
Real-time voice AI is no longer experimental. Enterprises are deploying voice agents that speak, listen, reason, and respond in milliseconds. However, most implementation challenges do not come from the AI model itself. They appear in the layers between audio input and audio output. Latency, transport reliability, session handling, and streaming design decide whether a conversation feels natural or broken.
This guide explains media streaming architecture from the first API call to a live conversation. It focuses on how audio flows, how systems interact in parallel, and how teams can combine any LLM with any speech system. The goal is clarity, not complexity, so builders can design reliable voice agents with confidence.
What Is Media Streaming And Why Does It Matter For Real-Time Voice?
Media streaming is the process of sending audio or video continuously, in small pieces, over a persistent connection. Instead of waiting for a full payload, data flows in real time.
This matters because voice conversations are time-sensitive by nature. Even small delays change how a conversation feels to a human listener.
On the client side, the W3C Media Capture and Streams specification (getUserMedia / MediaStreams) is the standard entry point for continuous audio capture in web applications.
Why Request-Response APIs Fail For Voice
Traditional APIs follow a request-response model. A client sends data, the server processes it, and a response is sent back.
That model works well for tasks such as:
- Submitting a form
- Fetching a report
- Uploading or downloading files
However, real-time voice does not work this way. Voice is continuous, not discrete. If audio is treated as a single request, the system must wait until the user stops speaking. As a result, responses arrive late and conversations feel broken.
In contrast, media streaming allows audio to move as it is created. This is why modern voice systems rely on streaming from the first second of speech.
As we move forward, it becomes clear that everything starts at the microphone.
What Really Happens When A User Starts Speaking?
When a user speaks, audio is not captured as one long recording. Instead, devices and browsers break sound into small segments and process them continuously.
Audio Capture At The Source
Most applications capture audio using device or browser audio APIs. These APIs provide a continuous stream of sound data rather than a single file.
In practical terms:
- Audio is captured from the microphone
- The sound is divided into small time-based frames
- Each frame represents a few milliseconds of speech
Typically, frames range between 10 and 40 milliseconds. Smaller frames reduce latency, while larger frames reduce network overhead. Finding the right balance is part of designing a good media streaming architecture.
Preparing Audio For Streaming
Before audio is streamed, it often goes through basic processing. This may include noise suppression, silence detection, or sample rate normalization.
These steps make audio easier to transmit and process downstream. More importantly, they ensure predictable behavior across different devices.
Once audio frames are ready, they must be sent to the backend without interruption. This leads directly to transport design.
How Does Audio Move From The Client To Your Backend In Real Time?
For real-time voice, the transport layer is not an implementation detail. It is a core architectural choice.
Why Persistent Connections Are Required
Opening a new connection for every audio chunk would introduce delays that users can easily hear. Therefore, real-time voice systems rely on persistent connections that stay open for the entire conversation.
With a persistent connection:
- Audio frames flow continuously
- The backend can respond immediately
- Both sides can send data at the same time
Common Transport Approaches
Different transport methods exist, each with trade-offs.
WebSocket is often used because it is simple and supports bidirectional streaming. WebRTC is designed specifically for low-latency media and handles many networking challenges automatically. RTP and SIP are used when connecting to traditional telephony networks.
Regardless of the choice, the goal is the same. Audio must arrive quickly, in the correct order, and without gaps.
At this stage, audio is flowing into the system. The next challenge is understanding what the user is saying.
What Is The Real-Time Voice Pipeline Made Of?
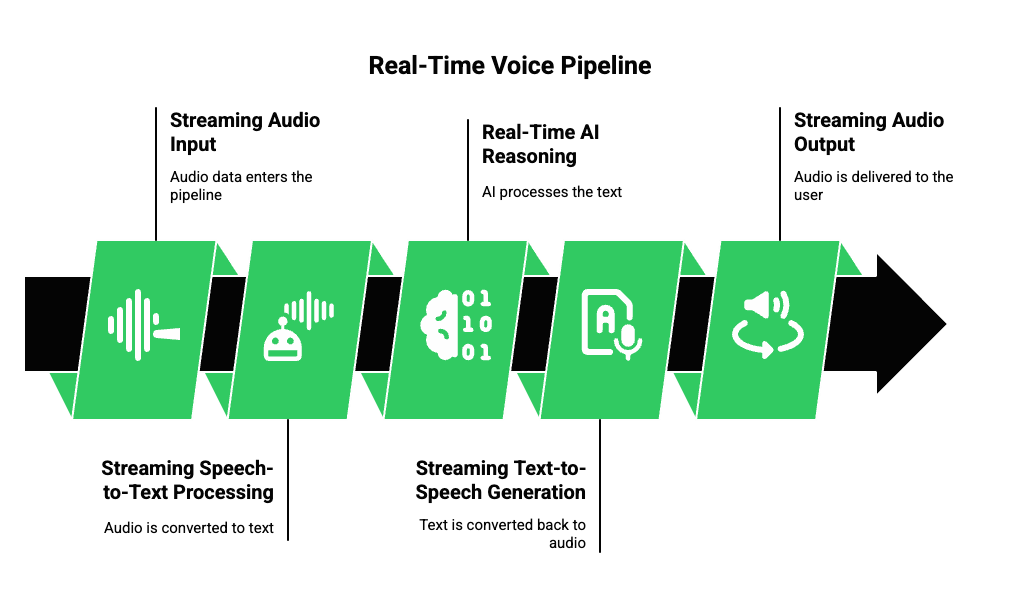
A real-time voice pipeline describes how streaming audio becomes a spoken response.
Although implementations vary, most production systems follow the same logical structure.
The pipeline includes:
- Streaming audio input
- Streaming speech-to-text processing
- Real-time AI reasoning
- Streaming text-to-speech generation
- Streaming audio output
The key idea is that these steps do not wait for one another. Instead, they run in parallel.
Because of this parallelism, users receive responses while they are still engaged in the conversation.
The first intelligence layer in this pipeline is speech-to-text.
How Does Streaming Speech-To-Text Work In Practice?
Speech-to-text systems convert audio into written text. However, not all STT systems are suitable for real-time voice.
Batch STT Versus Streaming STT
Batch STT waits until it receives a full audio recording. Only then does it generate text. This approach adds seconds of delay and breaks conversational flow.
Streaming STT works differently. It processes audio frames as they arrive and produces partial transcripts in real time.
These partial transcripts allow the system to react faster and prepare responses earlier.
Why Partial Transcripts Matter
With partial transcripts:
- Intent can be detected sooner
- AI responses can begin forming earlier
- Overall response time decreases
As a result, conversations feel natural rather than robotic.
Once text is available, the system must decide how to respond.
How Does An LLM Process Live Speech Without Breaking Flow?
Large Language Models are powerful, but voice introduces new challenges.
Unlike text chats, voice conversations involve interruptions, quick turns, and incomplete sentences. Therefore, LLMs must be used carefully.
Managing Context In Real Time
To function correctly, the system must manage:
- Short-term conversational context
- Longer-term memory using retrieval systems
- Partial user input that may change
Instead of waiting for a final transcript, LLMs often process streaming text continuously. This allows them to prepare answers even before the user finishes speaking.
In addition, many voice agents use tool calls during conversations. These may include database lookups or external API calls. All of this must happen without blocking the conversation.
Once the response is ready, it must be delivered as speech just as carefully.
How Does Text Become Speech Without Awkward Pauses?
Text-to-speech converts written text into audio. However, not all TTS approaches support real-time interaction.
Problems With Traditional TTS
Traditional TTS systems generate the entire audio output before sending anything back. This works for announcements, but not for conversations.
The delay between text generation and audio playback creates unnatural pauses.
Streaming TTS For Real-Time Output
Streaming TTS solves this by generating audio in small chunks as text becomes available.
With this approach:
- Playback can start immediately
- Long responses do not delay the first sound
- Conversations feel continuous
This design completes the loop: text becomes speech without stopping the flow.
How Does The Streaming Workflow Come Together End-to-End?
When combined, the streaming workflow looks like a single continuous loop rather than separate steps.
A typical flow includes:
- The user speaks
- Audio frames stream to the backend
- Speech is transcribed in real time
- AI generates responses continuously
- Audio is synthesized and streamed back
All components operate at the same time. This overlap is what enables real-time voice pipelines to function.
Why Architecture Matters More Than The AI Model
It is easy to focus on model selection. However, voice quality is shaped more by architecture than by model choice.
A strong LLM cannot fix:
- Latency caused by poor streaming design
- Gaps introduced by batch processing
- Delays from blocking workflows
In real-time voice systems, media streaming architecture determines whether conversations feel natural or frustrating.
How Does The Streaming Architecture Work End-to-End In Real Systems?
By now, the individual building blocks of a real-time voice pipeline are clear. However, systems are not built in isolation. The real challenge lies in connecting every piece into a single streaming workflow that works reliably under real conditions.
In practical systems, all components operate at the same time. Audio capture, transcription, AI reasoning, and speech generation overlap instead of waiting for each other. This parallel execution is what keeps conversations flowing naturally.
A realistic streaming workflow follows this order:
- Audio is captured and streamed in small frames
- Transcription happens continuously
- The AI system processes partial input
- Responses are generated incrementally
- Speech is streamed back while text is still being produced
Because of this, architecture decisions directly affect perceived intelligence and responsiveness.
What Does A Production-Ready Real-Time Voice Pipeline Look Like?
A production-grade voice system must handle more than just a happy-path demo. It must deal with network variation, different devices, long conversations, and scale.
At a high level, the pipeline includes four distinct layers.
First is the client layer. This handles audio capture, playback, buffering, and reconnection logic.
Second is the media streaming layer. This layer is responsible for transporting audio in real time, maintaining sessions, and handling low-latency bidirectional data flow.
Third is the AI orchestration layer. This includes speech-to-text, Large Language Models, context management, retrieval systems, and tool calling.
Finally, there is the audio synthesis and return path, where responses are converted back into speech and streamed to the user.
Each layer must be decoupled. Otherwise, changes in one area can break the entire system.
Real-Time Voice Pipeline: Component-Level Breakdown
| Pipeline Stage | What Happens | Why It Matters For Real-Time Experience |
| Audio Capture | Microphone audio is captured and split into small frames | Smaller frames reduce delay and enable faster downstream processing |
| Media Streaming Layer | Audio frames stream continuously over a persistent connection | Eliminates request-response delays and supports full duplex communication |
| Streaming Speech To Text | Audio frames are transcribed incrementally | Partial transcripts allow the system to react before speech ends |
| AI Orchestration (LLM) | Live transcripts are processed with context, tools, and memory | Continuous reasoning prevents awkward pauses and lag |
| Streaming Text To Speech | AI output is converted into audio chunks | Playback starts immediately instead of waiting for full synthesis |
| Audio Playback | Speech is streamed back and played in real time | Maintains conversational flow and natural timing |
Where Does Teler Fit In This Media Streaming Architecture?
This is where a dedicated voice infrastructure becomes essential.
The Role Of Teler In The Voice Stack
Teler sits at the media streaming layer of the architecture.
Instead of being a language model or a speech engine, Teler acts as the real-time voice interface that connects users, AI systems, and telephony networks. It handles the complex parts of media streaming so development teams can focus on AI logic and product behavior.
In technical terms, Teler provides:
- Persistent, low-latency audio streaming
- Bidirectional media transport for real-time conversations
- Integration with cloud telephony, VoIP, and SIP networks
- SDKs and APIs for managing calls and sessions
As a result, teams do not need to build custom streaming servers, manage reconnections, or handle telephony-level complexity.
What Teler Abstracts And What You Control
It is important to understand boundaries.
With Teler:
- You control the LLM, the prompts, and the reasoning logic
- You choose the speech-to-text and text-to-speech providers
- You manage context, tools, and retrieval systems
At the same time:
- Teler manages audio transport
- Teler maintains session stability
- Teler handles real-time playback timing
- Teler bridges AI systems with real phone and VoIP networks
Because of this clear separation, Teler works with any LLM, any STT, and any TTS without introducing lock-in.
How Can Teams Implement Teler With Any LLM And Any STT Or TTS?
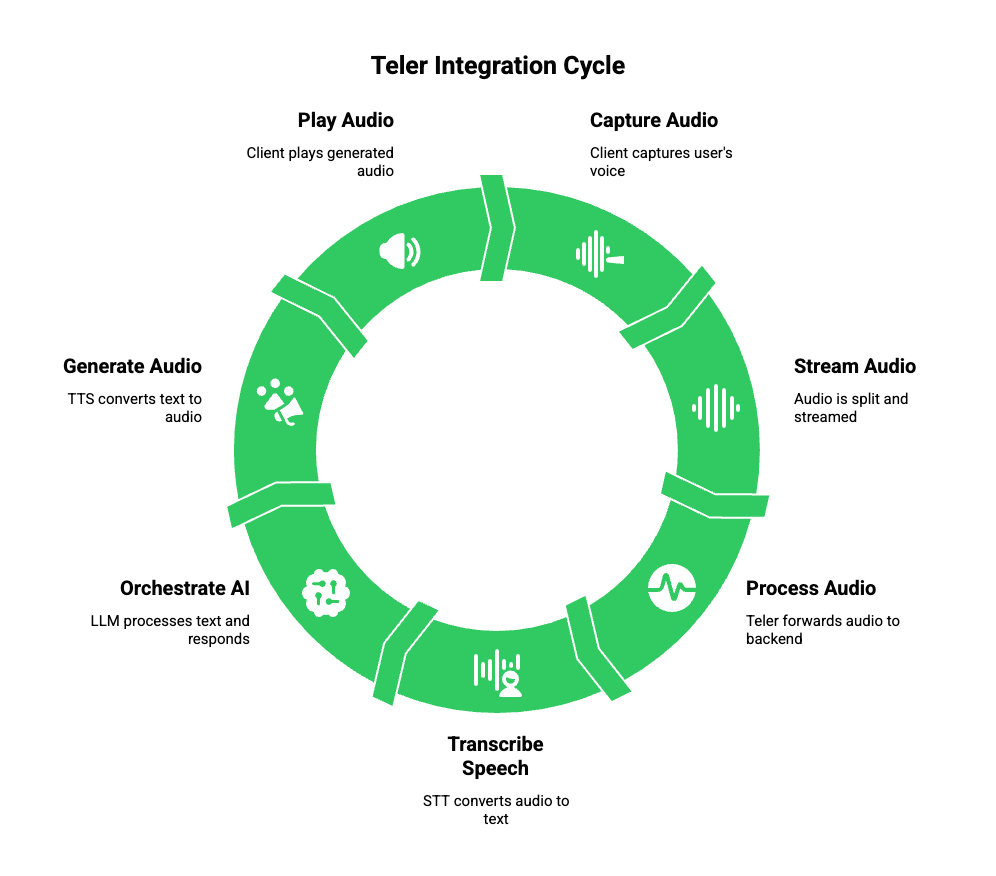
Once the architecture is clear, implementation becomes much simpler.
A typical integration follows a predictable sequence.
First, the client application captures audio from the user. This could be a browser, mobile app, or phone call. Audio is split into small frames and streamed immediately.
Next, Teler receives this audio stream and forwards it to your backend or AI service. Metadata such as session identifiers and call context travel along with the audio.
Then, streaming speech-to-text processes the incoming frames. Partial transcripts are emitted and sent to the AI orchestration layer.
The LLM consumes these partial transcripts, maintains dialogue state, and decides when to respond. When required, it queries retrieval systems or external tools.
As soon as the response begins forming, text is passed to a streaming text-to-speech system. Audio is generated incrementally and streamed back through Teler.
Finally, the client receives audio frames and plays them without waiting for the full response.
This entire loop runs continuously until the conversation ends.
What Design Decisions Matter Most During Implementation?
Many voice projects fail not because of poor models, but because of overlooked system details.
Frame Size And Latency Tradeoffs
Smaller audio frames reduce latency but increase overhead. Larger frames simplify processing but add delay. Most systems settle between 20 and 30 milliseconds.
Choosing this correctly has a direct impact on how responsive the agent feels.
Partial Responses Versus Final Responses
Waiting for final transcripts or full responses increases latency. Therefore, partial processing at every stage is critical.
This includes:
- Partial transcription
- Streaming LLM output
- Streaming text-to-speech
Each layer must support incremental data.
Session And Context Handling
Voice conversations can last several minutes. During this time, context must persist reliably.
Good systems separate:
- Short-term dialogue context
- Long-term memory stored externally
- System-level state such as call identifiers
This separation prevents memory limits from breaking conversations.
How Does This Architecture Scale For Real Businesses?
Scaling real-time voice systems introduces new challenges.
At small scale, one server may be enough. At large scale, concurrency becomes the main concern.
Scaling Considerations
Production systems must handle:
- Thousands of concurrent streams
- Sudden traffic spikes
- Region-specific latency requirements
- Fault tolerance and retries
Media streaming layers must remain stateless wherever possible. AI workloads, especially LLMs and STT, must scale independently.
Because Teler operates as a global, distributed voice infrastructure, audio streams can be routed to the nearest region, reducing latency and improving reliability.
How Are Reliability And Failures Handled In Real-Time Streaming?
Failures are unavoidable. Networks fluctuate, devices disconnect, and services restart.
Therefore, a real-time voice system must expect and handle failures gracefully.
Important strategies include:
- Automatic reconnection for short network drops
- Session recovery without restarting conversations
- Buffering strategies to smooth jitter
- Monitoring latency, packet loss, and response times
When these mechanisms are built into the streaming layer, application developers do not need to reimplement them.
How Is Security Handled In Live Audio Streaming?
Real-time audio often contains sensitive data. Security must be built into the architecture, not added later.
Key security considerations include:
- Encrypted audio streams in transit
- Secure authentication for streaming sessions
- Proper isolation between conversations
- Careful handling of call data and transcripts
A dedicated media streaming platform simplifies compliance by enforcing these standards consistently.
Why Voice Infrastructure Platforms Are Different From Calling Platforms
Many platforms started with calling as their core feature. They excel at routing calls, playing IVRs, and tracking minutes.
However, AI-driven voice systems have different needs.
They require:
- Real-time streaming APIs
- Tight integration with LLM workflows
- Flexible, model-agnostic design
- Streaming-first architecture
This is the gap that modern voice infrastructure platforms are designed to fill.
What Is The Fastest Path From Prototype To Production?
Teams often start by connecting speech APIs directly to an LLM. This works for demos but breaks under real usage.
A faster and more reliable path includes:
- Using a dedicated streaming layer from day one
- Designing for partial processing at every stage
- Separating voice transport from AI logic
- Planning for scale early, even in prototypes
This approach reduces rework and accelerates deployment.
Final Takeaway
Real-time voice experiences are not defined by a single AI model or speech engine. Instead, they are shaped by how well each technical layer works together. A strong media streaming architecture is the foundation. It allows audio to move continuously, supports parallel processing, and minimizes latency across the entire pipeline. When streaming, transcription, reasoning, and response generation happen in parallel, conversations feel natural instead of delayed. Clear separation between voice infrastructure and AI logic also allows teams to evolve models without rewriting the system.
FreJun Teler is built exactly for this role. It handles real-time voice transport, session control, and low-latency streaming, while giving teams full freedom to plug in any LLM, STT, TTS, or business logic. This approach helps teams move faster, scale reliably, and deliver human-like conversations with confidence.
Schedule a demo with FreJun Teler to see how production-ready voice agents are built from day one.
FAQs
- What makes real-time voice different from regular APIs?
Real-time voice uses continuous streaming instead of request-response, allowing audio and AI processing to run in parallel. - Why is low latency so important for voice agents?
Even small delays break conversational flow and make AI responses feel unnatural or robotic. - Can I use any LLM with a voice agent?
Yes, as long as the voice infrastructure supports streaming input, output, and persistent sessions. - How does streaming STT improve conversations?
Streaming STT provides partial transcripts early, allowing the system to respond faster and more naturally. - Is WebSocket enough for real-time voice streaming?
WebSocket works for many cases, but media-optimized transports often perform better under high concurrency and low latency needs. - Why should TTS also be streamed?
Streaming TTS allows audio playback to begin immediately, instead of waiting for the full response to generate. - Where should conversation context be stored?
Context should live in your backend or AI layer, not inside the voice transport system. - How do voice agents scale reliably?
They scale by separating voice infrastructure from AI logic and using stateless, distributed streaming components. - What role does media streaming architecture play in reliability?
It manages sessions, reconnections, buffering, and timing, which prevents dropped calls and broken conversations.
How does Teler simplify voice agent development?
Teler handles real-time voice streaming and session control, so teams can focus on AI logic instead of telephony complexity.