
The world of artificial intelligence has long been dominated by a simple mantra: bigger is better. This pursuit of scale led to massive, dense language models that, while incredibly powerful, were also slow, expensive, and impractical for many real-time business applications. For customer support, this created a frustrating trade-off. Businesses had to choose between a smaller, faster model that lacked intelligence or a powerful model that was too costly and slow for a live voice conversation.
Table of contents
- The Production Wall: Why Your Voice AI Project is Failing
- The Solution: An Efficient Brain with an Enterprise-Grade Voice
- The Core Technology Stack for a Production-Ready Voice Bot
- The Production-Grade Mistral 8x7B Voice Bot Tutorial
- DIY Infrastructure vs. FreJun: A Strategic Comparison
- Best Practices for Optimizing Your Mistral 8x7B Voice Bot
- Beyond the Model: Turning Open-Source AI into a Business Asset
- Frequently Asked Questions (FAQs)
This is where a new architectural paradigm, the Mixture-of-Experts (MoE), is fundamentally changing the equation. MoE models offer the best of both worlds: the power of a massive model with the speed and cost-effectiveness of a much smaller one. Mistral AI’s Mixtral 8x7B, a state-of-the-art open-source MoE model, is at the forefront of this revolution. By intelligently activating only a fraction of its total parameters for any given task, it delivers flagship performance with remarkable efficiency, finally resolving the power-versus-practicality dilemma.
The Production Wall: Why Your Voice AI Project is Failing
The excitement around a powerful and efficient model like Mixtral 8x7B often inspires development teams to build impressive voice bot demos. These proofs-of-concept, running on a local machine with a microphone, showcase the AI’s stunning conversational ability. But a massive chasm separates this lab experiment from a scalable, production-grade system that can handle real phone calls from customers. This is the production wall, and it’s where most voice AI projects fail.
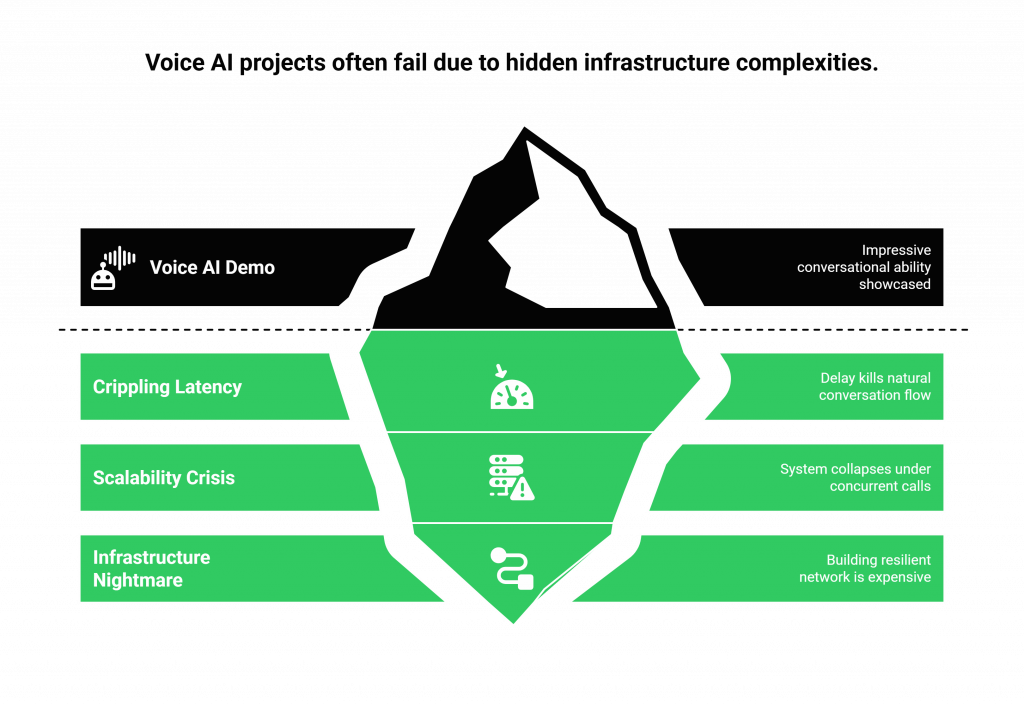
When a business tries to take their demo live, they collide with the brutal complexity of telephony infrastructure. The challenges are significant and often underestimated:
- Crippling Latency: The delay between a caller speaking and the bot responding is the number one killer of a natural conversation. High latency creates awkward pauses, interruptions, and a frustrating user experience.
- The Scalability Crisis: A system that works for one call will collapse under the weight of hundreds or thousands of concurrent calls during peak business hours.
- Infrastructure Nightmare: Building and maintaining a resilient, geographically distributed network of telephony carriers, SIP trunks, and real-time media streaming protocols is a highly specialized, expensive, and time-consuming endeavor.
This infrastructure problem is the primary reason why so many promising voice AI projects stall, burning through budgets and engineering hours on “plumbing” instead of perfecting the AI-driven experience.
The Solution: An Efficient Brain with an Enterprise-Grade Voice
To build a voice bot that is both intelligent and economical, you need to combine an efficient AI “brain” with a robust, low-latency “voice.” This is where the synergy between Mixtral 8x7B and FreJun’s voice infrastructure creates a powerful, production-ready solution.
- The Brain (Mixtral 8x7B): Mixtral’s MoE architecture, 32k token context window, and multilingual capabilities make it a highly efficient and powerful engine for understanding complex, multi-turn customer support conversations. The instruction-tuned version is perfect for this role.
- The Voice (FreJun): FreJun handles the complex voice infrastructure so you can focus on building your AI. Our platform is the critical transport layer that connects your Mixtral 8x7B application to your customers over any telephone line. We are architected for the speed and clarity that a real-time Mistral 8x7B voice bot demands.
By pairing Mixtral’s efficiency with FreJun’s reliability, you can bypass the biggest hurdles in voice bot development and create a support experience that is both world-class and cost-effective.
The Core Technology Stack for a Production-Ready Voice Bot
A modern voice bot is a pipeline of integrated technologies. For a bot powered by Mixtral 8x7B, a production-ready stack includes:
- Voice Infrastructure (FreJun): The foundational layer that connects your bot to the telephone network, managing the call and streaming audio in real-time.
- Automatic Speech Recognition (ASR): A service like AssemblyAI or Whisper that transcribes the caller’s raw audio into text.
- Conversational AI (Mixtral 8x7B): The “brain” of the operation. The Mixtral-8x7B-Instruct-v0.1 variant is ideal for this, loaded via Hugging Face Transformers.
- Text-to-Speech (TTS): A service like ElevenLabs or Google TTS that converts the AI’s text response into natural-sounding speech.
FreJun is designed to be the seamless voice channel for this powerful, integrated AI stack.
The Production-Grade Mistral 8x7B Voice Bot Tutorial
While many tutorials start with your computer’s microphone, a real business application starts with a customer’s phone call. This guide outlines the pipeline for a production-grade Mistral 8x7B voice bot.
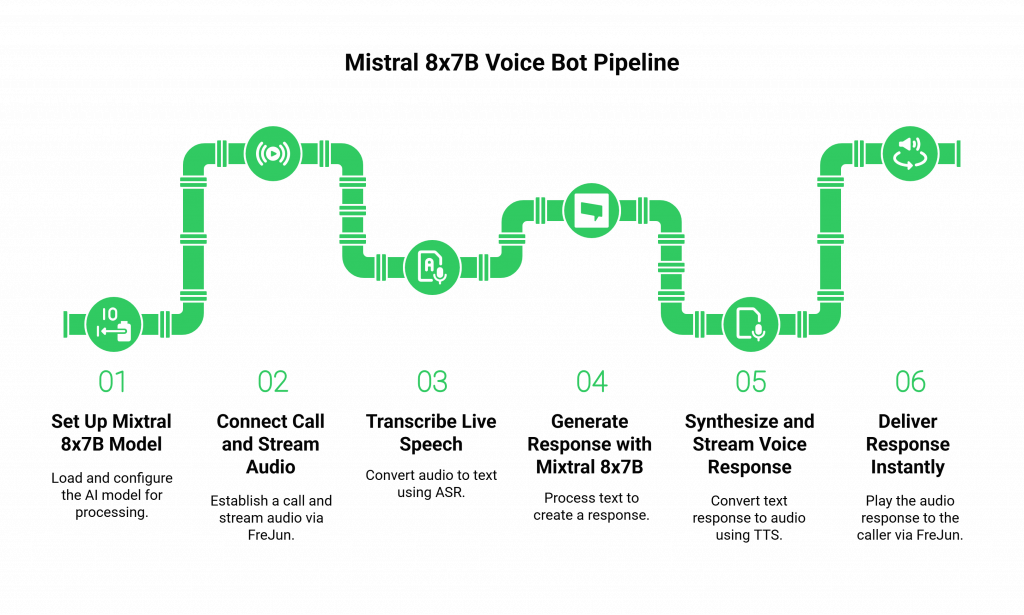
Step 1: Set Up Your Mixtral 8x7B Model
Before your bot can think, its brain needs to be running.
- How it Works: Use the Hugging Face Transformers library to load the Mixtral-8x7B-Instruct-v0.1 model and its tokenizer, ensuring you set trust_remote_code=True. For performance, run this on a GPU-enabled server and use mixed-precision (bfloat16). This setup provides a stable API endpoint for your bot’s logic.
Step 2: Connect the Call and Stream Audio via FreJun
This is where the real-world interaction begins.
- How it Works: A customer dials your business phone number, which is routed through FreJun. Our API establishes the call and immediately provides your application with a secure, real-time stream of the caller’s raw voice audio.
Step 3: Transcribe Live Speech with ASR
The audio stream from FreJun is fed directly to your chosen ASR engine.
- How it Works: You stream the audio from FreJun to your ASR service, which transcribes the speech in real time and returns the text to your application server.
Step 4: Generate a Response with Mixtral 8x7B
The transcribed text is fed to your AI model.
- How it Works: Your application takes the transcribed text, appends it to the ongoing conversation history, and sends it all as a prompt to your Mixtral 8x7B API endpoint. The model’s 32k context window is key for maintaining coherent, multi-turn dialogues.
Step 5: Synthesize and Stream the Voice Response with TTS
The text response from Mixtral must be converted back into audio.
- How it Works: The generated text is passed to your chosen TTS engine. To maintain a natural flow, it is critical to use a streaming TTS service that begins generating audio as soon as the first words of the response are available.
Step 6: Deliver the Response Instantly via FreJun
The final, crucial step is playing the bot’s voice to the caller.
- How it Works: You pipe the synthesized audio stream from your TTS service directly to the FreJun API. Our platform plays this audio to the caller over the phone line with minimal latency, completing the conversational loop and creating a seamless, interactive experience for your Mistral 8x7B voice bot.
DIY Infrastructure vs. FreJun: A Strategic Comparison
As you set out to build a Mistral 8x7B voice bot, you face a critical build-vs-buy decision for your voice infrastructure. The choice will impact your project’s speed, cost, and ultimate success.
| Feature / Aspect | DIY Telephony Infrastructure | FreJun’s Voice Platform |
| Primary Focus | 80% of your resources are spent on complex telephony, network engineering, and latency optimization. | 100% of your resources are focused on building and refining the AI conversational experience with Mixtral 8x7B. |
| Time to Market | Extremely slow (months to over a year). Requires hiring a team with rare and expensive telecom expertise. | Extremely fast (days to weeks). Our developer-first APIs and SDKs abstract away all the complexity. |
| Latency Management | A constant and difficult battle to minimize the conversational delays that make bots feel robotic. | Engineered for low latency. Our entire stack is optimized for the demands of real-time voice AI. |
| Scalability & Reliability | Requires massive capital investment in redundant hardware, carrier contracts, and 24/7 monitoring. | Built-in. Our platform is built on a resilient, high-availability infrastructure designed to scale with your business. |
| Cost Efficiency | High fixed costs for hardware and specialized staff, regardless of call volume. | Pay-as-you-go model that scales with your usage, perfectly complementing the efficiency of the MoE model. |
Best Practices for Optimizing Your Mistral 8x7B Voice Bot
Building the pipeline is the first step. To create a truly effective Mistral 8x7B voice bot, follow these best practices:
- Use the Instruct-Tuned Model: Always opt for the Mixtral-8x7B-Instruct-v0.1 version for conversational tasks. They specifically fine-tuned it for following instructions and engaging in dialogue, making it far more effective.
- Leverage the MoE Architecture: The Mixture-of-Experts design is built for efficiency. Architect your application to take advantage of this, enabling more sophisticated interactions without a linear increase in cost.
- Master Prompt Engineering: Fine-tune your system prompts to clearly define the agent’s role, personality, and constraints. This is your primary tool for guiding its behavior.
- Test in Real-World Scenarios: Move beyond your development environment. Test your agent with real phone calls, diverse accents, and noisy backgrounds to ensure its robustness. This is a critical step for any Mistral 8x7B voice bot.
Beyond the Model: Turning Open-Source AI into a Business Asset
Mixtral 8x7B is more than just another large language model; its efficient MoE architecture represents a new frontier in accessible, high-performance AI. This creates an unprecedented opportunity for businesses to deploy intelligent automation that is both powerful and economical.
By building your Mistral 8x7B voice bot on FreJun’s infrastructure, you make a strategic decision to leapfrog the most significant technical hurdles and focus directly on innovation. You can harness the full potential of this groundbreaking model, confident that its voice will be clear, reliable, and ready to scale. Stop worrying about telephony and start building the future of your customer interactions. This is how you turn a powerful AI model into a tangible business asset.
Further Reading – API-First Guide to Voice-Based Conversational AI
Frequently Asked Questions (FAQs)
Mixtral 8x7B is a large, open-source language model from Mistral AI that uses a Mixture-of-Experts (MoE) architecture. This makes it very powerful while remaining computationally efficient and cost-effective for tasks like building a Mistral 8x7B voice bot.
No. FreJun is the specialized voice infrastructure layer. We provide the real-time call management and audio streaming. Our platform is model-agnostic, allowing you to connect to the Mixtral 8x7B model running on your own infrastructure or a third-party host. This gives you maximum control and flexibility.
An MoE model is a type of neural network that is compose of multiple “expert” sub-networks. For any given input, the model only uses a small subset of these experts. This makes inference much faster and cheaper than a traditional dense model of a similar size.
A business application needs to handle real phone calls from the public telephone network, scale to many concurrent users, and operate with high reliability and low latency. A microphone-based demo cannot meet any of these production requirements, which is why a voice infrastructure platform like FreJun is necessary.