
The ability to create a Real-Time Voice Chat experience powered by AI has moved from a niche capability to a core business requirement. The goal is no longer just to build a bot that can talk; it’s to deploy a system that can handle thousands of concurrent, low-latency, human-like conversations without an error.
Table of contents
- What is Real-Time Voice Chat with AI at Scale?
- The Scaling Challenge: Why Most Voice Chat Fails Under Pressure
- FreJun: The Infrastructure Layer for Production-Grade Voice Applications
- The DIY Approach vs. The FreJun Platform: A Scaling Comparison
- How to Architect Real-Time Voice Chat That Scales?
- Best Practices for a Flawless, Scalable Voice Experience
- Final Thoughts: Building on a Foundation That’s Ready for Growth
- Frequently Asked Questions (FAQ)
This combination of instant audio streaming and advanced AI enables seamless, bi-directional dialogues that are revolutionizing everything from customer support to in-app virtual assistants.
Developers are rising to the challenge, leveraging powerful APIs for speech recognition, language processing, and voice synthesis. They can successfully build a bot that works beautifully for a handful of users.
But the moment they attempt to scale, they hit a brutal and unforgiving wall. The architecture that works in a demo environment shatters under the immense pressure of production traffic, revealing a chasm between a clever prototype and a truly scalable solution.
What is Real-Time Voice Chat with AI at Scale?
A scalable Real-Time Voice Chat system is an intricate, high-performance pipeline designed for reliability and speed across a global user base. The architecture involves several key layers:
- Real-Time Transport: It uses low-latency protocols like WebRTC or WebSockets to stream audio instantly between the user and the application.
- AI Processing Pipeline: It orchestrates a series of AI models in milliseconds transcribing speech with an STT engine, processing intent with an LLM, and generating lifelike responses with a TTS engine.
- Scalable Infrastructure: It is built on a distributed, cloud-native backend designed to elastically handle massive traffic spikes, manage thousands of concurrent sessions, and ensure high availability.
When these components work in perfect harmony, the result is a conversational experience that feels as natural and immediate as talking to another person, no matter where the user is or how many other people are using the service at the same time.
The Scaling Challenge: Why Most Voice Chat Fails Under Pressure
The primary reason voice chat projects fail to scale is that developers underestimate the monumental challenge of the infrastructure. While the AI components are increasingly accessible via APIs, the underlying voice transport layer is a different beast entirely.
Building a Real-Time Voice Chat system that works at scale requires you to solve a host of complex, low-level engineering problems that have nothing to do with AI:
- Massive Concurrency: Handling thousands of simultaneous, bi-directional audio streams is incredibly resource-intensive. It demands a sophisticated, distributed network of media servers.
- Global Latency Management: A user in Tokyo expects the same sub-second response time as a user in New York. This requires a globally distributed infrastructure with intelligent network routing to minimize latency across continents.
- High Availability and Resilience: What happens if a server or a whole data center goes down? A scalable system must have automatic failover, geo-redundancy, and dynamic resource allocation to ensure it is always online.
- Network Jitter and Packet Loss: Real-world networks are imperfect. A production-grade system needs adaptive bitrate streaming and advanced error-recovery techniques to maintain crystal-clear audio quality even on unstable connections.
- Cross-Platform Compatibility: The infrastructure must seamlessly support clients on the web, iOS, Android, and most critically for business the traditional telephone network.
This is the scaling challenge. It’s a full-time, multi-million-dollar infrastructure problem that distracts from the core goal of building a great AI experience.
FreJun: The Infrastructure Layer for Production-Grade Voice Applications
This is precisely the problem FreJun was built to solve. We are not another AI model provider. FreJun is the specialized voice infrastructure platform that handles the entire complex, messy, and mission-critical challenge of delivering Real-Time Voice Chat at scale.
We provide a simple, powerful, and model-agnostic API that allows you to build on top of our globally distributed, enterprise-grade infrastructure.
- We handle the scale: Our platform is engineered to manage thousands of concurrent audio streams with ultra-low latency.
- We guarantee the reliability: With built-in geo-redundancy and automatic failover, we ensure your voice application is always available.
- We manage the network: Our intelligent routing and adaptive streaming technologies deliver crystal-clear audio quality across any network condition.
- We connect to any channel: Our API allows you to deploy your voice AI seamlessly across web, mobile, and the global telephone network.
With FreJun, you can focus on perfecting your AI logic, confident that the underlying infrastructure is ready to handle any level of demand.
Key Takeaway
Building a Real-Time Voice Chat demo is an AI integration challenge. Building one that works at scale is an infrastructure engineering marathon. The most effective strategy is to separate these two problems. Use the best-in-class AI APIs to build your bot’s intelligence, and leverage a specialized platform like FreJun to handle the immense complexity of scalable, real-time voice transport.
The DIY Approach vs. The FreJun Platform: A Scaling Comparison
| Feature | The DIY Infrastructure Approach | The FreJun Platform Approach |
| Scalability | You must build, manage, and pay for a globally distributed network of media servers. Extremely costly and complex. | Built-in. Our platform elastically scales to handle any number of concurrent users on demand. |
| Latency Management | You are responsible for intelligent routing and minimizing latency across all geographic regions. | Managed by FreJun. Our global infrastructure ensures sub-second response times worldwide. |
| Reliability & Uptime | You must engineer and maintain your own failover, redundancy, and disaster recovery systems. | Guaranteed. We provide an enterprise-grade SLA with built-in geo-redundancy and automatic failover. |
| Infrastructure Cost | Massive capital expenditure and ongoing operational costs for servers, bandwidth, and a specialized DevOps team. | Predictable, usage-based pricing with no upfront capital expenditure. |
| Time to Market | Months, or even years, to build a production-ready, scalable system. | Weeks. Launch a globally scalable voice application in a fraction of the time. |
| Developer Focus | Divided 50/50 between building the AI and wrestling with low-level network engineering. | 100% focused on building the best possible AI and conversational experience. |
How to Architect Real-Time Voice Chat That Scales?
This guide outlines the modern, scalable architecture for a voice AI application using FreJun.
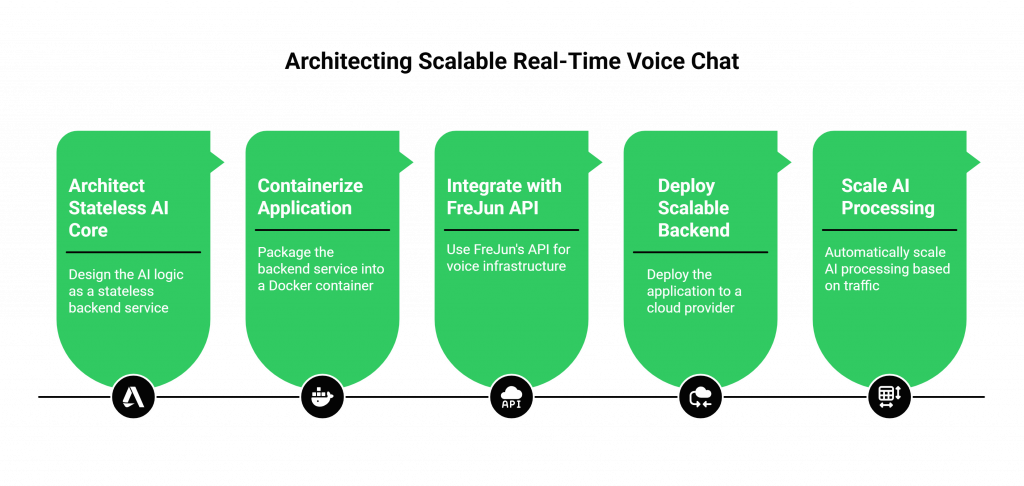
Step 1: Architect a Stateless AI Core
The heart of your application is the AI logic that orchestrates your STT, LLM, and TTS services. Design this as a stateless backend service. It should be able to process a request based on the data it receives, managing conversation history in a distributed cache or database (like Redis or DynamoDB). This is crucial for horizontal scaling.
Step 2: Containerize Your Application
Package your stateless backend service into a Docker container. This makes it portable, easy to deploy, and simple to scale across any cloud environment.
Step 3: Offload All Voice Infrastructure to FreJun
Instead of building a media server stack, integrate your backend with FreJun’s API.
- Sign up for FreJun and get your API keys.
- If you need telephony access, provision a phone number.
- Use our server-side SDK to create an endpoint that can receive a bi-directional audio stream from our platform.
Step 4: Deploy Your Scalable Backend
Deploy your containerized application to a cloud provider like AWS, Google Cloud, or Azure. Use a managed container service (like Amazon ECS, Google Cloud Run, or Kubernetes) that can automatically scale the number of running instances of your AI core based on traffic.
With this architecture, you have a perfectly decoupled system. FreJun handles the massive challenge of scaling the real-time voice connections, while your cloud provider handles scaling your AI processing logic.
Best Practices for a Flawless, Scalable Voice Experience
- Optimize Your AI Pipeline: While FreJun handles the transport latency, you are still responsible for the processing latency of your AI stack. Choose STT, LLM, and TTS providers that offer low-latency streaming responses.
- Implement Robust State Management: Use a fast, distributed database or cache to manage session context. This is essential for providing intelligent, multi-turn conversations at scale.
- Secure Everything: Use encryption for all data in transit and at rest. Manage your API keys securely and ensure your application is compliant with all relevant privacy regulations like GDPR.
- Monitor Continuously: Implement comprehensive logging and monitoring for both your application’s performance and the quality of the user experience. This will allow you to identify bottlenecks and continuously improve your service quickly.
Final Thoughts: Building on a Foundation That’s Ready for Growth
The demand for high-quality, Real-Time Voice Chat is only going to increase. Users expect instant, seamless, and intelligent interactions, whether they are one of ten people using your service or one of ten thousand. Your application’s success hinges on its ability to deliver that experience consistently and reliably, at any scale.
Attempting to build the required infrastructure from the ground up is a monumental task that sets most projects up for failure. It is a drain on resources, a distraction from your core mission, and a high-risk gamble.
The strategic path forward is to build on a platform that was designed from day one for scale. By leveraging FreJun’s enterprise-grade voice infrastructure, you de-risk your project, accelerate your time to market, and free your team to focus on what truly differentiates you: the intelligence and quality of your AI. Build an AI that’s ready to take on the world, and let us handle connecting it.
Further Reading – Why Just Calling Isn’t Enough: The Need for Intelligent Calling Tools
Frequently Asked Questions (FAQ)
FreJun operates on a globally distributed, cloud-native infrastructure that is designed for massive concurrency. We use sophisticated load balancing, elastic scaling, and intelligent network routing to manage thousands of simultaneous real-time audio streams with high reliability.
Our global points of presence and optimized routing ensure the lowest possible transport latency. The end-to-end latency for your Real-Time Voice Chat will be a combination of our transport time plus the processing time of your chosen STT, LLM, and TTS providers. A well-architected system can consistently achieve sub-second round-trip times.
Yes. Our infrastructure is engineered for high availability with built-in geo-redundancy and automatic failover mechanisms. This ensures that your voice application remains online even in the event of a regional service disruption.
Yes. FreJun handles the scaling of the voice transport layer the connections and media streams. You are still responsible for scaling your own backend application to handle the AI processing (the STT, LLM, and TTS API calls) for all your concurrent users. Architecting a stateless service makes this much easier.
Absolutely. FreJun provides a unified API to connect your AI to both web/mobile clients and the global telephone network (PSTN), allowing you to create a truly omnichannel Real-Time Voice Chat solution.