
Real-time media streaming is the invisible engine behind every AI-driven voice interaction. While users hear a seamless conversation, engineering teams manage packet routing, jitter handling, encoding, buffering, and timing alignment – every millisecond matters. Understanding this flow is essential for founders, product leaders, and engineering teams building reliable AI voice automation.
This blog breaks down how audio travels across networks, how telephony media transport works, and how platforms like Teler stabilize the entire pipeline. By the end, you will clearly understand how voice data moves, why low-latency design matters, and how to build AI call systems that scale with predictable quality.
Why Are AI-Driven Voice Calls Impossible Without Real-Time Media Streaming?
Every modern voice agent runs on one foundation: media streaming. Behind every call – whether it is an inbound support line or an outbound automated conversation – there is a continuous flow of audio packets moving between the user, the telephony network, and the application’s computation layer. Without this steady flow, the agent cannot listen, cannot respond, and cannot maintain the rhythm that callers naturally expect in human conversations.
Additionally, any voice agent built on LLMs or custom logic depends on receiving audio in small, time-sensitive chunks. Even a delay of a few hundred milliseconds can break flow, cause overlapping speech, or force the caller to repeat themselves. Consequently, media streaming is not the backend detail many assume; it is the core of AI voice call infrastructure.
Before we learn how it all works, we must understand what streaming means in telephony.
What Exactly Is Media Streaming in the Context of Voice Calls?
When we talk about streaming in a phone conversation, we are not referring to how platforms stream movies or how websites play stored audio. Telephony requires real-time call audio streaming, where audio travels as small encoded packets with strict timing rules.
Here’s what makes real-time media different:
- It must be bidirectional – callers speak while the system responds.
- It must be continuous – no buffering for seconds like video platforms.
- It must be low-latency – conversational flow requires quick reaction.
- It must survive network inconsistencies – jitter, packet drops, and codec mismatches are common.
This real-time requirement makes media streaming one of the hardest parts of building a usable voice agent. Although LLMs can generate responses quickly, without reliable media transport those responses cannot reach the caller smoothly.
How Does Audio Packet Streaming Work in a Live Phone Call?
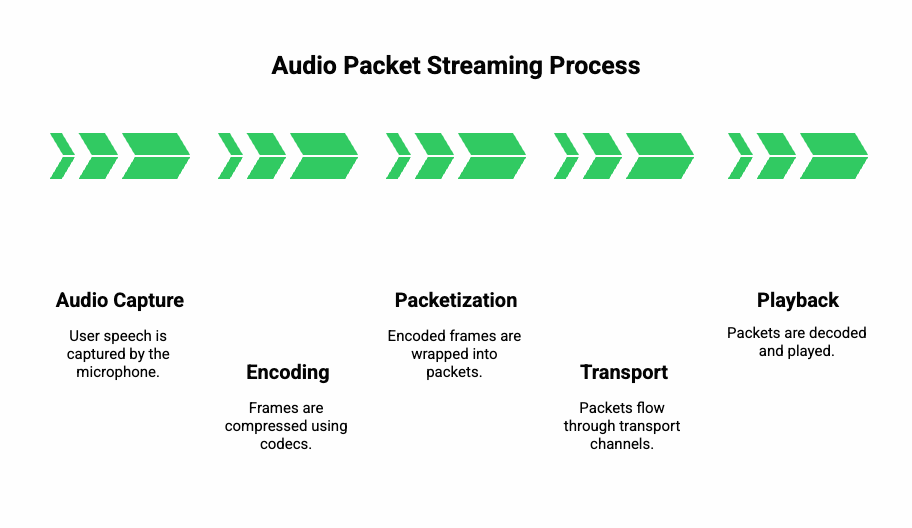
Media streaming relies on audio packet streaming, a method where audio is sliced into frames, encoded, and sent across networks using specialized protocols.
Here is the simplified flow:
- Audio capture
- User speech is captured by the microphone.
- The voice stream is divided into frames (typically 10- 20 ms each).
- User speech is captured by the microphone.
- Encoding
- Frames are compressed using codecs such as Opus or G.711.
- The codec determines audio quality, required bandwidth, and latency.
- Frames are compressed using codecs such as Opus or G.711.
- Packetization
- Encoded frames are wrapped into packets.
- Time stamps ensure correct ordering on the receiving side.
- Encoded frames are wrapped into packets.
- Transport
- Packets flow through telephony media transport channels, usually RTP (Real-time Transport Protocol).
- For web and mobile apps, this is often WebRTC with SRTP for security.
- Packets flow through telephony media transport channels, usually RTP (Real-time Transport Protocol).
- Playback
- Packets are decoded and played through the recipient’s device.
- A jitter buffer smooths small timing fluctuations.
- Packets are decoded and played through the recipient’s device.
Because each packet must arrive in order and within strict timing windows, packet streaming becomes the backbone of call reliability. Even a small deviation can produce glitches or delayed responses.
Explore real deployment examples showing how Elastic SIP Trunking powers large-scale AI call automation with consistent routing, reliability, and low latency.
Which Protocols Power Telephony Media Transport at Scale?
Real-time voice relies on a group of protocols that have been shaped over decades of telecom advancements. Although their names often intimidate new teams, understanding their roles is essential.
Key Protocols
| Protocol | Purpose | Why It Matters |
| SIP (Session Initiation Protocol) | Call setup and teardown | Connects caller → system; defines session rules |
| SDP (Session Description Protocol) | Negotiates codecs and media formats | Ensures both ends agree on audio format |
| RTP (Real-time Transport Protocol) | Sends audio packets | Core of media streaming |
| SRTP (Secure RTP) | Encrypts audio packets | Protects sensitive voice data |
| WebRTC | Real-time audio in apps/browsers | Handles NAT traversal, encryption, jitter buffers |
| RTCP | Monitors performance metrics | Reports packet loss, jitter, and latency |
Now, why does this matter for someone building an LLM-powered or agent-powered voice system?
Because without the right SIP negotiation, the call never starts. Without RTP, audio never arrives. Without SRTP, the conversation cannot meet compliance requirements. And finally, without WebRTC tooling, browser-based or mobile voice clients would become extremely complex to maintain.
Even with these standards, developers still must tune them correctly for real-time call audio streaming.
Why Is Latency the Most Critical Factor in an AI Voice Call?
Latency affects every part of a voice agent:
- When latency is low, callers feel the system is responsive.
- When latency is high, the agent feels broken – regardless of how good the LLM logic is.
Where latency comes from
Although many assume latency is caused only by the model, the entire pipeline adds delay:
- Network travel time (RTP or WebRTC)
- Codec encoding and decoding
- Jitter buffer smoothing
- STT (Streaming Speech Recognition)
- LLM token generation
- TTS audio creation
- Transport back to the caller
Because every stage adds some delay, the streaming layer must stay extremely efficient. This is where most engineering teams struggle, as telephony requires a mouth-to-ear latency of under 200- 300 ms for natural conversations.
Even a small bottleneck anywhere in the pipeline can create delays, making real-time media streaming the component that determines the user’s experience.
How Does Real-Time Call Audio Flow From Caller to Application to Caller?
Let’s break the entire loop down into a real sequence. This is the flow followed by any AI voice agent, regardless of framework or model.
End-to-End Real-Time Flow
- Caller speaks: Audio enters the telephony network and gets encoded.
- Telephony media transport forwards audio: The audio travels through SIP/RTP or WebRTC to your application.
- Audio frames reach STT: Speech recognition receives each frame and begins transcribing partial segments.
- Text is passed to the reasoning/logic layer: This may be an LLM, a custom model, or a rule-based engine.
- The logic layer produces a text response: This may involve fetching external information, calling APIs, or using memory.
- Text is converted to speech: TTS synthesizes audio, usually in chunks.
- Audio is streamed back using RTP/WebRTC: The caller hears the response with minimal delay.
This entire chain repeats many times during a call. Because of this repetition, the system must be streamlined and reliable.
How Is Caller Audio Streamed and Processed Using STT Engines?
Speech recognition engines work best when audio arrives in continuous, time-aligned packets. For that reason, streaming ASR is mandatory for voice agents.
STT workflow (simplified)
- Audio frames arrive every 10- 20 ms.
- The streaming ASR consumes frames as they come.
- It produces partial transcripts instead of waiting for full sentences.
- Partial transcripts update in real time.
- The application can react instantly even before the caller finishes speaking.
This streaming model reduces delay because the system does not wait for complete utterances. Instead, it predicts intent as early as possible. Without this, the agent would feel sluggish and callers might interrupt before the system responds.
How Do LLMs, RAG, and Tool-Calling Fit Into the Voice Pipeline?
Once text leaves the STT system, it enters the reasoning layer. Although each application uses a different stack, the structure is similar:
Core Steps
- Interpret the transcript (intent recognition or direct LLM input)
- Retrieve data using RAG or a memory store
- Call external tools if required (CRMs, calendars, verification systems)
- Generate text output token by token
To maintain low latency, the reasoning layer must be optimized for:
- Fast token-level generation
- Interrupt handling
- Partial token streaming
- Lightweight context windows
- Efficient RAG lookups
This part of the pipeline strongly influences final latency, but it still depends on the performance of the streaming layer beneath it.
How Is TTS Audio Generated and Streamed Back Over the Call?
TTS works in two possible modes:
1. Non-streaming TTS
- Generates the full audio clip
- Sends it to the caller as one file
- Produces higher quality but increases delay
2. Streaming TTS
- Generates audio in chunks
- Sends the first chunk immediately
- Allows callers to hear responses earlier
- Reduces perceived latency significantly
After synthesis, audio goes back through:
- Encoding
- Packetization
- RTP/SRTP transport
- Playback at the receiver’s end
This final stage completes the conversational loop.
How Does FreJun Teler Handle the Voice Layer So You Can Focus on the AI Layer?
Most teams waste months building the “voice side” of their AI product – SIP signaling, media gateways, audio packet ordering, codec handling, jitter control, dual-path routing, and end-to-end stability. This layer is extremely complex and has nothing to do with the intelligence of the AI agent itself. Industry guidance (ITU-T G.114) recommends keeping mouth-to-ear one-way delay ideally below 150 ms – a useful engineering target when tuning media edges and playback for live voice agents.
FreJun Teler solves this entire layer.
Teler operates as a dedicated voice transport layer, delivering real-time call audio streaming between your AI models and any phone network (PSTN, VoIP, SIP trunks, or WebRTC). Instead of building telephony media transport from scratch, teams connect their AI stack to Teler’s streaming interface.
What Teler Handles Behind the Scenes
Teler manages all the moving parts that typically slow engineering teams:
- SIP and WebRTC signaling
- Media-edge routing and transcoding
- Audio packet streaming across global regions
- Low-latency forward/return audio flow
- Jitter, packet loss recovery, and error concealment
- High-quality endpoint-to-cloud transport
This ensures that your AI receives clean, ordered audio frames and can respond fast, keeping the call natural.
Model-Agnostic Architecture
Teler does not lock you into any AI technology. You can bring:
- any LLM (OpenAI, Anthropic, Google, custom model)
- any STT (AssemblyAI, Deepgram, Google, Whisper)
- any TTS (Azure, ElevenLabs, PlayHT, in-house synthesizers)
Because Teler only controls the streaming layer, you retain full control over the intelligence and logic.
Why This Matters for Product Teams
By offloading the voice layer, teams can:
- ship voice features in days, not months
- focus on conversation design and reasoning logic
- scale to enterprise telephony without rewriting code
- avoid building and maintaining media servers internally
This separation of concerns reduces risk and makes voice AI deployable in production environments much sooner.
How Do You Implement Teler + Any LLM + Any STT/TTS in Production?
Once Teler manages the media pipeline, your AI architecture becomes clean, modular, and predictable.
Below is the recommended production blueprint:
User Voice
→ Teler Media Layer (captures call audio)
→ Your STT Engine (transcribes packets)
→ Your LLM/AI Logic (decides next action)
→ Your TTS Engine (generates audio)
→ Teler Low-Latency Playback
→ User Hears Response
This flow ensures deterministic behavior while keeping every component independent.
Key Engineering Steps
1. Capture Inbound Audio via Teler
Teler streams live call audio in small packets to your webhook or socket endpoint. This reduces processing delay and synchronizes timestamps.
2. Send Packets to Your STT Engine
Your STT receives chunked audio, returns both partial and final transcripts, and keeps the agent responsive.
3. Process Logic in Your LLM or Workflow Engine
Your backend manages:
- intent parsing
- memory retrieval
- RAG lookups
- business rules
- tool calling
This guarantees predictable behavior even under load.
4. Generate Outbound Audio via TTS
Your TTS engine produces synthesized voice in streaming segments (not full WAV files).
5. Stream Output Back Using Teler Playback
Teler handles jitter buffers, playback timing, and smooth delivery – so users hear responses without lag.
Why This Architecture Works in Production
- Each layer can scale independently
- STT/LLM/TTS can be swapped without breaking telephony
- Audio packet streaming remains consistent even during high traffic
- Latency stays low because each component handles one job
- Debugging becomes simpler through isolated logs
This is the architecture most mature voice AI systems end up adopting.
How Do You Maintain Conversational Context Across a Voice Session?
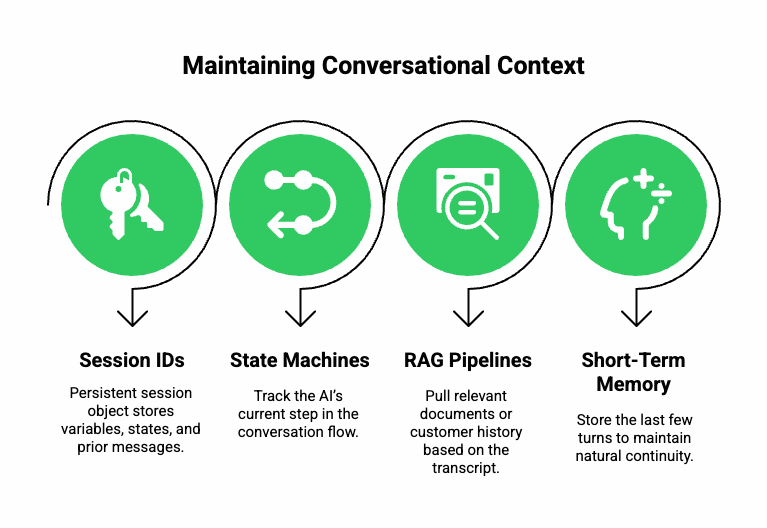
Real-time voice sessions require context to remain consistent from the first word to the last. Because audio is streamed in fragments, context management must run in parallel.
Core Elements of Context Tracking
- Session IDs: Every call carries a persistent session object that stores variables, states, and prior messages.
- State Machines: Keep track of the AI’s current step (verification, information gathering, action execution).
- RAG Pipelines: Pull relevant documents or customer history based on the latest transcript chunk.
- Short-Term Memory Buffers: Store the last few turns to help maintain natural continuity.
Why Context Can Break
Context often fails because of:
- delayed STT results
- overlapping audio
- incorrect state transitions
- long latency between packets
A robust context engine prevents these issues and keeps the flow natural.
How Should Teams Handle Errors, Dropouts, or Slow AI Responses?
Live calls are imperfect. Networks fluctuate. AI services hit rate limits. Telephony packets drop. Because of this, a fallback design is essential.
Common Failure Points
- STT stalls or slows
- TTS fails to return audio
- LLM takes too long to respond
- sudden packet loss
- jitter spikes causing delays
Recommended Fallback Mechanisms
- Retry sequences for transient STT/LLM errors
- Graceful degradation (switch to shorter answers if LLM is slow)
- Timeout-driven TTS (“Let me check that…”)
- Silence detection to restart TTS playback cleanly
- Re-anchoring logic to reset context after drops
With these layers, the AI agent stays usable even under unstable conditions.
How Do Scalability and Quality-of-Service Work in AI Voice Call Infrastructure?
When calls increase, the system must scale both horizontally and geographically.
Media Layer Scalability
- Geo-distributed media servers reduce latency
- Multi-region routing increases reliability
- Autoscaling STT/LLM/TTS keeps processing time stable
- Load-aware session routing prevents bottlenecks
Observability Stack Requirements
Engineering teams need:
- per-packet logs
- round-trip latency metrics
- jitter measurements
- STT/LLM/TTS timing traces
- session-level event streams
This visibility ensures predictable performance during high traffic.
How Do You Secure Media Streams and Protect Sensitive Voice Data?
Voice calls carry personal and sometimes regulated information. Strong security is mandatory.
Core Security Methods
- SRTP: Encrypts audio packets in transit
- TLS/DTLS: Protects signaling and media negotiation
- Data Sanitization: Removes sensitive entities before forwarding text to LLMs
- Role-Based Access Control: Ensures only authorized users see transcripts
- Encrypted Storage: Protects call logs and analytics
Security must extend across both media paths and AI services, not just one layer.
Conclusion
Media streaming now forms the real foundation of every AI-driven voice experience. As pipelines mature, teams will gain more predictable latency, stronger error recovery, and real-time adaptation across diverse calling workflows. Engineering leaders who invest early in a stable media layer avoid infrastructure bottlenecks, reduce integration effort, and accelerate deployment of intelligent voice automation.
Teler helps teams achieve this by abstracting telephony, packet transport, and media handling into a unified, production-grade platform. This lets product and engineering teams focus entirely on AI logic, orchestration, and customer experience – not on call plumbing.
FAQs –
- How does media streaming improve AI voice call responsiveness?
It reduces delay by sending small audio packets continuously, enabling faster speech recognition and quicker system responses. - Why is audio packet streaming better than sending full audio files?
It delivers audio in real time, minimizes buffering, and supports live interaction instead of waiting for file uploads. - How do jitter buffers support call stability?
They absorb timing variations, keeping audio smooth even when network conditions fluctuate. - Does telephony media transport impact AI accuracy?
Yes. Cleaner, low-loss audio packets significantly improve transcription accuracy and reduce model misinterpretations. - Can AI calls work reliably over unstable networks?
Yes. With adaptive jitter buffers, packet redundancy, and codec optimization, systems maintain stable audio under weak connections. - Why is latency so critical in AI-driven voice automation?
High latency breaks conversational flow, causing delays that disrupt natural responses and reduce user satisfaction. - How does SRTP protect real-time audio?
It encrypts packet streams, preventing interception while maintaining low-latency processing suitable for real-time voice. - What role do codecs play in AI voice calls?
Codecs compress audio efficiently, controlling bandwidth use while keeping quality high for accurate speech processing. - Do AI voice calls need special infrastructure beyond VoIP?
Yes. They require low-latency media routing, STT streaming, inference pipelines, and synchronized audio playback. - How does Teler simplify building AI voice systems?
It manages telephony, packet transport, media handling, and routing so teams can focus entirely on AI workflows.