
Voice AI is no longer experimental; it’s becoming core infrastructure. But building an agent that actually works in the real world requires more than just smart models. AssemblyAI and Pipecat.ai highlight two different strengths: one listens with precision, the other responds in real time.
Understanding these roles is key for anyone designing AI-powered conversations. Add the right transport layer, and suddenly, the future of intelligent calling is within reach.
The Developer’s Real Challenge: Beyond the AI Models
Every developer building a voice AI application is on a quest for the perfect conversation. The goal is an AI agent that can listen, understand, and respond in real-time with the fluidity of a human. This journey inevitably leads to an evaluation of powerful, specialized AI platforms, tools designed to handle the intricate tasks of understanding spoken language and generating life-like responses.
However, developers quickly learn a hard lesson: a world-class voice agent is not just a combination of a speech-to-text (STT) engine and a conversational response model. A critical, often overlooked, third layer is the infrastructure that connects these AI services to a user on a live phone call. This is the complex and unforgiving world of telephony, real-time media streaming, and aggressive latency management.
You can have the most accurate transcription and the most engaging conversational AI, but if the interaction is riddled with awkward silences, garbled audio, or dropped words, the user experience is fundamentally broken. The discussion around Pipecat.ai Vs Assemblyai.com is vital, but it only addresses the AI’s “brain.” Developers must also solve for its “nervous system”, the foundational transport layer that makes real-time, bidirectional conversation possible over a phone line.
What is AssemblyAI? The AI for Speech Comprehension
AssemblyAI has carved out a position as a leader in the domain of speech intelligence and automatic speech recognition (ASR). For developers, AssemblyAI acts as the sophisticated “ears” of their application. Its core function is to take unstructured audio data and transform it into structured, analyzable text and insights with enterprise-grade accuracy.
While it is best known for its high-precision transcription, its capabilities extend much further. The platform provides a suite of APIs that enable applications to understand the rich context of a conversation, not just the words spoken.
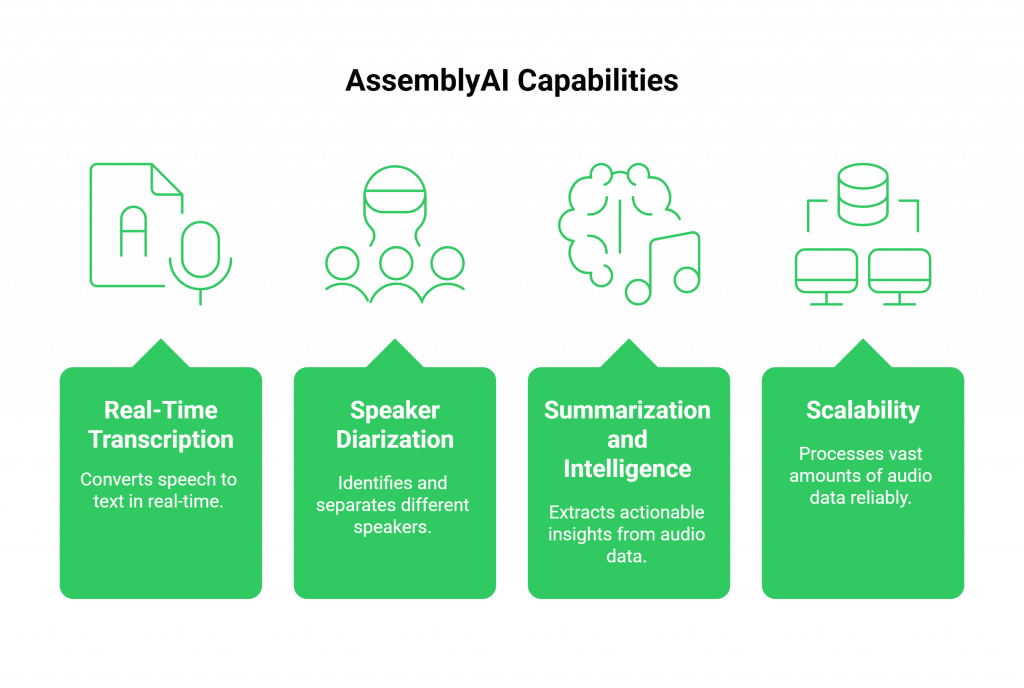
Key capabilities offered by AssemblyAI include:
- Real-Time Transcription: Delivers highly accurate speech-to-text conversion in real-time, forming the essential input for any voice-driven application.
- Speaker Diarization: Identifies and separates different speakers within the same audio stream, crucial for analyzing meetings, interviews, or multi-person customer service calls.
- Summarization and Intelligence: Provides advanced features like summarization, keyword spotting, and content moderation to extract actionable insights from audio data.
- Scalability: Engineered to process vast amounts of audio data, making it a reliable choice for enterprise applications that need to analyze thousands of hours of calls.
Developers choose AssemblyAI when their primary goal is to process, understand, and extract value from inbound voice data. It is the go-to solution for building call center analytics platforms, media captioning services, and research tools that depend on deep speech comprehension.
Also Read: Vapi.ai Vs Assemblyai.com: Which AI Voice Platform Is Best for Your Next AI Voice Project
What is Pipecat.ai? The AI for Real-Time Conversation
While AssemblyAI focuses on understanding incoming audio, Pipecat.ai is designed to manage and generate the outgoing conversational response. It is a real-time conversational AI platform built for developers who need to create interactive voice and video agents. Pipecat.ai provides the infrastructure and tools to create a live, dynamic dialogue.
The platform’s key differentiator is its focus on ultra-low latency. It’s not just a text-to-speech engine; it is a framework for building responsive agents that can handle the natural back-and-forth of a live conversation. Its architecture is optimized to minimize the delay between receiving a user’s input and delivering a coherent, context-aware response.
Key strengths of Pipecat.ai include:
- Low-Latency Streaming: Its core is built for speed, ensuring that AI responses are delivered almost instantly to create a fluid and natural conversational flow.
- Multi-Modal Interaction: Pipecat.ai supports both voice and video, enabling the development of immersive AI avatars, virtual hosts, and engaging customer experiences.
- Seamless LLM Integration: It connects smoothly with large language models (LLMs), enabling developers to power their agents with sophisticated intelligence.
Developers turn to Pipecat.ai when their objective is to build an application that can have a live, responsive conversation. It is the ideal choice for creating conversational AI avatars, interactive gaming characters (NPCs), and real-time customer support agents.
Pipecat.ai Vs Assemblyai.com: A Head-to-Head Functional Analysis
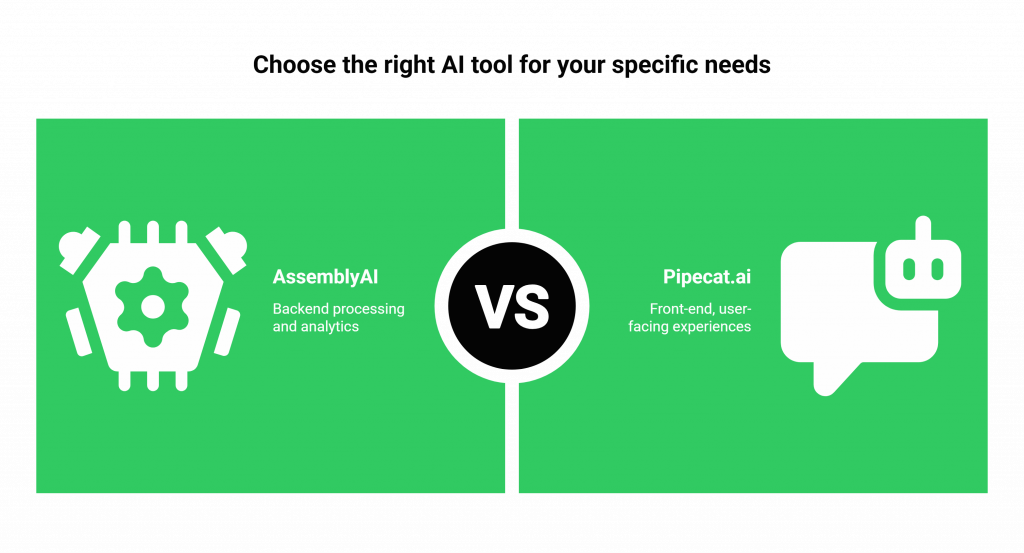
When you place Pipecat.ai Vs Assemblyai.com side by side, it becomes evident that they are not direct competitors. They are complementary technologies, each mastering a different, essential part of the modern voice AI stack. A developer’s choice is not about which is better overall, but which is right for the specific task at hand.
Core Function
- AssemblyAI: Focuses on comprehension. Its purpose is to consume audio and convert it into structured, machine-readable text and metadata. It answers the question, “What did the user say?”
- Pipecat.ai: Focuses on interaction. Its purpose is to manage and generate a real-time, low-latency conversational response. It answers the question, “How should the AI respond, right now?”
Primary Use Cases
- AssemblyAI: Excels in backend processing and analytics. It is ideal for meeting transcription services, video subtitling, deep analysis of call center recordings, and research tools.
- Pipecat.ai: Built for front-end, user-facing experiences. It is ideal for creating live AI agents, interactive gaming characters, and virtual hosts for streaming.
Developer Experience
- AssemblyAI: Provides clean, well-documented REST APIs focused on transcription and audio intelligence, making it easy to build robust speech analysis workflows.
- Pipecat.ai: Emphasizes streaming APIs and easy integration with LLMs, enabling developers to quickly build and deploy live, interactive agents.
The comparison of Pipecat.ai Vs Assemblyai.com leads to a clear architectural conclusion: for a complete, end-to-end conversational agent, you need a powerful engine to listen (AssemblyAI) and another to manage the conversation and respond (Pipecat.ai).
Also Read: Synthflow.ai Vs Deepgram.com: Which AI Voice Platform Is Best for Your Next AI Voice Project
The Missing Component: Why Your AI Needs a Voice Transport Layer
You have selected AssemblyAI for transcription and Pipecat.ai for conversational management. You have integrated a powerful LLM to act as the brain. Now, how do you connect this sophisticated AI stack to a user on a standard telephone call?
This is where a voice transport layer becomes the most critical piece of the puzzle.
AI platforms are masters of data processing, but they are not telecommunication platforms. They do not natively manage phone numbers, interface with global carriers, or handle the raw, real-time streaming of audio packets required for a phone call. Attempting to build this infrastructure yourself is a monumental task involving:
- Complex Telephony Integration: Navigating SIP trunks, PSTN gateways, and carrier negotiations.
- Real-Time Media Streaming: Capturing and transmitting audio bi-directionally with minimal delay and jitter.
- Latency Management: Optimizing every millisecond of the journey—from the user’s phone to your servers and back—to prevent unnatural conversational gaps.
- Scalability and Reliability: Architecting a system that can handle thousands of concurrent calls without failure.
This is precisely the problem FreJun solves. We are the voice transport layer designed for AI developers. We handle the entire complex voice infrastructure, allowing you to focus exclusively on building your AI. Our platform acts as the reliable, high-speed bridge between a user on a call and your AI services like AssemblyAI and Pipecat.ai.
Building a Production-Grade Voice Agent: A Modern Blueprint
With a dedicated transport layer, the architecture for a powerful voice agent becomes streamlined and robust. Here is a step-by-step blueprint of how these components work together in a production environment, leveraging the best of the Pipecat.ai Vs Assemblyai.com ecosystem.
- A Call is Initiate via FreJun: When someone calls your FreJun-powered number, or your app triggers an outbound call, our API connects it. Our enterprise-grade infrastructure manages the call connection seamlessly.
- User Speaks and Audio is Streamed: As the user speaks, FreJun’s API captures their voice in real-time. We stream this raw, low-latency audio directly to your application’s backend.
- Audio is Transcribed by AssemblyAI: Your backend receives the audio stream from FreJun and pipes it to the AssemblyAI API. AssemblyAI processes the audio and returns an accurate text transcription in milliseconds.
- Your AI Logic Determines the Response: The transcribed text is fed into your core AI logic (e.g., an LLM), which processes the user’s intent and formulates a response strategy.
- Pipecat.ai Manages the Conversational Response: Your AI logic instructs Pipecat.ai on how to respond. Pipecat.ai generates a natural, low-latency audio response and streams it back instantly.
- Audio Response is Streamed Back via FreJun: The generated audio stream from Pipecat.ai is piped back to FreJun’s API. We stream this audio back to the user on the call, completing the conversational loop with imperceptible delay.
This entire cycle happens in near real-time, creating a fluid and natural conversation. FreJun acts as the central nervous system, ensuring data flows reliably and rapidly between the user and your distributed AI components.
Also Read: Synthflow.ai Vs Play.ai: Which AI Voice Platform Is Best for Your Next AI Voice Project
Comparison: The FreJun Advantage vs. DIY Voice Infrastructure
For developers considering building their own voice transport layer, it is essential to understand the significant trade-offs in time, cost, and performance. This decision fundamentally impacts your speed to market and the final quality of your user experience.
| Feature | Building it Yourself (DIY Approach) | The FreJun Platform (Voice Transport Layer) |
| Telephony Integration | A labyrinth of SIP trunks, carrier contracts, and number porting. High upfront investment and regulatory complexity. | Instant access to global phone numbers. All telephony complexities are abstracted away behind a simple, clean API. |
| Latency Management | Requires manual, painstaking optimization of every network hop and processing step. Extremely difficult to achieve consistent sub-second latency. | Architected from the ground up for low-latency conversations. Our entire stack is obsessively optimized for real-time media streaming. |
| Developer SDKs | You must build, document, and maintain your own client-side and server-side SDKs for handling audio streams and call logic. | Comprehensive, developer-first SDKs for web and mobile that accelerate development and eliminate boilerplate code. |
| Scalability | Scaling to handle thousands of concurrent calls requires massive infrastructure investment and complex, brittle load balancing. | Built on a resilient, geographically distributed infrastructure engineered for high availability and enterprise-scale traffic. |
| Security & Compliance | You are solely responsible for implementing robust security protocols and ensuring compliance with regulations like GDPR. | Security is built into every layer of our platform. We manage compliance, ensuring the integrity and confidentiality of your data. |
| Maintenance Overhead | Requires a dedicated DevOps team for ongoing maintenance of servers, network infrastructure, and carrier relationships. | Zero maintenance overhead for you. FreJun manages the entire infrastructure, allowing you to focus 100% on your AI application. |
Final Thoughts: Focus on Your AI’s Brain, Not Its Vocal Cords
In 2025, the primary barrier to creating exceptional voice AI is not the intelligence of the models, but the complexity of integrating them into real-world, real-time applications. The specialization of platforms like Pipecat.ai Vs Assemblyai.com shows how mature the AI tooling has become. But these powerful tools cannot function over a telephone network without a robust and specialized delivery mechanism.
The most successful developers focus their limited resources on what makes their application unique: the intelligence of their AI, the quality of its logic, and the value it delivers to the user. They wisely choose to offload the complex, undifferentiated heavy lifting of voice infrastructure to a platform built for that exact purpose.
By using FreJun as your voice transport layer, you are making a strategic decision to accelerate your development cycle, guarantee enterprise-grade performance, and future-proof your application. Let us handle the intricate challenges of telephony and real-time streaming. You focus on what you do best: building the future of intelligent conversation.
Also Read: Virtual PBX Phone Systems Setup for Businesses in Mexico
Frequently Asked Questions (FAQ)
No, they are complementary. AssemblyAI specializes in understanding and transcribing speech (input), while Pipecat.ai specializes in managing and generating real-time conversational responses (output). A comprehensive voice agent often benefits from using both.
No. FreJun is the voice transport layer, not an AI model provider. Our platform is model-agnostic and serves as the essential infrastructure that connects your chosen AI services, like AssemblyAI and Pipecat.ai, to live phone calls.
Absolutely. FreJun’s API gives you flexibility. You can connect it to any AI service, build your own best-of-breed voice stack, and avoid getting locked into a single vendor.
The main benefits are speed, reliability, and focus. FreJun abstracts away the immense complexity of carrier integrations, real-time media streaming, and global infrastructure management. This allows you to launch your voice agent in a fraction of the time, with guaranteed performance, and without needing to hire a team of telecom experts.