
When architecting a state-of-the-art AI voice agent, developers are tasked with assembling a “dream team” of specialized components. The goal is to create an experience that is not only intelligent but also remarkably human. In this pursuit, two names consistently stand out as best-in-class for their respective functions: Play.ai and AssemblyAI.
However, putting these two platforms head-to-head in a direct Play.ai vs Assemblyai.com comparison often stems from a misunderstanding of their roles. This is not a choice between two competing services; it’s an architectural decision about which best-in-class components to use. One provides the perfect “voice,” while the other provides the perfect “ears.”
This guide will provide a detailed, feature-by-feature breakdown to clarify the distinct and complementary functions of these two powerful platforms. More importantly, it will reveal the essential foundation you need to unite their capabilities to create a truly seamless and responsive voice agent.
Table of contents
The Anatomy of a Voice Agent: Mouth, Ears, and Brain
To understand the roles of Play.ai and AssemblyAI, you first need to break down how a conversational AI functions:
- The Ears (Speech-to-Text – STT): This is the first step in a conversation. The system must listen to a user’s spoken words and accurately transcribe them into text. This is where AssemblyAI lives. Its core function is to hear and understand.
- The Brain (Large Language Model – LLM): This is the intelligence layer (e.g., GPT-4, Llama 3). It takes the transcribed text, processes the user’s intent, and generates a logical, text-based response.
- The Mouth (Text-to-Speech – TTS): This is the final step. The system takes the LLM’s text response and converts it into audible, human-like speech. This is where Play.ai lives. Its core function is to speak with clarity and realism.
As you can see, they are not competitors for the same job. They are two essential, non-overlapping components of a complete voice AI stack.
Play.ai (The Mouth)
Play.ai is a top-tier generative voice AI and Text-to-Speech platform. Its primary role is to speak with stunning realism.

Key Features & Strengths
- Ultra-Realistic Voice Synthesis: This is Play.ai’s defining feature. It produces voices that are rich in tone, pacing, and intonation, making them sound incredibly human-like.
- High-Fidelity Voice Cloning: It can create a digital replica of a specific person’s voice from a short audio sample, which is perfect for creating a unique and consistent brand voice.
- Extensive Voice Library: Offers a vast library of high-quality, pre-made voices in multiple languages and accents.
- Low-Latency Streaming API: Crucially for real-time applications, Play.ai offers a streaming API that can start generating audio instantly, which is essential for a responsive agent.
Also Read: OpenAI Whisper Alternatives in 2025: Faster, Cheaper, and More Scalable
AssemblyAI.com (The Ears & Analytical Brain)
AssemblyAI is a leading Speech-to-Text and Audio Intelligence platform. Its primary role is to listen to and deeply understand audio content.
Key Features & Strengths
- High-Accuracy Speech-to-Text: Its core STT models are highly accurate, providing a reliable foundation for any voice application.
- Rich Audio Intelligence Suite: This is its main differentiator. It goes beyond a simple transcript to provide:
- Summarization: To get the gist of long calls.
- Sentiment Analysis: To understand the emotional tone of the speaker.
- Topic Detection: To categorize conversations automatically.
- PII Redaction: To ensure privacy and compliance.
- LeMUR Framework: A unique feature that allows you to use natural language to “ask questions” of your audio data (e.g., “What was the customer’s main pain point?”).
- Real-Time API: It offers a real-time streaming API for use in live conversational agents.
Also Read: Google Cloud Speech Alternatives in 2025: Which Platforms Compete?
How Does a Professional Stack Work Together?
The question is not Play.ai vs Assemblyai.com, but how to best combine them. A professional-grade voice agent uses them in a seamless loop, powered by a robust infrastructure.
- The Call: A user calls a number powered by FreJun AI. Our platform handles the telephony connection reliably.
- Listening (Ears): FreJun AI captures the user’s audio and streams it in real time with ultra-low latency to AssemblyAI’s STT API.
- Thinking (Brain): The highly accurate transcript from AssemblyAI is sent to your LLM for processing, which generates a text response.
- Speaking (Mouth): The text response is sent to Play.ai’s streaming TTS API.
- Responding: FreJun AI takes the resulting audio stream directly from Play.ai and streams it back to the user over the call with minimal delay, completing the loop.
This architecture creates a voice agent that is fast, intelligent, and incredibly human-like.
Comparison Table of Play.ai vs Assemblyai.com
This table highlights their complementary roles in building a voice agent.
| Feature Domain | Play.ai | AssemblyAI.com |
| Primary Function | Text-to-Speech (TTS) & Voice Cloning | Speech-to-Text (STT) & Audio Intelligence |
| Role in Conversation | The “Mouth” – Speaks to the user. | The “Ears” – Listens to and understands the user. |
| Core Technology | Generative AI models for voice synthesis. | AI models for audio recognition and analysis. |
| Key Strength | Voice quality, realism, and cloning fidelity. | Accuracy, real-time speed, and deep audio insights. |
| Input | A stream of text. | A stream of audio. |
| Output | A stream of audio (the voice). | A stream of text (the transcript) and data (insights). |
Also Read: AWS Transcribe Alternatives in 2025: Which Tools Outperform It?
Why Is FreJun AI Different?
So, you have decided to use the best “mouth” (Play.ai) and the best “ears” (AssemblyAI). You have your “brain” (your LLM). But how do you connect them all in a live phone call so that the conversation flows instantly, without the awkward delays that plague most voice bots?
This is the real challenge of building a production-grade voice agent, and it’s a problem of infrastructure.
The Missing Link: The Nervous System
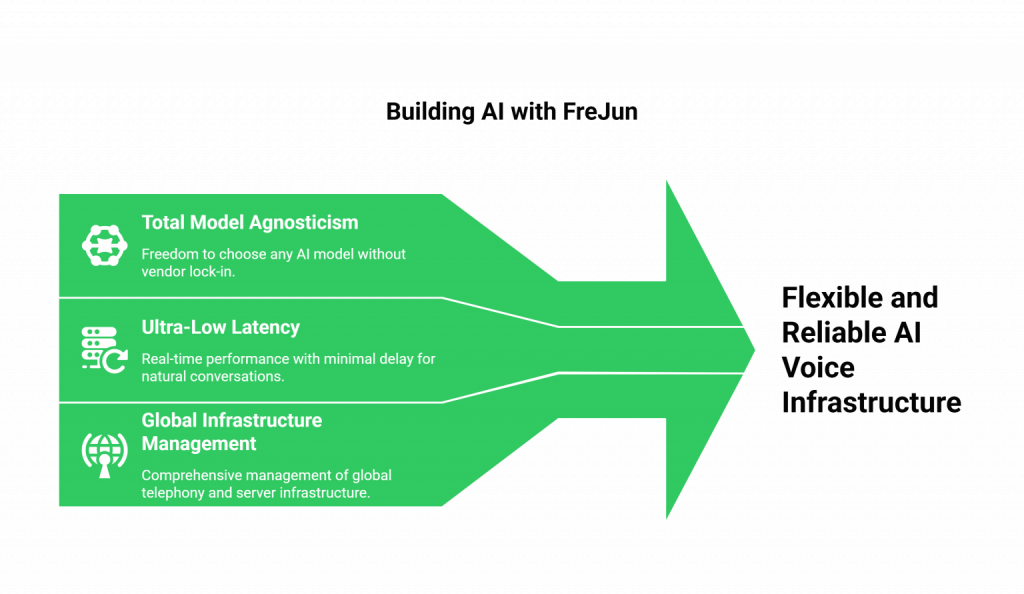
This is where FreJun AI provides the critical, foundational layer. FreJun Teler is not a TTS or an STT engine. We are a developer-first voice infrastructure platform. We are the high-performance “nervous system” that handles the complex telephony and streams audio between the user and your AI components with ultra-low latency.
Our Philosophy: “We handle the complex voice infrastructure so you can focus on building your AI.”
By building on FreJun AI, you don’t have to choose between best-in-class components; you get to use all of them.
- True Model Agnosticism: Our platform is a neutral, high-performance transport layer. It’s designed to let you plug in Play.ai for your TTS and AssemblyAI for your STT, giving you the freedom to build a “dream team” of AI models.
- Hyper-Optimized for Low Latency: We are experts in one thing: real-time voice. Our entire global infrastructure is engineered to minimize the delay in the conversational loop, ensuring the quality of Play.ai and the speed of AssemblyAI are delivered instantly.
Conclusion
The debate over Play.ai vs Assemblyai.com is a false one. You don’t choose between them for the same job; you choose to use both to create a complete, high-functioning system. A world-class voice agent needs best-in-class ears and a best-in-class mouth. The real question that separates a great prototype from a great product is: “How do I build a reliable, low-latency foundation to make them work together at scale?”
That foundation is a dedicated voice infrastructure. By combining the stunning vocal quality of Play.ai with the powerful transcription and analysis of AssemblyAI on a robust, real-time platform like FreJun AI, you are not just building another voice bot. You are architecting a truly state-of-the-art conversational experience that will set your business apart.
Also Read: Cloud Dialer System in Jordan: Why Enterprises Rely on It for Efficiency
Frequently Asked Questions (FAQs)
Play.ai is a Text-to-Speech (TTS) service; its job is to take text and convert it into high-quality, human-like audio. AssemblyAI is a Speech-to-Text (STT) and Audio Intelligence service; its job is to listen to audio and convert it into text and meaningful data. They perform opposite but complementary functions.
Yes, and for a high-quality voice agent, you absolutely should. A complete conversational loop requires an STT (like AssemblyAI) to understand the user and a TTS (like Play.ai) for the agent to respond.
No, AssemblyAI’s focus is on STT and Audio Intelligence. They do not offer a Text-to-Speech product.
FreJun AI acts as the essential voice infrastructure. It handles the live phone call, manages the complex telephony connection, and streams audio with ultra-low latency between the user and your AI models (like Play.ai and AssemblyAI), making a fluid, real-time conversation possible.