
The demand for natural, human-like conversations over phone calls is growing rapidly as businesses seek to automate customer engagement and support. Traditional IVR systems no longer meet user expectations, and chatbots alone cannot replace the immediacy of live calls. This is where real-time voice assistants running on a VoIP network come into play. By combining speech recognition, AI reasoning, and speech synthesis with robust VoIP network solutions, organizations can deliver seamless experiences that feel both efficient and personal.
In this blog, we’ll explore the technical foundations of deploying a voice assistant on VoIP, the challenges you must address, and how the right infrastructure choices unlock scalable, production-grade deployments.
What Is a VoIP Network and Why Does It Matter for AI Voice Assistants?
A VoIP network (Voice over Internet Protocol) turns voice into digital packets and transmits them over the internet. Every phone call you make through apps like Zoom, WhatsApp, or enterprise SIP lines is powered by this underlying protocol.
For AI-driven assistants, VoIP networks are critical because they act as the gateway between callers and software. Unlike chat interfaces, calls are synchronous and sensitive to delays. A small lag that might go unnoticed in a chatbot creates awkward silence on a live call.
That is why deploying AI assistants over VoIP is more complex than embedding them into messaging platforms. You need VoIP network solutions that can:
- Stream audio in real time.
- Maintain duplex communication (both sides can speak simultaneously).
- Handle packet loss, jitter, and codec differences.
- Scale across regions while meeting telecom compliance.
Without this foundation, even the best speech-to-text or AI model will fail to deliver a natural experience.
What Are the Core Components of a Real-Time AI Voice Assistant?
To deploy a real-time assistant, several moving parts must be orchestrated together. Think of it as a pipeline where human speech continuously flows through four layers before looping back:
- Speech-to-Text (STT): Transcribes live audio into text.
- AI Processing (LLM or Orchestrator): Interprets the transcription, applies context, and decides the response.
- Text-to-Speech (TTS): Converts AI-generated text into natural audio.
- Transport Layer: Streams audio in and out of the VoIP network.
Each layer is independent yet tightly coupled. STT accuracy determines whether the model understands the caller. The AI model must respond quickly while maintaining context across turns. TTS must produce speech that feels human rather than mechanical. And finally, the transport layer ensures everything flows in real time.
| Layer | Role | Technical Consideration | Examples |
| STT | Audio to Text | Streaming transcription, < 300 ms delay | Whisper, Deepgram, AssemblyAI |
| AI | Text to Response | Context management, external API calls, latency control | GPT, Claude, Llama |
| TTS | Text to Audio | Natural prosody, multiple voices, < 200 ms synthesis | Azure Neural, ElevenLabs, Google TTS |
| Transport | Connects to VoIP | Duplex streaming, codec handling, jitter buffers | SIP/RTC frameworks, APIs |
The magic lies in how these parts synchronize without breaking conversational flow. In high-stakes conversational contexts, STT error rates can still exceed 25%, making accuracy a critical reliability factor.
How Does a Real-Time Voice Assistant Work During a Phone Call?
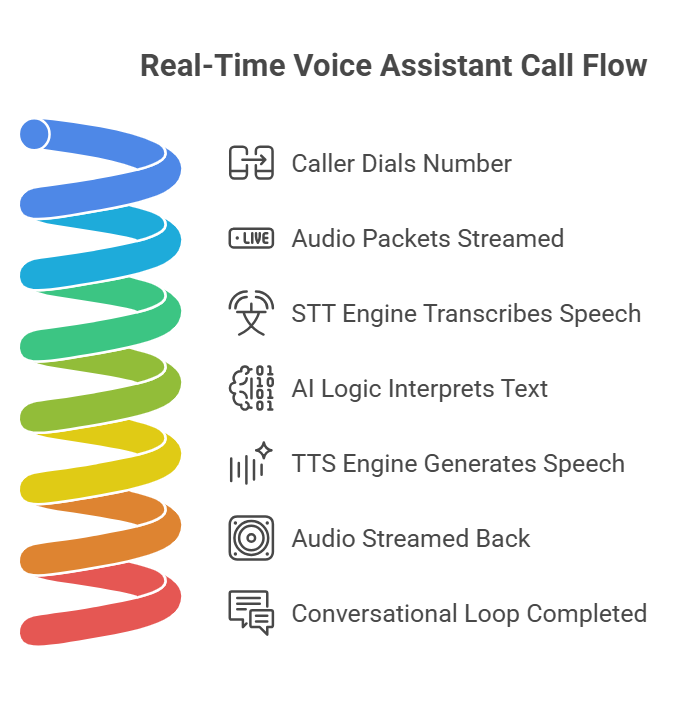
A typical call flow looks like this:
- Caller dials a number that connects through a VoIP trunk or PSTN gateway.
- Audio packets are streamed from the caller’s microphone through the VoIP network to your backend.
- The STT engine transcribes speech on the fly, often delivering partial transcripts before the user finishes speaking.
- AI logic interprets the text, checks context, pulls relevant data, or calls an external API if needed.
- The TTS engine generates synthetic speech from the AI’s response.
- Audio is streamed back to the caller over the VoIP line, completing the conversational loop.
This happens continuously with latencies measured in milliseconds. For a call to feel natural:
- End-to-end delay should stay below 500 ms.
- Jitter buffers must smooth out network inconsistencies.
- Duplex streaming must allow interruptions and overlaps, just like human conversations.
When these conditions are met, the assistant feels conversational rather than robotic.
What Are the Challenges of Running AI Assistants on VoIP Networks?
Deploying real-time assistants is not simply about plugging in an LLM. Telephony adds its own complexity:
- Latency Accumulation: STT, AI reasoning, and TTS each add delay. Even small delays stack up into noticeable pauses.
- Codec Variations: Different VoIP providers may use codecs like Opus, G.711, or G.729. Compression saves bandwidth but can degrade transcription accuracy.
- Network Conditions: Packet loss or jitter can distort audio, requiring error correction.
- Context Retention: Phone calls often span multiple turns. The assistant must remember context without losing track when speech overlaps.
- Scalability: Handling hundreds of simultaneous calls means distributing workloads across multiple servers and regions.
These are engineering challenges that product managers and tech leads must address before scaling from prototype to production.
Understand how cloud telephony seamlessly connects AI voice agents to VoIP network solutions, ensuring reliability, scalability, and real-time communication experiences.
How Do You Deploy a Real-Time Voice Assistant Step by Step?
A structured approach makes deployment manageable.
Step 1: Connect to a VoIP Network
- Configure SIP trunks or PSTN routing.
- Ensure the VoIP provider supports real-time media streaming.
- Decide on regional gateways for compliance and latency reduction.
Step 2: Stream Caller Audio to STT
- Capture raw audio packets as they arrive.
- Send them to a streaming STT service that can output partial transcriptions.
- Use noise suppression and codec optimization to improve accuracy.
Step 3: Process Transcriptions with Your AI Runtime
- Feed transcripts into an LLM or orchestration framework.
- Implement dialogue management to handle context and multi-turn logic.
- Trigger external API calls when the assistant needs live data (e.g., CRM lookup, appointment booking).
Step 4: Generate and Play Responses
- Pass AI output to a TTS engine that supports expressive speech.
- Control pitch, tone, and emphasis to match your brand voice.
- Stream generated audio back into the VoIP channel without noticeable delay.
Step 5: Monitor and Optimize
- Measure latency at each stage (STT, AI, TTS, transport).
- Log transcription accuracy and response relevance.
- Use dashboards to detect bottlenecks before they impact live calls.
When this loop is stable, the assistant can scale to handle real customer conversations.
Why Is Latency the Most Critical Metric in Real-Time Assistants?
On chat interfaces, a one- or two-second pause is acceptable. On phone calls, it feels like dead air. Latency is therefore the single most important performance measure.
Breaking it down:
- STT latency should be < 300 ms for partial transcriptions.
- AI processing time should target < 200 ms for typical turns.
- TTS synthesis should complete in < 200 ms.
- Transport latency should remain < 100 ms round trip.
If each stage meets these targets, the total conversation feels fluid. Exceed them, and the assistant sounds sluggish.
Latency is not only technical – it directly shapes customer trust. A fast response feels intelligent, while a delayed one feels broken.
How Can You Ensure Reliability and Scale in Production?
Reliability requires thinking beyond the core AI pipeline.
- Redundant VoIP gateways prevent downtime if one carrier fails.
- Load balancing distributes calls across multiple AI workers.
- Monitoring dashboards track call quality, audio packet loss, and end-to-end latency.
- Compliance frameworks (GDPR, HIPAA, PCI DSS) ensure data handling aligns with regulations in each region.
Scaling means not just adding more servers, but designing for global distribution. An assistant answering calls in New York should not rely on a single data center in Europe. Regional routing reduces latency and meets local telecom requirements.
What Are Practical Use Cases for Real-Time Voice Assistants on VoIP?
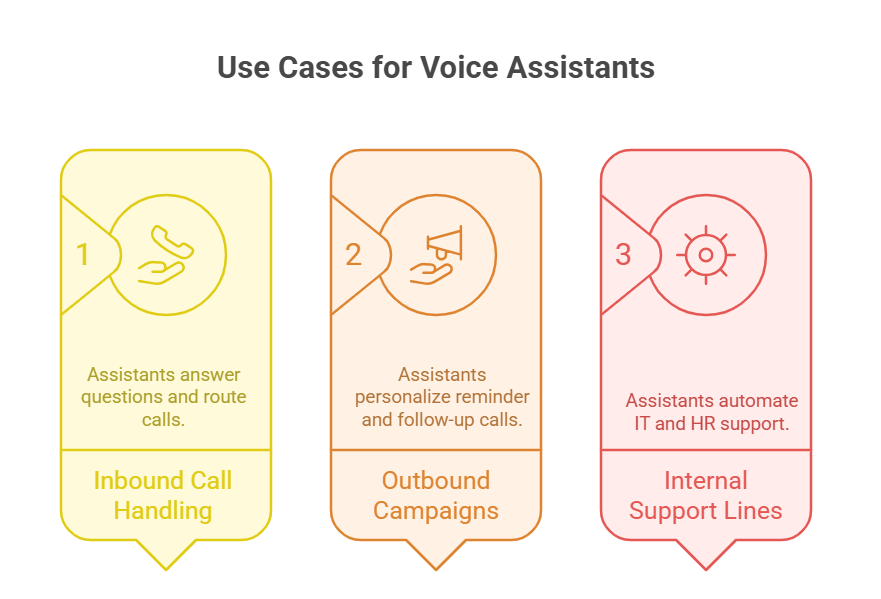
The best way to understand the impact of AI-powered voice assistants is to look at how they are applied in real-world business settings.
One of the most common use cases is inbound call handling. Instead of waiting on hold or navigating through rigid IVR menus, a caller can speak naturally, and the assistant can answer questions, route the call, or even complete transactions. A hospital, for example, can let patients check appointment slots without involving a receptionist.
Another major use case is outbound campaigns. Financial institutions, logistics companies, and service providers often need to run large volumes of reminder or follow-up calls. With a real-time assistant running on a VoIP network, these campaigns feel personalized, as the assistant can adapt the script depending on how the customer responds.
In addition, internal support lines such as IT helpdesks or HR hotlines can be automated. This reduces response time for employees while freeing human staff to focus on complex issues.
Across industries, the pattern is clear: if phone calls remain central to the customer or employee journey, a real-time assistant reduces cost, increases availability, and delivers a more responsive experience.
Explore how personalized outbound voice campaigns built on VoIP networks can increase conversions, improve customer trust, and scale outreach efficiently.
What Best Practices Improve the Reliability of AI Assistants on VoIP Networks?
Reliability in production goes beyond building a functional prototype; it requires disciplined engineering and attention to detail across the pipeline. Codec selection alone can change latency by tens of milliseconds, making optimization essential for real-time deployment.
- Prioritize Latency Management: Each stage – STT, AI processing, TTS, and transport – adds delay. Keep the total under 500 ms through careful measurement and tuning.
- Design for Network Resilience: VoIP traffic is vulnerable to packet loss and jitter. Adaptive codecs like Opus and jitter buffers keep calls stable.
- Implement Graceful Error Handling: Silence frustrates users. If the AI stalls, filler audio such as “Let me check that for you” maintains flow.
- Enable Seamless Human Handover: Not all calls should be automated. Ensure smooth transfer to human agents with context passed along to avoid repetition.
How Do You Measure Success When Deploying a Voice Assistant?
Technical success and business success often require different metrics.
From a technical perspective, teams should monitor word error rate of the STT system, average latency across each stage of the pipeline, and the naturalness of generated speech. Call quality indicators such as packet loss and drop rates should also be tracked. Raw error rates may look high, but when weighted for comprehension, effective error drops closer to 1 to 2%.
From a business perspective, the metrics shift to outcomes. How many calls were resolved without a human? How much did average handling time decrease? Did customer satisfaction improve compared to traditional IVR? These numbers demonstrate whether the investment in voice automation is delivering value.
How Does FreJun Teler Help Developers Deploy Voice Assistants on VoIP?
Everything described so far – low-latency streaming, duplex audio, codec handling, resilience, scaling – is possible to build in-house. But doing so requires months of telecom engineering. This is where FreJun Teler aligns perfectly with the problem this blog has explored.
Teler is a voice infrastructure layer built for AI applications. Instead of writing custom SIP integrations or managing jitter correction yourself, you connect your existing VoIP trunk or PSTN gateway to Teler. From there, Teler handles:
- Real-time audio streaming with sub-200 ms turnaround.
- Full-duplex communication, allowing overlaps and interruptions just like natural calls.
- Compatibility with any STT, LLM, or TTS engine, giving teams freedom to choose their own AI stack.
- Developer-first SDKs, making it easy to embed call handling into backends or mobile apps.
- Scalable infrastructure, with global routing and compliance built in.
For developers, this means faster prototyping and less time wasted on telecom plumbing. For product managers, it shortens the time to market. And for founders, it provides a predictable path from pilot to global scale.
What Should Teams Remember Before They Deploy?
Three lessons stand out for anyone preparing to launch.
- Voice is unforgiving. Unlike chat, delays on calls feel broken. Prioritize latency across every component.
- Flexibility is power. Keep the layers of your stack independent so you can swap providers and optimize over time.
- Transport is the foundation. AI models may change, but if the VoIP integration is brittle, everything on top suffers.
With these principles in mind, businesses can approach deployment with confidence.
Conclusion
Building a real-time voice assistant on a VoIP network requires more than connecting an LLM to a phone line. Success depends on synchronizing speech recognition, AI reasoning, speech synthesis, and reliable transport into one seamless pipeline. By focusing on latency, resilience, and measurement, teams can move from experiments to assistants that genuinely feel natural in production environments.
This is where Frejun Teler makes the difference. As a purpose-built voice infrastructure layer, it abstracts away telecom complexity, delivers low-latency duplex streaming, and enables developers to focus on innovation rather than network engineering. The result is faster development cycles, enterprise-ready reliability, and scalable assistants designed for growth.
Schedule a Demo of Teler with Our Experts and see how easily you can launch your own production-grade real-time voice assistant.
FAQs –
Can I deploy a voice assistant on my existing call center VoIP system?
Yes, you can integrate assistants directly into existing VoIP systems using APIs, provided duplex streaming and low latency are supported.
Do I need telecom expertise to build a real-time voice assistant?
No, infrastructure layers like FreJun Teler abstract telecom complexity, letting developers focus on AI logic, STT, and TTS.
What industries benefit most from AI-powered VoIP assistants?
Healthcare, finance, logistics, and customer service industries gain efficiency, cost savings, and availability by automating real-time voice interactions.
How fast can I prototype a real-time assistant using VoIP network solutions?
With existing VoIP infrastructure and Teler integration, functional prototypes can often be built within days, not months.