
Every spoken conversation depends on timing. Even a delay of half a second can make a caller wonder if the system stopped listening. This is why low-latency, real-time media streaming has become the foundation for building natural, human-like voice systems.
In modern communication, most applications record audio, process it, and respond later. Voice AI cannot afford that delay. It needs continuous, bidirectional audio exchange where every packet of sound moves almost instantly between the speaker, the network, and the processing system. That process is what we call real-time media streaming. Subjective studies (Interspeech) demonstrate that even modest transmission delays measurably reduce conversational interactivity and perceived quality, reinforcing the need for streaming designs that keep round-trip time low.
This article explains, in technical depth but plain language, how media streaming works, why it matters for voice AI, and how engineering teams can design for low latency. We will examine transport protocols, codec behavior, and pipeline flow so founders, product managers, and developers can make informed infrastructure decisions.
What Is Real-Time Media Streaming?
At its simplest, media streaming means sending audio or video over a network in small, continuous chunks rather than as one complete file. Traditional streaming, such as a movie on a platform, focuses on smooth playback and allows buffering.
Real-time media streaming, however, has a different goal – to reduce delay to the lowest possible level, usually below 500 milliseconds round-trip. In a real-time scenario, the application must send and receive audio frames almost instantly, enabling both participants or systems to speak and hear without noticeable lag.
Key technical characteristics
- Bidirectional flow: Audio data moves simultaneously in both directions.
- Session-based transport: Uses protocols like RTP (Real-time Transport Protocol) or WebSockets for continuous packet exchange.
- Packetization: Voice signals are broken into frames of 10–60 ms each.
- Low buffering: Buffers hold only enough data to compensate for network jitter.
- Continuous synchronization: Timestamps ensure that speech order remains correct even if some packets arrive late.
Because of these features, real-time media streaming behaves more like a live phone call than a downloaded file. When connected with speech recognition, text generation, and speech synthesis engines, it enables a complete interactive voice loop.
How Media Streaming Works Behind the Scenes
Understanding how media streaming in AI works requires following the audio path from capture to playback. The process looks simple from outside, yet several tightly timed components keep the experience smooth.
Step 1: Capture the Voice Input
The microphone or telephony interface captures audio waves and digitizes them. Most systems sample at 8 kHz (G.711 narrowband) or 16 kHz (OPUS wideband). The captured frames are packaged into small packets and sent immediately to the network.
Step 2: Encode and Transport Audio
Encoding compresses voice data using codecs such as:
| Codec | Bitrate | Typical Use | Notes |
| G.711 (PCMU/PCMA) | 64 kbps | PSTN calls | Simple, robust |
| OPUS | 8–64 kbps | WebRTC apps | Low latency, high quality |
| PCM (L16) | 128 kbps | Studio-grade audio | Uncompressed |
Packets travel using:
- RTP over UDP: Lightweight and time-sensitive; common in SIP or VoIP.
- WebSocket streams: Used for AI applications needing event-based bidirectional communication.
- SRTP (Secure RTP): Adds encryption for privacy-sensitive deployments.
Step 3: Process the Stream in Real Time
The stream enters the application’s audio pipeline:
- Speech-to-Text (STT) converts the raw audio frames into partial transcripts.
- Language model or logic engine interprets those transcripts and decides the next response.
- Text-to-Speech (TTS) synthesizes the reply into an audio stream.
All these actions happen concurrently. While STT processes the latest frames, TTS may already start generating output for previous segments.
Step 4: Return the Response Audio
The newly generated speech is streamed back over the same session. Because both directions operate continuously, the user perceives a natural dialogue without waiting for long processing gaps.
Data flow overview
Caller – Media Stream – STT – LLM/Logic – TTS – Media Stream – Caller
This constant flow differentiates real-time media streaming from request-response APIs. Instead of discrete transactions, it maintains an open channel optimized for voice continuity.
Media Streaming in AI – Turning Text Models into Voice Agents
Most large language models are built for text. They read tokens, reason, and write words. To make them speak and listen, we need three bridges: STT, TTS, and streaming transport.
Without media streaming in AI, an application would have to record full sentences, send them for transcription, wait for the model to respond, and then play the entire synthesized audio. This would create unnatural pauses and interrupt conversation flow.
With real-time media streaming:
- The STT engine sends partial results as the user speaks.
- The AI logic starts generating replies before the sentence finishes.
- The TTS system converts each phrase into small audio chunks and streams them back instantly.
This pipeline transforms a text-based model into a responsive voice participant that reacts nearly as fast as a human.
The AI Voice Stack in Simple Form
| Layer | Role | Example Technologies |
| Capture | Microphone / SIP gateway | WebRTC, Twilio Media Streams |
| Transport | Real-time media stream | RTP, WebSocket |
| STT | Speech-to-text conversion | Whisper, Deepgram, Google STT |
| Core Logic | Reasoning / Context | Any LLM or agent framework |
| RAG & Tools | External data or API calls | Vector DBs, CRM, REST APIs |
| TTS | Speech generation | Play.ht, ElevenLabs, Azure TTS |
| Playback | Return to caller | Telephony gateway / VoIP client |
Together these components form a streaming-native voice AI system. When tuned correctly, it handles thousands of simultaneous sessions while maintaining smooth, conversational response times.
Why Low-Latency Streaming Matters for Voice AI
Latency determines whether a dialogue feels real. Humans start noticing gaps longer than 250–300 milliseconds. Anything above 500 ms makes interactions feel robotic. That is why the benefits of low-latency streaming are both technical and behavioral.
Human Perception Thresholds
| Delay (ms) | User Experience |
| < 150 | Seamless real-time conversation |
| 150 – 400 | Slight pause, still comfortable |
| > 400 | Noticeable lag, conversation feels broken |
Key Technical Factors Affecting Latency
- Codec choice:
- G.711 is simple but bandwidth-heavy.
- OPUS adapts bitrate dynamically, keeping quality high with less delay.
- L16 offers top fidelity when network bandwidth is abundant.
- G.711 is simple but bandwidth-heavy.
- Packet size: Smaller packets (10–20 ms frames) reduce delay but add header overhead.
- Jitter buffers: These smooth network variations but should stay under 50 ms to avoid extra lag.
- Network path: Fewer hops mean lower round-trip time (RTT).
- Processing queue: STT, AI, and TTS pipelines must work in parallel instead of sequentially.
Practical Design Tips for Low Latency
- Use asynchronous STT that emits partial transcripts continuously.
- Select streaming TTS that supports chunked playback.
- Keep audio buffer sizes small and dynamic.
- Prefer geographically distributed media servers for regional call routing.
- Implement end-to-end monitoring to measure each component’s delay.
By following these principles, teams can maintain < 400 ms average latency, which matches the comfort zone for human speech exchange.
Benefits of Real-Time Media Streaming for Voice AI Applications
Because streaming delivers audio with minimal delay, it changes how products behave and how users respond.
Technical Benefits
- Continuous dialogue: Systems listen and speak simultaneously.
- Improved accuracy: STT models perform better with immediate feedback.
- Lower bandwidth usage: Streaming uses compressed frames instead of full files.
- Scalable architecture: Easier to handle many concurrent sessions through event-driven pipelines.
- Better resource utilization: GPU and CPU load spread evenly because processing is continuous.
Business Benefits
- Faster customer responses – higher satisfaction.
- Reduced infrastructure cost compared to batch processing.
- Easier integration with existing voice systems (PBX, SIP, VoIP).
- Flexibility to connect with any AI model or cloud provider.
Every millisecond saved translates into a conversation that feels more human and a system that handles load more efficiently. For founders and engineering leaders, understanding these benefits is critical when planning voice-enabled products.
Want to see how Teler powers AgentKit’s intelligent agents with seamless voice capabilities? Read our deep dive on AgentKit integration.
Common Challenges in Media Streaming Pipelines
Even though real-time media streaming is powerful, building a stable pipeline can be difficult. The following issues appear frequently and must be managed carefully.
- Latency spikes due to network jitter or improper buffer settings.
- Codec mismatch between different endpoints requiring transcoding, which adds processing time.
- Synchronization errors when timestamps drift between incoming and outgoing streams.
- Security concerns because live audio contains sensitive data that needs encryption.
- Limited observability when telemetry does not cover every stage of the pipeline.
Addressing these issues early through proper protocol selection, monitoring, and testing ensures a consistent user experience.
Real-World Use Cases Enabled by Real-Time Streaming
Real-time media streaming is not just a technical concept; it drives many AI-enabled applications already in production.
- AI Receptionists and IVRs handle calls 24/7 with natural conversation flow.
- Agent assist tools analyze live speech and suggest responses to human operators.
- Proactive outbound campaigns deliver personalized messages at scale.
- Voice analytics and sentiment tracking use live audio streams for real-time insights.
- Language translation calls stream audio to multilingual models for instant speech-to-speech conversion.
Each of these use cases relies on the same core principles – continuous audio capture, low-latency transport, and streamed synthesis of responses.
Bringing It All Together – Why Voice AI Needs a Dedicated Streaming Infrastructure
Designing a real-time voice agent is not only about connecting APIs. It’s about synchronizing multiple asynchronous systems – speech recognition, language models, and synthesis engines – while maintaining sub-second response times.
For founders and product teams, this creates a clear challenge:
- STT engines like Deepgram or Whisper produce partial results at varying speeds.
- LLMs such as GPT or Claude process text token-by-token.
- TTS systems generate waveform chunks differently depending on the model.
Without a dedicated streaming infrastructure, you end up building your own media routing, buffering, and synchronization layer – a task that is both expensive and time-consuming. This is where purpose-built platforms like FreJun Teler make a real difference.
Introducing FreJun Teler – The Voice Infrastructure Layer for AI
FreJun Teler acts as the missing bridge between LLMs and real-world voice conversations.
It enables developers to implement real-time, two-way media streaming between any AI engine and telephony endpoints – all with enterprise-grade reliability and low latency.
Core Technical Capabilities
- Programmable SIP and WebRTC endpoints: Create and manage inbound or outbound calls directly from your app or AI agent.
- Real-time media streaming APIs: Stream live audio frames in both directions for immediate STT and TTS processing.
- Model-agnostic architecture: Works with any STT, TTS, or LLM provider – whether open-source or commercial.
- Ultra-low latency transport: Optimized RTP and WebSocket-based pipelines for <400 ms response time.
- Context persistence: Maintains session context across the entire dialogue, so your AI never “forgets” during multi-turn calls.
Simplified Implementation Workflow
| Stage | Action | Teler Component |
| Call Setup | Initiate SIP or WebRTC session | Programmable Voice API |
| Audio Capture | Stream caller audio | Media Stream Channel |
| Processing | STT + LLM + TTS handled by your AI | AI Logic Layer |
| Response Delivery | Stream synthesized audio back | Bidirectional Media Stream |
| Logging & Insights | Track call events and latency metrics | Analytics Layer |
This means you can integrate Teler + Any LLM + Any STT/TTS engine to build a fully functional, low-latency voice system – without managing telephony, codecs, or networking yourself.
How Teler Enhances Real-Time Media Streaming for AI Voice
Let’s look under the hood at how FreJun Teler optimizes the technical workflow:
A. Seamless STT – AI – TTS Pipeline
Instead of processing audio in sequence, Teler enables parallel streaming:
- Incoming audio is continuously sent to the STT engine.
- Partial transcripts are relayed to your LLM via API or socket.
- The AI’s text output is instantly forwarded to a TTS engine.
- Generated audio chunks return through the same open media session to the caller.
This stream-pipelined design ensures that the user hears partial responses almost instantly, similar to natural human speech overlap.
B. Latency Control at Every Layer
Teler applies real-time optimizations across:
- Packetization: Configurable frame size (e.g., 20 ms) to balance jitter vs. overhead.
- Buffer management: Adaptive buffering based on live network metrics.
- Codec negotiation: Auto-selects optimal codec (OPUS, G.711, PCM) per connection.
- Proximity routing: Uses globally distributed media servers for the lowest path delay.
C. Scalability and Fault Tolerance
- Horizontal scaling for thousands of concurrent streams.
- Automatic session recovery in case of transient network errors.
- Built-in observability through latency metrics, call traces, and health checks.
These capabilities mean engineering leads can rely on Teler as a real-time media transport backbone – not just a simple calling API.
Comparing Traditional Telephony vs. AI-Native Streaming
| Parameter | Traditional VoIP / PBX | AI-Native Streaming via Teler |
| Audio Direction | Unidirectional or full-duplex but human-only | Bidirectional AI ↔ Human |
| Processing Mode | Buffered, post-call analytics | Live, token-by-token |
| Latency Focus | Acceptable up to 800 ms | Target < 400 ms |
| AI Integration | External, after the call ends | Inline, during live conversation |
| Context Handling | Stateless | Persistent dialogue context |
| Scalability | Limited by server channels | Event-driven, scalable by design |
This table highlights the fundamental difference:
Traditional systems transmit voice; AI-native streaming systems understand and respond in real time.
Why Founders and Engineering Leaders Should Care
Real-time media streaming directly impacts the core business metrics of any voice product – speed, accuracy, and scalability. Let’s look at why it matters strategically.
A. Faster Time to Market
Building a media streaming stack internally requires months of protocol handling, transcoding, and network optimization. Teler’s ready infrastructure shortens deployment cycles dramatically, allowing teams to focus on model performance and conversational design instead of telephony management.
B. Reduced Engineering Overhead
Teler manages signaling, session control, and scaling automatically. This eliminates the need for:
- RTP/UDP socket management
- Audio transcoding pipelines
- Geo-routing logic
- Real-time call monitoring dashboards
C. Improved User Retention
Because of its low-latency streaming, users experience smoother conversations with fewer awkward pauses – leading to longer engagement and higher satisfaction rates.
D. Platform Agnosticism
Unlike platforms tied to a specific cloud provider or model, Teler integrates seamlessly with open-source tools, in-house models, or any external AI service. This flexibility ensures future-proof architecture as technology evolves.
Sign Up with FreJun Teler Today!
How to Architect a Voice AI System with Teler
To implement Teler + LLM + STT/TTS, teams can follow this simple yet technically precise structure:
[Caller]
↓
[Teler Media Stream]
↓
[Speech-to-Text Engine] – [Language Model / RAG / Tool Calling] – [Text-to-Speech Engine]
↑ ↓
└───────────────────────<────────────── Stream Response ─────┘
Detailed Breakdown
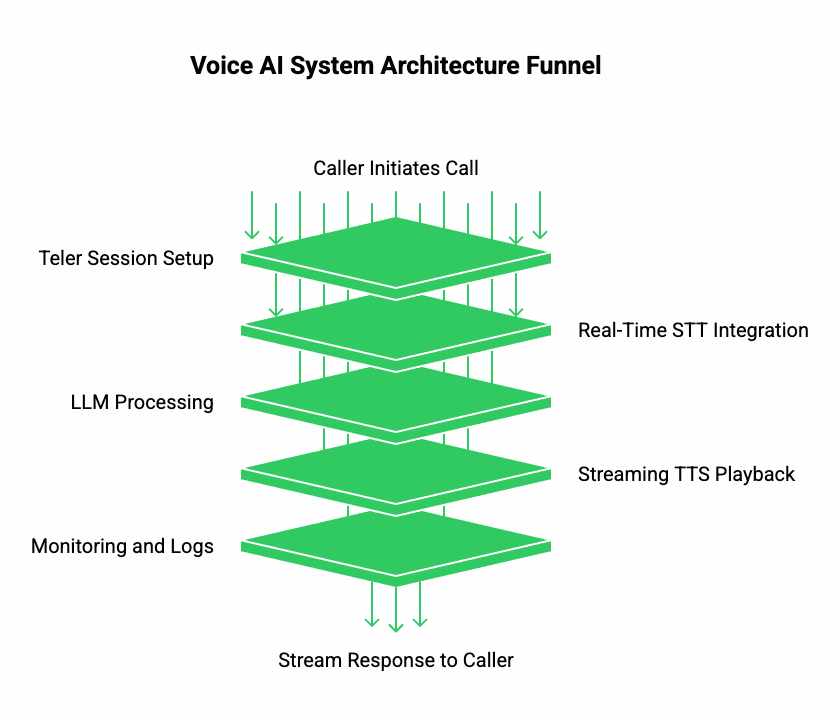
- Teler Session Setup:
- A call or voice connection starts using Teler’s programmable SIP/WebRTC endpoint.
- Audio stream immediately opens through Teler’s media API.
- A call or voice connection starts using Teler’s programmable SIP/WebRTC endpoint.
- Real-Time STT Integration:
- Each audio packet goes to your chosen STT engine (e.g., Whisper, Deepgram).
- Partial transcripts flow to your LLM endpoint without waiting for full sentences.
- Each audio packet goes to your chosen STT engine (e.g., Whisper, Deepgram).
- LLM Processing:
- The LLM generates responses incrementally (streamed token output).
- Optional RAG (Retrieval Augmented Generation) and tool calling can enrich the answer with contextual data.
- The LLM generates responses incrementally (streamed token output).
- Streaming TTS Playback:
- The AI’s textual response is converted to audio chunks in real time.
- These chunks are sent back through the same Teler stream to the caller.
- The AI’s textual response is converted to audio chunks in real time.
- Monitoring and Logs:
- Latency metrics, packet loss, and stream duration are tracked through Teler’s dashboard.
- Latency metrics, packet loss, and stream duration are tracked through Teler’s dashboard.
By separating media transport from AI logic, the system stays modular and easy to scale or migrate across providers.
Security, Compliance, and Reliability Considerations
When working with voice data, privacy and uptime are non-negotiable.
Teler’s infrastructure integrates essential safeguards that technical teams can build upon.
Security Layers
- End-to-end encryption using SRTP and TLS for all media and signaling.
- Role-based access controls to limit stream access per API key.
- Data retention policies configurable per deployment.
Compliance
Supports regional privacy laws such as GDPR and India’s DPDP Act through configurable storage zones and consent management features.
Reliability
- 99.99% uptime SLA.
- Geo-distributed media nodes across North America, Europe, and APAC.
- Automatic fallback routing for ongoing sessions in case of node failure.
For enterprise-grade deployments, these capabilities ensure business continuity and user trust.
The Future of Real-Time Media Streaming in Voice AI
Real-time media streaming is evolving beyond simple audio transport.
Emerging trends show deeper integration between voice, context, and computation:
- Edge-based inference: Running STT and TTS closer to the media server to cut latency below 200 ms.
- Dynamic codec switching: Automatically adjusting quality based on network conditions.
- Adaptive conversation flow: AI adjusting tone and speaking speed based on live acoustic feedback.
- Unified multimodal streaming: Merging audio, text, and video streams for richer interactions.
Platforms like FreJun Teler are positioned to support these advancements by offering a stream-first infrastructure, rather than retrofitting traditional telephony for AI.
Key Takeaways – Why Real-Time Media Streaming Matters
| Aspect | Traditional Systems | Real-Time Media Streaming |
| Interaction Style | Record – Process – Respond | Continuous dialogue |
| Latency | 700–1000 ms typical | < 400 ms achievable |
| User Experience | Delayed, robotic | Natural, human-like |
| Infrastructure | Static PBX / VoIP | Dynamic, API-driven |
| Scalability | Channel-limited | Event-driven scaling |
In Summary
- Real-time media streaming is the foundation that allows AI to speak and listen naturally.
- Low-latency communication unlocks real human-like dialogue and reduces drop-offs.
- FreJun Teler simplifies implementation by handling the heavy lifting – media routing, latency control, and scalability – so teams can focus on their AI’s intelligence rather than call transport.
The next generation of voice AI systems will be defined not by how smart the models are, but by how quickly and seamlessly they can converse – and that depends entirely on real-time media streaming.
Conclusion
Voice-driven AI is no longer a futuristic concept—it’s fast becoming the core of how modern businesses communicate. Every millisecond saved in transmission or response amplifies user satisfaction, trust, and operational efficiency. Real-time media streaming is what transforms static automation into living, conversational intelligence. With FreJun Teler, teams can build on a reliable, ultra-low-latency foundation that seamlessly connects AI engines, voice APIs, and communication channels. Whether you’re designing virtual agents, smart IVRs, or voice-enabled workflows, Teler ensures your interactions feel human in real time.
Ready to experience it firsthand? Schedule a free demo with FreJun Teler and explore how your product can sound truly alive.
FAQs –
- What is real-time media streaming?
It’s continuous transmission of audio data allowing instant voice interaction between users and AI without buffering or delay. - How does media streaming work in Voice AI?
It sends and receives audio in small data packets, ensuring low-latency communication between speech engines and AI models. - Why is low latency important for AI conversations?
Low latency makes AI responses feel natural, reducing awkward pauses and improving user trust and conversation flow. - Can I use any AI model with Teler?
Yes, Teler is model-agnostic and integrates seamlessly with any LLM, STT, or TTS provider you prefer. - Is real-time streaming secure?
Yes, Teler uses encrypted media transport (SRTP/TLS) and compliance frameworks like GDPR to ensure data safety. - Does Teler support both inbound and outbound calls?
Absolutely. Teler’s programmable SIP endpoints allow two-way streaming for both inbound and outbound voice communication. - What latency can I expect with Teler?
Teler’s optimized streaming pipeline achieves sub-400ms round-trip latency under normal network conditions globally. - How is media streaming different from VoIP?
VoIP focuses on transmitting voice; media streaming enables real-time AI interaction, processing, and response during live calls. - Can Teler scale for enterprise-level voice AI applications?
Yes, Teler’s infrastructure supports thousands of concurrent sessions with auto-scaling and fault tolerance built-in. - How can I get started with FreJun Teler?
You can start free and integrate in minutes – schedule a demo here.