
Building accurate voice agents is no longer optional – it is a competitive necessity. As businesses shift from text chatbots to real-time conversations, the challenge is to combine natural language generation with factual reliability.
This blog explores how Retrieval-Augmented Generation (RAG) can be applied to voice agents to ensure accuracy at scale. We will break down the voice pipeline, highlight implementation best practices, and explain how retrieval transforms a standard system into a trusted voice API for developers.
For teams evaluating the top programmable voice AI APIs with low latency, this guide offers both strategy and technical depth.
Why Does Accuracy Matter in AI Voicebots?
Accuracy is the backbone of any AI voicebot. When users interact through voice, expectations are different from text. In a chat window, people tolerate a second of delay or may even overlook a minor error. On a live call, the tolerance disappears. A single mistake disrupts the flow and damages trust immediately.
For businesses, this means:
- Every pause or incorrect answer directly impacts customer satisfaction.
- Wrong information can create compliance risks, especially in industries like finance or healthcare.
- If users feel the agent is unreliable, adoption rates fall, and the cost of human intervention rises.
A voice agent is only valuable when it answers correctly, quickly, and consistently. This is why accuracy is not just a technical metric but a business priority. Retrieval-Augmented Generation (RAG) is the method that helps achieve this standard.
What Is Retrieval-Augmented Generation (RAG) and Why Do Voice Agents Need It?
Large language models are powerful, but they are trained on static data. They excel at generating natural language but struggle with precision when a question requires current or domain-specific knowledge.
RAG is a way of grounding these models in real information at runtime. It combines two steps:
- Retrieving relevant content from an external knowledge base or database.
- Supplying that content to the model to guide its answer.
In practice, RAG makes the difference between a generic reply and a factually correct one. For voice agents, this matters even more because the conversation is real-time.
Consider a customer asking an AI voicebot about their bank account fee waiver. Without RAG, the model might guess based on general banking knowledge. With RAG, it retrieves the actual bank policy and gives a precise answer.
This retrieval step ensures that the voice agent does not just sound human but also behaves like a reliable source of information. In a 2025 clinical-study, integration of RAG improved LLM accuracy by about 39.7 % on average, with top models such as LLaMA-3 achieving around 94-95 % accuracy once RAG and agent enhancements were applied.
How Does a Voice Agent Work With RAG in the Loop?
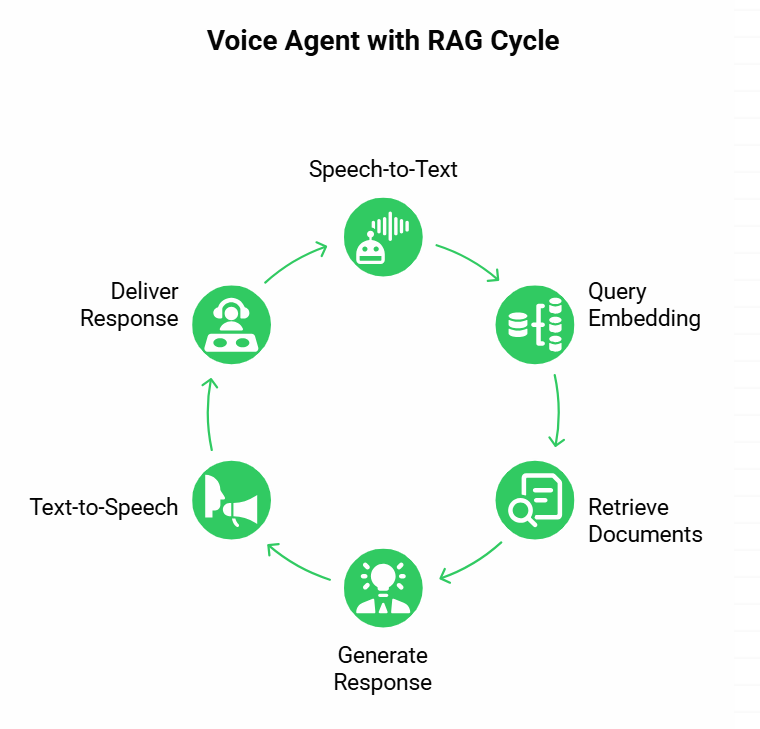
To understand how RAG improves accuracy, it helps to break down the voice agent pipeline. A working system generally follows these stages:
- Speech-to-Text (STT) transcribes the caller’s audio into text.
- The text query is converted into an embedding and sent to a vector database.
- The database returns the most relevant documents or knowledge chunks.
- The language model (LLM) uses the retrieved content to generate a grounded response.
- Text-to-Speech (TTS) converts the response back into audio.
- The caller hears the response almost instantly.
This loop happens in fractions of a second, and RAG sits at the center. Without it, the LLM would rely only on its pretraining, often producing generic or misleading answers. With RAG, the answer is backed by actual knowledge.
A simple example:
- User says, “What is my order delivery status?”
- STT transcribes the speech.
- Retrieval layer queries the logistics database.
- The model responds: “Your package is out for delivery and should arrive by 6 pm today.”
- TTS speaks it back naturally to the user.
The presence of RAG ensures the answer is not just fluent but also factually correct.
What Are the Biggest Challenges in Combining RAG With Voice LLMs?
While the architecture seems straightforward, implementing RAG in a voice pipeline introduces unique technical hurdles.
Latency requirements
In voice interactions, users expect near-instant responses. Anything more than a second feels unnatural. Adding retrieval increases processing time. To keep conversations natural, teams must optimize each component: faster speech recognition, efficient vector search, and streaming responses.
Handling noisy input
Voice queries are rarely clean. Users pause, repeat, or add filler words. Traditional search can fail if it matches exact text. This is why embeddings and semantic search are crucial. They allow the retrieval system to find meaning even in imperfect transcripts.
Context window management
Language models have limits on how much text they can process at once. If too many documents are retrieved, the response slows down or loses focus. Smart chunking, reranking, and summarization strategies are needed to feed only the most relevant pieces into the model.
Domain adaptation
Voice agents often work in specialized domains like healthcare or legal. Indexing the right documents and updating them regularly ensures the retrieval step remains useful. Without domain adaptation, the system may still produce fluent but irrelevant answers.
These challenges are not blockers, but they define the difference between a prototype and a production-grade solution.
Discover practical methods to reduce latency in voice AI conversations and keep your RAG-powered voice agents fast and responsive.
How Do You Implement RAG in a Voice Agent Step by Step?
Building a RAG-powered voice agent involves aligning multiple moving parts. A simplified process looks like this:
Step 1: Prepare the data
- Collect documents, FAQs, manuals, or records.
- Split them into smaller chunks that are easier to search.
- Convert these chunks into embeddings and store them in a vector database.
Step 2: Process the user query
- Use an STT engine to convert speech into text.
- Clean and normalize the text (remove pauses, filler words).
- Convert the text into an embedding for retrieval.
Step 3: Retrieve relevant content
- Query the vector database for semantically similar documents.
- Use hybrid search (semantic plus keyword) for better precision.
- Rerank the results so only the most useful ones are passed to the model.
Google researchers found that with optimized prompt engineering and retrieval strategy, they could classify queries as having ‘sufficient context’ 93 % of the time, meaning retrieval returns were reliably strong enough to ground the model’s response.
Step 4: Generate grounded response
- Pass the query and retrieved content to the LLM.
- Structure the prompt so the model is encouraged to stick to the retrieved knowledge.
- Use streaming to generate the answer incrementally, which reduces perceived delay.
Step 5: Convert to audio
- Send the model output to a TTS system.
- Play the synthesized speech back to the caller in real time.
By following these steps, businesses can build voice agents that are both natural and accurate. The retrieval step transforms the system from a generic responder into a trusted assistant.
How Can You Measure Accuracy in a RAG-Powered Voice LLM?
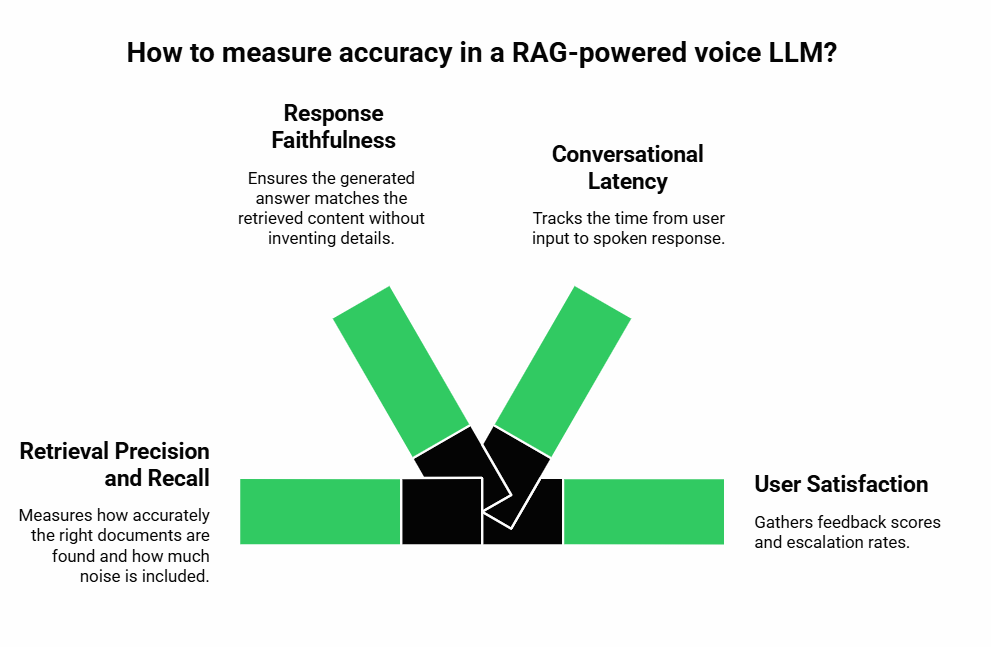
Accuracy is not a single measure. It involves both retrieval and generation performance. Companies must track multiple dimensions:
- Retrieval precision and recall: How often the right documents are found and how much noise is included.
- Response faithfulness: Whether the generated answer matches the retrieved content without inventing details.
- Conversational latency: Time from user input to spoken response. Lower latency improves perceived accuracy.
- User satisfaction: Feedback scores and escalation rates.
Testing should compare scenarios with and without RAG to quantify improvements. For example, in a pilot project, a bank may find that escalation rates dropped by 40 percent after introducing RAG because the voicebot gave more reliable answers.
Continuous monitoring is also important. Over time, knowledge bases evolve, and retrieval pipelines must be updated to stay aligned.
Why Use Teler for Building Accurate Voice Agents With RAG?
Up to this point, we have looked at the technical pieces needed to build a RAG-powered voice agent. But while the retrieval and generation layers strengthen accuracy, one challenge remains constant: the voice infrastructure itself.
Running real-time audio streams over phone networks or VoIP while keeping latency under control is complex. If the transport layer adds even half a second of delay, the conversation feels unnatural no matter how accurate the response is.
This is where Teler plays a critical role.
- Real-time voice streaming: Teler captures live audio from any call and streams it to your AI stack with minimal latency.
- Model-agnostic integration: You can connect any speech-to-text engine, any retrieval layer, and any voice LLM. Teler does not force you into a specific model or ecosystem.
- Resilient infrastructure: Built on a globally distributed network, it ensures that conversations remain stable and consistent, even at scale.
- Developer-first design: SDKs make it simple to integrate Teler into web or mobile applications, while your backend remains in full control of the AI logic.
By handling the voice transport layer, Teler allows product teams to focus on the harder problem – designing accurate retrieval and response flows. In other words, Teler makes sure your RAG-powered AI voicebot is not only accurate but also usable in a real-world, enterprise-grade environment.
Confused between programmable voice APIs and cloud telephony? Read our detailed comparison to choose the right infrastructure for voice agents.
What Are the Best Use Cases for RAG-Powered Voice Agents?
Accuracy-driven voice agents are not just a theoretical concept; they solve real problems across industries. Below are a few use cases where RAG brings clear advantages.
Customer Support
- Traditional IVR systems frustrate callers with rigid menus.
- A voice agent powered by RAG can pull answers directly from a company’s knowledge base.
- Customers receive clear, factual replies without waiting for a human agent.
Outbound Campaigns
- Appointment reminders or policy updates often change frequently.
- RAG ensures the voice agent always delivers the most recent information, retrieved at call time.
- This prevents outdated or contradictory responses.
Healthcare
- Patients asking about medication schedules or insurance coverage need precise, regulated answers.
- A RAG-enabled voice LLM can retrieve the exact information from approved medical guidelines or policy documents.
- This improves both safety and compliance.
Finance and Banking
- Customers calling about account balances, loan terms, or regulatory updates expect accuracy.
- Retrieval ensures the AI voicebot references live systems or compliance documents rather than relying on generic data.
These examples demonstrate that whenever the cost of error is high, RAG becomes essential.
How Can You Scale a RAG-Enabled AI Voicebot for Enterprise Use?
Launching a prototype is relatively simple. Scaling it for enterprise-grade reliability requires careful planning.
Optimize Retrieval Workflows
- Use caching for frequent queries to reduce load on the vector database.
- Implement hybrid search that combines semantic embeddings with keyword-based filters.
- Rerank results to minimize irrelevant retrievals.
Manage Cost and Efficiency
- Vector databases can become expensive at scale. Sharding, tiered storage, and approximate search techniques help control costs.
- Monitor usage patterns to allocate resources efficiently.
Ensure Compliance and Security
- For industries like healthcare or finance, ensure all data used in retrieval is encrypted and access-controlled.
- Implement audit logging so retrieval steps can be traced and verified.
- Follow data residency regulations if deploying across regions.
Monitor System Health
- Track latency at every step: STT, retrieval, LLM, TTS.
- Build dashboards that visualize retrieval precision and user satisfaction.
- Detect drift in embeddings if domain-specific data evolves over time.
Enterprises should view voice agents not as static products but as living systems that must be continuously tuned.
What Is the Future of Voice LLMs and RAG?
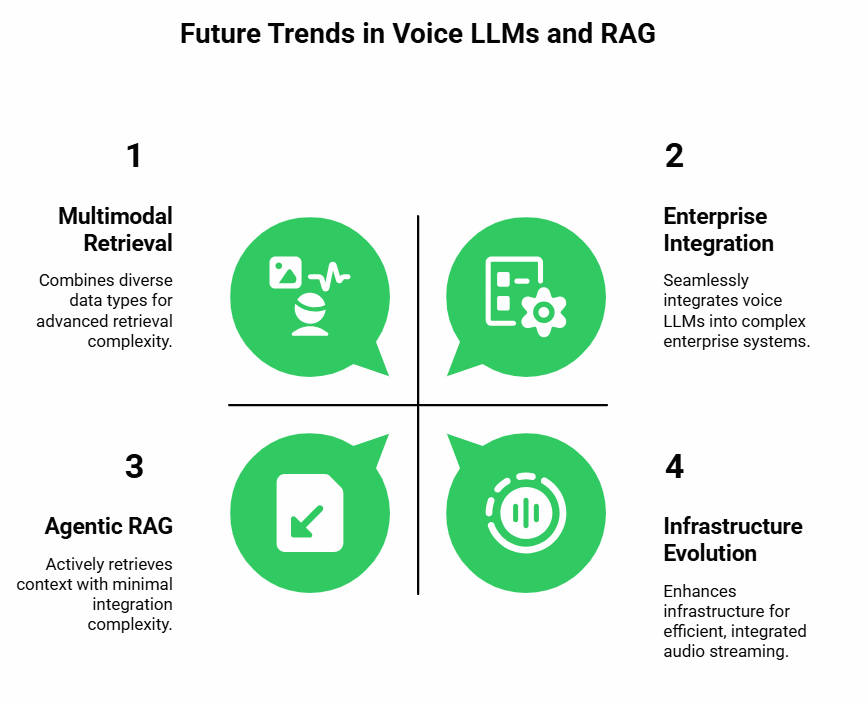
The field is moving quickly, and several trends are emerging.
Agentic RAG
Instead of passively retrieving documents, newer approaches allow the system to actively decide when and how to retrieve, re-querying until it gets the right context. This reduces error rates and makes responses more reliable.
Context Engineering
For multi-turn conversations, it is not enough to retrieve once. Context engineering methods maintain dialogue state and ensure that retrieval happens with awareness of the entire conversation. This will make voice agents sound more consistent across long calls.
Multimodal Retrieval
Voice is only one input. In the future, retrieval may combine voice transcripts, documents, video captions, or even images. A voice agent that can reference multiple types of knowledge will become significantly more powerful.
Enterprise Integration
Voice LLMs will not remain standalone tools. They will be embedded directly into CRM systems, healthcare records, financial platforms, and logistics dashboards. RAG will act as the bridge between unstructured conversations and structured enterprise data.
Infrastructure Evolution
The demand for low-latency, global-scale audio streaming will grow. Solutions like Teler will be increasingly critical because infrastructure is as important as model intelligence in voice-first systems.
How Do You Get Started With RAG-Powered Voice Agents Today?
To recap the journey:
- Accuracy is essential for AI voicebots because users interact in real time and errors damage trust.
- RAG strengthens accuracy by grounding responses in live, domain-specific knowledge.
- The implementation requires careful handling of latency, retrieval quality, and evaluation metrics.
- Scaling to enterprise requires monitoring, compliance, and optimization.
- Infrastructure platforms like Teler make it possible to deploy voice agents in production without building complex telephony systems in-house.
If you are a founder, product manager, or engineering lead, the path forward is clear:
- Start with a pilot that integrates STT, RAG, LLM, and TTS.
- Use a small dataset to validate improvements in accuracy.
- Introduce Teler as the voice infrastructure layer to handle real-time calling at scale.
- Expand gradually into more domains and higher concurrency once accuracy is stable.
The voice-first future will belong to those who combine strong retrieval strategies with reliable infrastructure. By starting early, businesses can position themselves at the forefront of customer experience, automation, and efficiency.
Conclusion
Accuracy is the single most important factor in whether AI voice agents gain user trust and deliver measurable business value. Retrieval-Augmented Generation ensures that responses are not only natural but grounded in real, domain-specific knowledge. When combined with the right stack – speech recognition, retrieval, language model, and text-to-speech – you can create voice LLMs that operate at enterprise standards. The missing piece has always been reliable, low-latency voice infrastructure.
Teler solves this challenge by providing a global backbone for streaming conversations in real time. This allows your teams to focus on building accurate, customer-centric applications without worrying about telephony complexity.
Ready to take the next step? Schedule a demo with Teler and start building RAG-powered voice agents today.
FAQs –
1. How does RAG improve the accuracy of AI voicebots?
RAG retrieves real knowledge during calls, grounding responses in facts. This reduces hallucinations and ensures AI voicebots deliver reliable, domain-specific answers.
2. What latency is acceptable for real-time voice LLM conversations?
Users notice delays above 250 milliseconds. Keeping round-trip latency under 200 milliseconds is essential for natural, responsive real-time voice LLM conversations.
3. Can any developer integrate RAG into a voice API pipeline?
Yes. With programmable voice APIs, developers can connect STT, retrieval, LLM, and TTS layers to implement effective RAG-powered voice agents.
4. Why choose a programmable voice API over standard cloud telephony?
Programmable voice APIs offer low-latency, flexible integrations for AI agents, unlike traditional cloud telephony, which lacks real-time conversational optimization.