
Your customers expect instant, intelligent, and human-like interactions. The era of clunky Interactive Voice Response (IVR) systems and long hold times is over.
Businesses are now in a race to deploy sophisticated voice agents that can understand complex queries, provide nuanced answers, and resolve issues without delay. The technology making this possible is real-time conversational AI, a transformative force in customer engagement.
Table of contents
- The New Standard for Customer Interaction: Real-Time Voice AI
- What is Real-Time Conversational AI?
- The Hidden Challenge: The Complex Infrastructure Layer
- FreJun: The Voice Transport Layer for Your AI Stack
- How to Integrate Your AI with Phone Calls Using FreJun?
- Building Voice AI: The Hard Way vs. The FreJun Way
- A Toolkit for Production-Grade Voice Applications
- Powering the Next Generation of Voice Automation
- Final Thoughts: Focus on AI, Not Infrastructure
- Frequently Asked Questions (FAQ)
The New Standard for Customer Interaction: Real-Time Voice AI
However, building a voice AI is not just about choosing a powerful Large Language Model (LLM). While models from OpenAI, Google, and others provide the “brains” of the operation, a critical and often underestimated challenge remains: how do you connect this intelligence to a live phone call?
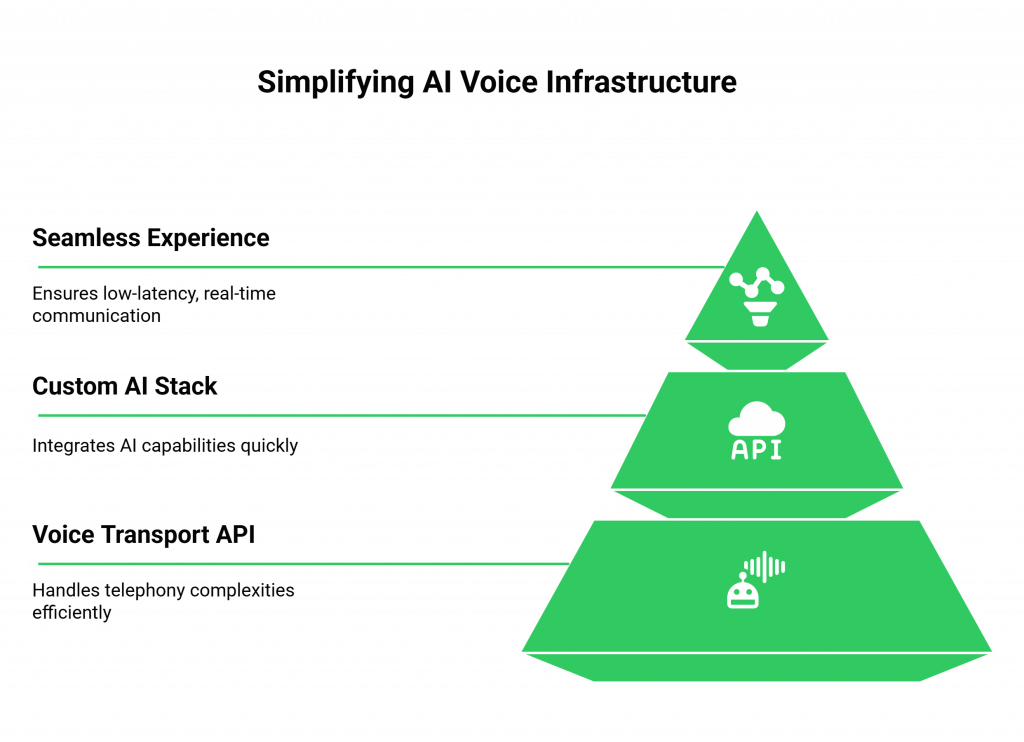
The process involves navigating complex telephony networks, managing real-time audio streams, and ensuring low-latency communication to create a seamless experience. Consequently, building this voice infrastructure from the ground up is a resource intensive task that distracts from your primary goal: creating a superior AI-driven service.
This is where a specialized voice transport layer becomes essential. Instead of wrestling with the intricacies of telephony, you can leverage a robust API designed to handle the entire voice layer, allowing you to plug in your custom AI stack and go live in days, not months.
What is Real-Time Conversational AI?
Real-time conversational AI refers to intelligent systems that can engage in natural, human-like dialogue with users instantly. Unlike traditional chatbots or scripted voice assistants, these systems are dynamic. They can process information, understand context, and respond fluidly, creating a truly interactive experience.
According to the Chatbot, 74% of users who have engaged with voice or chat assistants are satisfied with their interactions, highlighting a strong consumer appetite for this technology.
The magic behind this technology is a combination of several advanced components working in harmony:
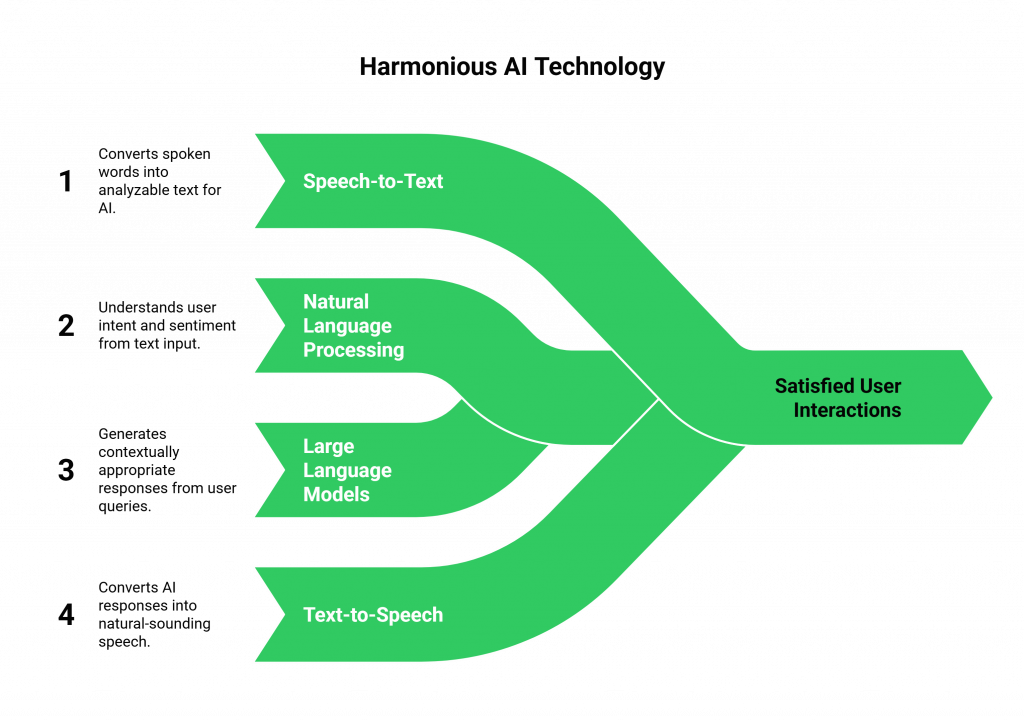
- Speech-to-Text (STT): This technology converts the user’s spoken words into text that the AI can analyze.
- Natural Language Processing (NLP): This is the core engine that allows the AI to comprehend the meaning, intent, and sentiment behind the user’s text input.
- Large Language Models (LLMs): Advanced models like OpenAI’s GPT series or Google’s Dialogflow process the query, access relevant information, and generate a contextually appropriate response in text format.
- Text-to-Speech (TTS): This technology converts the AI’s text response back into natural-sounding, human-like speech.
When these components operate with minimal delay, the result is a smooth, engaging conversation that mimics human interaction.
The Hidden Challenge: The Complex Infrastructure Layer
While many companies focus on selecting the best STT, LLM, and TTS providers, they often overlook the most difficult part of the equation: the voice transport infrastructure. This is the “plumbing” that connects a live phone call from the public telephone network to your AI services and back again in real-time.
Building this layer yourself presents significant technical and operational hurdles:

- Managing Telephony Carriers: Establishing relationships with telecom providers, managing phone numbers, and navigating complex regulations is a full-time job.
- Low-Latency Audio Streaming: A telephone call is a real-time media stream. You need to build infrastructure that can capture, transport, and play back audio with sub-second latency. Any delay creates awkward pauses that destroy the conversational flow.
- Handling Unstable Networks: Phone calls can suffer from packet loss and jitter. Your system must be resilient enough to handle these issues without dropping the call or degrading audio quality.
- Maintaining Call State: Your application needs to know at all times if a call is active, ringing, or has ended. Managing this dialogue state across a distributed system is non-trivial.
- Global Scalability: If you operate in multiple regions, you need a geographically distributed infrastructure to ensure low latency and high availability for all users.
Attempting to solve these challenges in-house diverts valuable engineering resources away from your core product. You end up spending more time becoming a telecom expert than an AI innovator.
FreJun: The Voice Transport Layer for Your AI Stack
FreJun solves this problem by providing a robust, developer-first voice API that handles the entire complex infrastructure layer. We are not an STT, TTS, or LLM provider. Instead, FreJun is the critical transport layer, the reliable “plumbing” that connects your chosen AI services to the global telephone network.
Our architecture is designed for one primary purpose: speed and clarity. Furthermore, we manage the complexities of real-time media streaming, call management, and global telephony so you can focus exclusively on building your real-time conversational AI agent. Therefore, with FreJun, you bring your own AI, and we make sure it can talk to the world.
How to Integrate Your AI with Phone Calls Using FreJun?
We have simplified the process of turning a text-based AI into a powerful voice agent into three straightforward steps. Your application maintains full control over the AI logic and conversational context at all times.
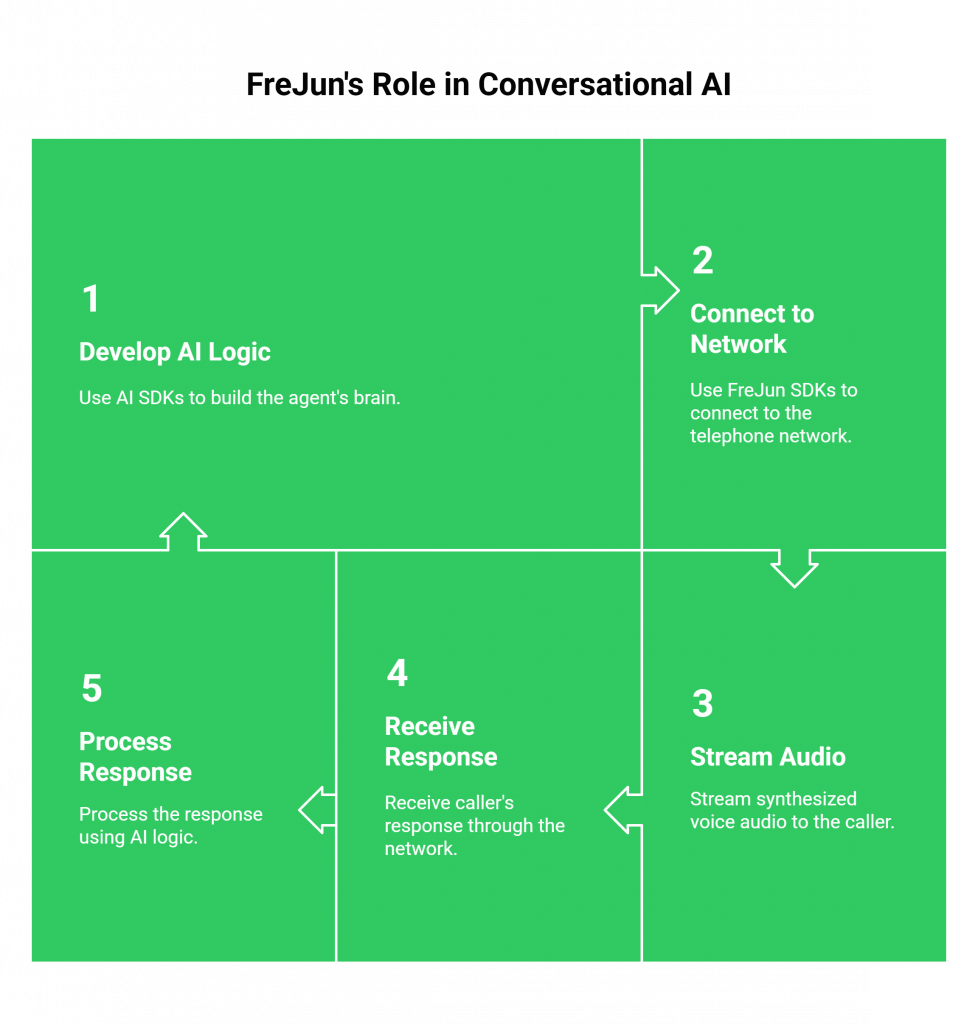
Step 1: Stream Voice Input
When a call is initiated or received, FreJun’s API captures the real-time, low-latency audio stream. This raw audio is securely streamed directly to your application, ensuring every word is captured with clarity and without delay.
Step 2: Process with Your AI
Your application receives the raw audio stream from FreJun. You then pipe this audio into your chosen Speech-to-Text (STT) service to get a transcription. This text is sent to your Large Language Model (LLM) for processing. FreJun acts as the reliable transport layer, while your application maintains complete control over the dialogue state and context management.
Step 3: Generate Voice Response
Once your LLM generates a text response, you send it to your preferred Text-to-Speech (TTS) service to create an audio file. You then pipe this response audio back to the FreJun API, which plays it back to the user over the call with minimal latency, completing the conversational loop.
Building Voice AI: The Hard Way vs. The FreJun Way
The difference between building from scratch and using a specialized voice transport layer is stark. A recent report from PWC notes that businesses see AI as a fundamental way to restructure their operations, with 54% of executives reporting improved productivity from AI implementations. FreJun accelerates this transformation by removing foundational roadblocks.
| Challenge | The Hard Way (Building In-House) | The FreJun Way (Using Our API) |
| Telephony Management | Source and manage phone numbers, negotiate with multiple telecom carriers, and handle complex regulations. | Instantly provision numbers via API. FreJun manages all carrier relationships and compliance. |
| Audio Streaming | Build and maintain a custom, low-latency WebRTC or SIP infrastructure to handle real-time audio. | Leverage FreJun’s battle-tested real-time media streaming infrastructure, optimized for speed and clarity. |
| Infrastructure Reliability | Engineer for high availability, manage servers, and create redundancy to prevent downtime. | Built on a resilient, geographically distributed infrastructure for guaranteed uptime and reliability. |
| Conversational Context | Develop complex logic to track the call state and manage the flow of the conversation across your systems. | FreJun maintains a stable connection, providing a reliable channel for your backend to manage context independently. |
| Latency Optimization | Manually optimize every component of the stack to minimize delays between speech, processing, and response. | Our entire stack is engineered to minimize latency, eliminating awkward pauses and enabling natural conversations. |
| Developer Focus | Engineering teams are diverted to solving complex telephony and infrastructure problems. | Developers focus on what they do best: building the AI logic and creating a great user experience. |
A Toolkit for Production-Grade Voice Applications
FreJun provides everything you need to move from concept to a production-grade real-time conversational AI solution, backed by robust infrastructure and developer-first tooling.
- Direct LLM & AI Integration: Our API is model-agnostic. This “bring your own AI” approach allows you to connect to any AI chatbot, LLM, STT, or TTS service you choose. You maintain full control over your AI logic while we manage the voice layer.
- Developer-First SDKs: Accelerate your development with our comprehensive client-side and server-side SDKs. Easily embed voice capabilities into your web and mobile applications and manage call logic on your backend with ease.
- Enable Full Conversational Context: FreJun acts as a stable and reliable transport layer for your voice AI. This provides a consistent channel for your backend systems to track and manage conversational context independently.
- Engineered for Low-Latency Conversations: Real-time media streaming is at the core of our platform. We have optimized our entire stack to minimize the latency between user speech, AI processing, and voice response, eliminating the awkward pauses that break conversational flow and frustrate users.
Powering the Next Generation of Voice Automation
With FreJun’s infrastructure, you can deploy sophisticated voice agents for almost any business need, turning the promise of real-time conversational AI into a practical reality. Gartner predicts that by 2026, one in ten agent interactions will be automated, a fourfold increase from 2022, underscoring the rapid shift toward AI-driven communication.
Intelligent Inbound Call Handling
Automate your front line with AI-powered agents that can operate 24/7.
- AI-Powered Receptionists: Greet callers, understand their needs in natural language, and route them to the correct person or department.
- 24/7 Customer Support: Answer complex customer queries, troubleshoot issues, and provide information without human intervention, drastically reducing wait times.
- Intelligent IVR Systems: Replace rigid, frustrating phone trees with conversational systems that understand natural language and resolve requests on the first try.
Scale and Personalize Outbound Campaigns
Execute outbound call campaigns that feel personal and engaging, not robotic.
- Automated Appointment Reminders: Place calls to confirm appointments with a natural, conversational voice.
- Lead Qualification: Automate the initial stages of lead qualification, asking key questions and scheduling follow-ups for your sales team.
- Feedback Collection and Surveys: Gather customer feedback at scale by conducting automated, conversational surveys.
Final Thoughts: Focus on AI, Not Infrastructure
The strategic advantage in the age of AI comes from speed, focus, and innovation. Furthermore, every hour your engineering team spends wrestling with telecom protocols, latency issues, and infrastructure management is an hour not spent improving your core AI product. Moreover, building a voice transport layer from scratch is an undifferentiated, heavy lift that consequently distracts from what truly matters: the quality of the conversation your AI delivers.
FreJun AI provides the definitive shortcut. By handling the complex voice infrastructure, we empower you to focus solely on building the best possible real-time conversational AI experience for your customers.
Our model-agnostic API, developer-first SDKs, and unwavering commitment to low-latency performance consequently make us the essential partner for any business serious about deploying production-grade voice agents.
The future of customer interaction is here, and it speaks. With FreJun AI, you can ensure your AI has a clear, reliable, and intelligent voice.
Further Reading – The Benefits of Using AI Insight for Call Management: A Comprehensive Guide
Frequently Asked Questions (FAQ)
No. FreJun is a voice transport layer. Our platform is model-agnostic, meaning you bring your own preferred STT and TTS services from providers like Google, Microsoft, ElevenLabs, or any other. We provide the infrastructure to stream audio to and from these services in real time.
No, and this is by design to give you maximum control. FreJun acts as the “plumbing” that connects a live phone call to your application. Your application’s backend code is responsible for making the API calls to your chosen LLM. This allows you to manage your AI logic, prompts, and context exactly how you want.
Our primary role is to handle the complex telephony and real-time media streaming infrastructure. We manage everything from phone number provisioning and call management to ensuring low-latency, high-quality audio transport, so you can focus on your AI application.
Our entire platform is architected for speed. We use a geographically distributed infrastructure to minimize distance-based latency and have optimized our media streaming protocols to ensure that audio is captured, transported, and played back with minimal delay, preventing the unnatural pauses that can ruin a conversational experience.
Yes. Because we provide the raw audio stream and accept response audio via our API, you can integrate with any STT, LLM, TTS, or other AI service that you choose. Our platform gives you the freedom to build your ideal AI stack without being locked into a specific vendor.
We offer dedicated integration support to ensure a smooth journey from day one. Our team of experts is available to assist with everything from pre-integration planning to post-integration optimization, helping you launch your real-time conversational AI solution successfully.