
As a result, your system stays stable even under abnormal conditions.
How Do Webhooks Power AI Voice Agents End-To-End?
At a technical level, voice agents are orchestration systems, not monoliths.
A modern AI voice agent is composed of:
- Speech-to-Text (STT)
- Large Language Model (LLM)
- Tool calling and business logic
- Retrieval-Augmented Generation (RAG)
- Text-to-Speech (TTS)
Webhooks are the glue that connects these components.
Event-Driven Voice Agent Flow
Instead of a linear pipeline, voice agents operate as an event loop.
Voice Event → Webhook → AI Logic → Action → Voice Response
Because of this:
- Each component can scale independently
- Failures are isolated
- Latency stays predictable
Key Webhook Touchpoints In AI Voice Agents
Webhooks are triggered at multiple stages:
| Stage | Webhook Purpose |
| Call Start | Initialize session and context |
| Speech Detected | Trigger STT processing |
| Transcription Ready | Send text to LLM |
| Intent Matched | Invoke tools or APIs |
| Call End | Store summary and analytics |
As a result, event-based voice APIs become the backbone of AI voice systems.
How Do You Orchestrate LLMs Using Voice Webhooks?
LLMs should never sit inside the telephony layer. Instead, they should be driven by webhook events.
Why LLMs Must Be Event-Driven
LLMs:
- Are compute-heavy
- Require context management
- Evolve rapidly
Therefore, webhook-triggered orchestration provides:
- Clean separation of concerns
- Easy model replacement
- Controlled latency budgets
Typical LLM Orchestration Pattern
- speech.transcribed webhook arrives
- Backend sends text + context to LLM
- LLM returns intent or response
- Tool calls are triggered if needed
- TTS output is generated
- Audio response is sent back to the caller
Because each step is triggered by events, the system remains flexible and debuggable.
How Do You Introduce FreJun Teler Into A Scalable Voice Webhook Architecture?
At this point, the architecture is clear. The remaining question is where the voice infrastructure fits.
This is where FreJun Teler plays a focused role.
What FreJun Teler Provides
FreJun Teler acts as a real-time voice transport layer, optimized for event-driven systems.
From a webhook perspective, Teler:
- Emits structured voice events
- Streams audio with low latency
- Abstracts telephony complexity
- Integrates cleanly with webhook-based backends
Importantly, Teler does not dictate your AI stack. Instead, it works with:
- Any LLM
- Any STT or TTS provider
- Any RAG or tool-calling system
This separation allows teams to build future-proof voice API integrations.
How Does A Real Production Flow Look With Teler And Webhooks?
To make this concrete, let’s walk through a realistic production flow.
End-To-End Voice Agent Flow
- Incoming call arrives at Teler
- call.started webhook is sent
- Audio stream begins
- speech.transcribed webhook fires
- Backend invokes LLM
- LLM decides next action
- TTS audio is generated
- Response audio is streamed back
- call.ended webhook closes the loop
Each step is event-driven, observable, and independently scalable.
Why This Scales Well
Because:
- Webhooks decouple systems
- Queues absorb spikes
- AI logic runs outside telephony
- Failures are isolated
This design supports both inbound support and outbound campaigns without re-architecture.
What Are Common Mistakes Teams Make With Voice Webhooks?
Even experienced teams fall into predictable traps.
Common Errors To Avoid
- Treating webhooks as synchronous APIs
- Skipping idempotency handling
- Embedding AI logic inside voice infrastructure
- Ignoring retry visibility
- Failing to version webhook payloads
Each mistake increases operational risk over time.
Voice-Specific Pitfalls
Voice systems add extra challenges:
- Long-lived sessions
- Partial speech events
- Silence detection edge cases
- Unexpected call drops
Because of this, robust webhook design is more important for voice than for most other domains.
What Should Founders And Engineering Leaders Focus On First?
For decision-makers, the priority is not tools. Instead, it is architectural clarity.
Strategic Focus Areas
- Choose event-based voice APIs
- Design webhook payloads early
- Decouple voice, AI, and business logic
- Invest in observability from day one
- Select infrastructure that scales independently
When these foundations are strong, implementation becomes predictable.
Final Thoughts
Scalable voice systems are built on events, not requests. Webhooks form the backbone of modern voice API integration by delivering call and speech events reliably, securely, and with low latency. When designed correctly, webhook architecture enables AI voice agents to scale independently of telephony, adapt to traffic spikes, and evolve without rework. Teams that invest early in event normalization, queue-based delivery, and idempotent processing avoid operational issues later.
FreJun Teler fits naturally into this model by acting as a real-time voice transport layer that emits clean, structured events while abstracting telephony complexity. If you are building AI voice agents with LLMs, STT, and TTS, Teler helps you focus on logic, not infrastructure.
FAQs –
- What is voice API integration?
Voice API integration connects telephony systems with backend applications to handle calls, speech, and events programmatically. - Why are webhooks essential for voice APIs?
Webhooks deliver real-time voice events instantly, enabling low-latency reactions without inefficient polling. - What makes voice webhooks scalable?
Queue-based delivery, retries, idempotency, and horizontal workers allow voice webhooks to handle unpredictable traffic spikes. - How are voice APIs different from standard APIs?
Voice APIs are event-driven, long-lived, and real-time, unlike request-response web APIs. - How do AI voice agents use webhooks?
Webhooks trigger STT, LLM processing, tool calls, and TTS responses during live conversations. - Can scalable webhooks reduce call latency?
Yes, event-driven delivery avoids polling delays and keeps conversational responses timely. - What happens if a webhook delivery fails?
Failed deliveries are retried using backoff strategies and isolated using dead-letter queues. - How do I secure voice webhooks?
Use HTTPS, payload signing, authentication secrets, and strict request validation. - Do scalable webhooks support outbound call campaigns?
Yes, they handle large bursts of concurrent call events efficiently. - Is webhook architecture future-proof for voice systems?
Event-based designs adapt easily to new AI models, tools, and voice channels.