
Voicebot solutions are rapidly becoming a cornerstone for modern customer engagement, providing businesses with scalable, intelligent, and interactive communication channels. Unlike traditional IVRs or standard call centers, modern voicebots can respond, understand, and act in real time. This capability is only possible through real-time voice streaming, which allows audio to flow continuously between a human user and an AI-driven voice agent.
Without real-time streaming, voice interactions become delayed, fragmented, or unnatural. For example, slow responses can frustrate callers, reduce conversion rates, and limit automation possibilities. On the other hand, integrating low-latency voicebot APIs enables seamless, conversational interactions that feel intuitive and human-like.
This blog explores the mechanics behind real-time voice streaming in voicebot solutions, how modern AI architectures process voice interactions, and the infrastructure considerations required to deploy efficient, reliable systems.
What Is Real-Time Voice Streaming And How Does It Work?
At its core, real-time voice streaming is the continuous transfer of audio data between a user and a voice agent with minimal delay. Unlike conventional telephony or batch-processing voice systems, real-time streaming ensures that every spoken word is captured, processed, and responded to instantly.
High‑performance STT engines can emit transcript updates as frequently as every 50–100 ms, enabling truly continuous audio understanding.
Key Elements of Real-Time Voice Streaming:
- Low Latency Transmission: Audio packets are sent almost instantaneously, reducing delays that disrupt conversational flow.
- Continuous Audio Stream: Rather than waiting for a complete message, the system transmits audio in small chunks to be processed immediately.
- Reliable Transport Protocols: Technologies like WebRTC, SIP, and RTP manage packet delivery, buffering, and jitter correction to maintain smooth audio.
- Context Preservation: Each audio chunk is linked to the conversation state, enabling accurate, multi-turn dialogue.
Why It Matters For Businesses:
- Real-time responses enhance customer satisfaction.
- Agents, bots, or AI models can adapt dynamically to caller intent.
- Supports scalable, multi-domain automation, from sales calls to support inquiries.
How Do Voicebots Process Conversations In Real Time?
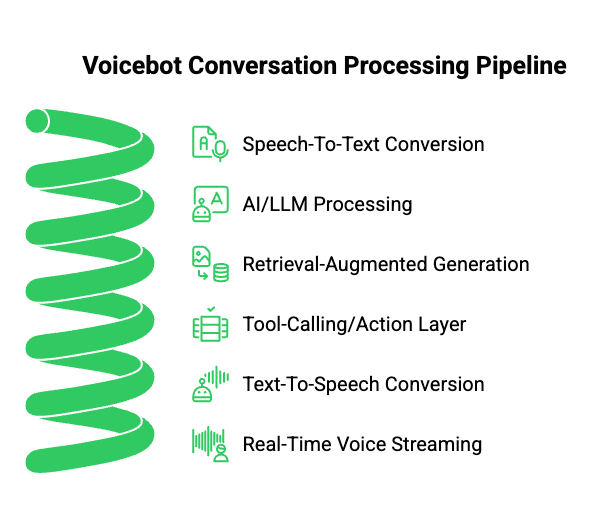
Modern voicebot solutions are more than automated voice systems – they are integrated pipelines combining real-time audio capture, language understanding, and dynamic response generation.
A typical voicebot pipeline includes:
- Speech-To-Text (STT): Converts user speech into text immediately. Popular engines include Google STT, AWS Transcribe, or custom models optimized for streaming.
- AI/LLM Processing: The transcribed text is sent to an AI model or LLM to determine intent, contextual relevance, and appropriate responses.
- Retrieval-Augmented Generation (RAG): For complex queries, the system retrieves relevant information from knowledge bases or APIs in real time.
- Tool-Calling/Action Layer: Executes workflows such as booking appointments, sending notifications, or updating databases.
- Text-To-Speech (TTS): Converts AI-generated responses into human-like audio and streams it back to the caller.
Each stage depends heavily on real-time voice streaming to minimize lag and ensure the user experiences a natural conversation. Without this continuous flow, responses become disjointed and the voicebot loses contextual relevance.
Technical Considerations:
- Audio Chunking: Breaking audio into small, processable packets reduces latency.
- Buffering Strategies: Ensures smooth playback and prevents overlaps or stutters.
- Parallel Processing: STT, AI processing, and TTS occur concurrently to speed up end-to-end response times.
Which Technologies Enable Real-Time Voice Streaming?
Voicebots rely on advanced streaming technologies to capture, transport, and return voice data efficiently. Understanding these mechanisms helps engineering teams optimize latency, reliability, and scalability.
Core Technologies:
| Technology | Role in Voicebot Streaming |
| WebRTC | Real-time audio and video streaming over the web, handles low-latency transport and NAT traversal. |
| SIP (Session Initiation Protocol) | Manages call signaling and session control in VoIP networks. |
| RTP (Real-Time Transport Protocol) | Transports audio packets reliably and in order for smooth playback. |
| Edge Servers | Process audio closer to users, reducing latency and jitter. |
| Media Gateways | Convert between different network protocols while maintaining audio quality. |
Optimizing Streaming Performance:
- Adaptive Bitrate: Adjusts audio quality based on network conditions.
- Jitter Buffers: Absorb network delay variations to prevent breaks in conversation.
- Packet Retransmission: Handles lost packets without affecting the real-time experience.
- Context Preservation: Each stream segment maintains the conversation state for multi-turn dialogues.
How Do Voicebots Integrate Any AI Or LLM In Real Time?
One of the biggest advantages of modern voicebots is their flexibility to integrate any AI model, whether a commercial LLM, open-source model, or a custom-built agent. The integration is model-agnostic and independent of the voice transport layer.
Integration Workflow:
- The voicebot receives audio from a call.
- STT converts audio into text immediately.
- Text is streamed to the AI or LLM for processing.
- The AI applies context, retrieves relevant information (RAG), and generates a response.
- TTS converts the response into audio and streams it back.
Benefits of Model-Agnostic Integration:
- Future-Proof: Easily switch or upgrade AI models without redesigning the voice layer.
- Domain-Specific Customization: Integrate specialized models for healthcare, finance, or logistics.
- Flexible Deployment: Works with cloud-based LLMs, on-prem models, or hybrid configurations.
How Does Teler Enable Real-Time Voice Streaming For Voicebots?
Teler acts as the backbone for low-latency, model-agnostic voice streaming, bridging the gap between live audio and AI processing.
Key Capabilities:
- Low-Latency Streaming: Ensures audio reaches AI models and returns to users with minimal delay, typically under 150ms.
- Model-Agnostic: Works seamlessly with any LLM, STT, or TTS engine.
- Full Context Retention: Maintains conversation state over multiple turns for uninterrupted dialogue.
- Developer-Friendly SDKs: Provides both client-side and server-side tools for quick integration into applications.
- Enterprise Reliability: Offers geo-distributed infrastructure, high availability, and secure transport layers.
How Teler Fits Into The Pipeline:
- Audio Capture: Teler receives inbound or outbound call audio in real time.
- Streaming To AI: Transmits audio chunks to any connected AI model for processing.
- Response Streaming: Receives TTS-generated audio from AI and streams it back instantly to the caller.
- Monitoring & Optimization: Tracks latency, jitter, and packet loss to optimize voice quality.
Use Cases Supported by Teler:
- AI receptionists handling complex inbound queries.
- Outbound campaigns with personalized voice responses.
- Real-time support for video or media streaming platforms.
- Multi-turn conversations for customer success or lead qualification.
How Do Businesses Implement Real-Time Voicebots Effectively?
Implementing a real-time voicebot solution requires a careful combination of AI, voice infrastructure, and operational best practices. A structured approach ensures low latency, high reliability, and seamless user experience.
Step-By-Step Implementation:
- Connect STT Service to Call Audio
- Capture live voice data from inbound or outbound calls.
- Use streaming-capable STT engines for near-instant transcription.
- Ensure low-latency processing to prevent pauses in conversation.
- Capture live voice data from inbound or outbound calls.
- Stream Audio to AI/LLM
- Real-time audio chunks are sent to the AI model for intent detection and contextual understanding.
- The AI analyzes conversation history and updates dialogue state continuously.
- Real-time audio chunks are sent to the AI model for intent detection and contextual understanding.
- Process Context and Execute Actions
- Integrate Retrieval-Augmented Generation (RAG) for accessing knowledge bases or APIs.
- Execute business workflows like appointment scheduling, notifications, or database updates.
- Maintain robust logging and error handling to avoid conversation breakdowns.
- Integrate Retrieval-Augmented Generation (RAG) for accessing knowledge bases or APIs.
- Generate TTS and Stream Back to Caller
- Convert AI-generated responses into audio using a TTS engine.
- Stream the audio in real time, using protocols like WebRTC, RTP, or SIP, to minimize latency.
- Apply jitter buffers and adaptive bitrate control to handle network fluctuations.
- Convert AI-generated responses into audio using a TTS engine.
- Monitor Performance
- Track metrics like latency, packet loss, and conversation completeness.
- Adjust streaming parameters, server distribution, or audio quality based on live performance.
- Track metrics like latency, packet loss, and conversation completeness.
Best Practices for Low-Latency Implementation:
- Use edge servers or geographically distributed nodes to reduce transmission time.
- Optimize audio chunk sizes for processing speed and minimal buffering.
- Implement parallel processing pipelines for STT, AI inference, and TTS to maintain conversation flow.
- Test multi-turn dialogues extensively to ensure context is preserved.
What Are The Key Benefits Of Real-Time Voice Streaming In Voicebot Solutions?
Real-time voice streaming is not just a technical requirement; it directly translates into business and operational advantages. Companies leveraging low-latency voicebot APIs gain measurable improvements across several areas.
Enhanced Customer Experience
- Immediate, human-like responses build trust and engagement.
- Multi-turn, context-aware conversations create smoother, personalized interactions.
Operational Efficiency
- Automates repetitive or high-volume tasks like lead qualification or appointment reminders.
- Reduces dependency on human agents while maintaining quality service.
Flexibility and Integration
- Works with any LLM or AI agent, enabling domain-specific customizations.
- Supports diverse TTS/STT engines for voice quality optimization.
Scalable Campaigns
- Real-time streaming allows large-scale outbound or inbound campaigns without compromising responsiveness.
- Enables dynamic voicebots that adapt on-the-fly based on user intent or workflow logic.
What Are The Common Challenges And How Can They Be Addressed?
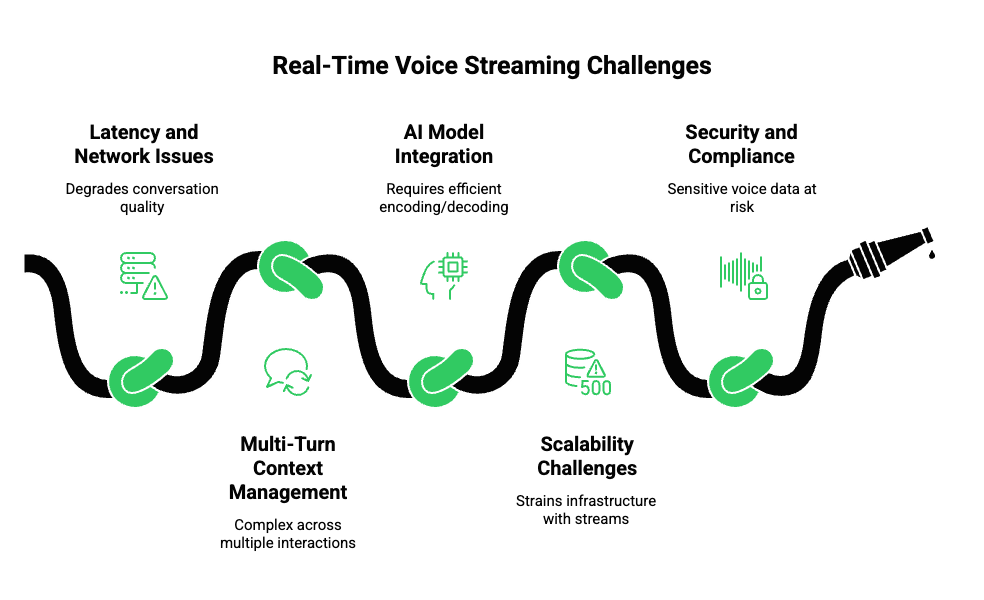
While real-time voice streaming offers numerous advantages, it also presents technical and operational challenges. Understanding and mitigating these issues is critical for robust deployment.
1. Latency and Network Issues
- Network jitter, packet loss, and congestion can degrade conversation quality.
- Mitigation: Use adaptive bitrate streaming, jitter buffers, and geographically distributed servers.
2. Multi-Turn Context Management
- Maintaining conversation context across multiple interactions can be complex.
- Mitigation: Implement stateful streaming pipelines and reliable session management.
3. AI Model Integration
- Streaming audio to AI/LLMs in real time requires efficient encoding, decoding, and context transfer.
- Mitigation: Choose model-agnostic voice layers that separate transport from AI logic, allowing seamless AI upgrades.
4. Scalability Challenges
- Handling thousands of concurrent streams can strain infrastructure.
- Mitigation: Leverage cloud-based or geo-distributed infrastructure with auto-scaling.
5. Security and Compliance
- Voice data often contains sensitive information.
- Mitigation: Implement encryption in transit, access control, and audit logging.
How Can Voicebot Solutions Stay Future-Ready With Real-Time Voice Streaming?
The landscape of voice automation continues to evolve rapidly. Forward-looking businesses must design voicebot systems that can adapt and scale while incorporating new AI advancements.
Emerging Trends:
- Predictive Voicebots: Systems that anticipate user intent based on conversation context or historical interactions.
- Multimodal Integration: Combining voice with video, chat, or IoT devices for richer interactions.
- Dynamic Knowledge Retrieval: Real-time integration with enterprise databases, CRMs, or APIs to provide up-to-date responses.
- Continuous AI Optimization: Regularly fine-tuning LLMs and TTS/STT models to improve accuracy and naturalness.
Forward-looking companies can leverage low-latency voicebot APIs to stay ahead of competitors and deliver next-generation conversational experiences.
How Do Real-Time Voicebots Deliver Measurable Business Value?
When properly implemented, real-time voicebot solutions impact multiple dimensions of business operations:
| Business Metric | Impact of Real-Time Voicebots |
| Customer Satisfaction | Faster, more natural conversations improve NPS and CSAT scores. |
| Operational Efficiency | Automation reduces reliance on human agents for routine tasks. |
| Revenue Conversion | Personalized, context-aware calls improve lead conversion rates. |
| Data Collection | Captures live interaction data for analytics and AI model training. |
| Scalability | Supports high-volume campaigns without degradation in call quality. |
By combining AI with reliable real-time streaming, companies achieve both automation and a superior user experience, which is critical for scaling operations efficiently.
Conclusion
In conclusion, real-time voice streaming forms the backbone of effective voicebot solutions, enabling instant, context-aware, and natural conversations across any enterprise environment. By combining STT, LLMs, RAG, and TTS within a low-latency pipeline, businesses can achieve scalable automation while improving customer engagement, operational efficiency, and personalization.
Platforms like FreJun Teler provide a model-agnostic, reliable voice infrastructure that supports any AI, TTS, or STT engine, ensuring seamless real-time interactions. With Teler, developers and product teams can deploy intelligent voicebots faster, maintain conversation continuity, and focus on business logic rather than infrastructure.
FAQs –
- What is real-time voice streaming in voicebots?
It enables continuous audio transfer between users and AI agents, ensuring low-latency, seamless, human-like conversational interactions. - Why is low latency important for voicebots?
Low latency ensures natural conversation, multi-turn context retention, and instant AI responses, avoiding awkward delays in user interaction. - Can I use any AI model with my voicebot?
Yes, Teler supports model-agnostic integration, allowing OpenAI, custom LLMs, or other AI models seamlessly with voicebots. - How does STT work in real-time voicebots?
Speech-to-text engines convert live voice into text continuously, enabling AI models to interpret user intent instantly. - What role does TTS play in voicebots?
TTS converts AI-generated text responses into natural audio, streamed in real time for uninterrupted user conversations. - How do voicebots maintain conversation context?
Through stable streaming pipelines, session management, and state tracking, voicebots keep multi-turn interactions consistent and accurate. - Which protocols ensure reliable voice streaming?
WebRTC, SIP, and RTP handle low-latency audio transport with buffering, jitter management, and packet loss recovery. - Can voicebots scale for large campaigns?
Yes, low-latency APIs and distributed infrastructure enable high-volume inbound/outbound calls without compromising performance. - How does Teler help developers with voicebots?
Teler provides SDKs, real-time streaming, security, and infrastructure, letting developers focus on AI logic instead of transport layers. - What industries benefit from real-time voicebots?
Healthcare, finance, retail, media, and customer support benefit by automating conversations while improving CX and operational efficiency.