
Voice-based AI systems are no longer experimental. Today, founders, product teams, and engineering leaders are actively building voice agents that must respond in real time, across networks, and at scale. However, achieving natural conversations is not just about choosing a good speech model or a powerful LLM. Instead, it depends on how audio is captured, streamed, processed, and returned with minimal delay.
This blog breaks down what it truly means to build a voice recognition SDK for low-latency voice streaming. Step by step, we explore the technical foundations, architectural decisions, and real-world constraints that shape modern AI voice pipelines, so teams can build systems that sound responsive, reliable, and human.
What Does Low Latency Mean In Voice Recognition Systems?
Low latency in voice recognition means minimizing the delay between when a person speaks and when the system understands and responds. However, in real-world voice systems, latency is not a single number. Instead, it is the sum of multiple small delays across the entire voice pipeline.
According to ITU recommendations, a one-way mouth-to-ear delay of 150 ms or less is the practical target for natural conversation; delays above this range require careful compensation.
In traditional systems, users could tolerate delays of one or two seconds. However, in modern AI-driven conversations, even a 500-millisecond pause feels unnatural. As a result, low latency is no longer a performance bonus—it is a requirement.
More importantly, perceived latency matters more than raw latency. If the system responds quickly enough to feel conversational, users remain engaged. Otherwise, trust drops instantly.
In practice, low latency voice recognition means:
- Capturing audio without buffering delays
- Processing speech as it is spoken
- Streaming results instead of waiting for completion
- Responding fast enough to allow natural turn-taking
Therefore, a voice recognition SDK built for low latency must treat voice as a real-time stream, not as an audio file.
Why Do Traditional Voice SDKs Fail For Real-Time AI Conversations?
Most voice SDKs were built for telephony, not for AI conversations. As a result, their design assumptions no longer match modern needs.
Traditionally, voice systems were optimized for:
- Call setup and teardown
- DTMF input
- IVR menus
- Recording and playback
However, AI voice agents require something very different.
The core limitations of traditional voice SDKs include:
- Audio is processed in chunks or files
- Speech recognition runs after the user stops speaking
- Responses are generated only after transcription finishes
- Interruptions are difficult to handle
Because of this, conversations feel slow and rigid.
In contrast, real-time AI conversations depend on:
- Continuous audio streaming
- Streaming STT engines
- Partial transcription results
- Early response generation
Therefore, while legacy voice SDKs handle calls well, they struggle with realtime voice processing required by modern AI voice pipelines.
What Components Actually Create Latency In AI Voice Pipelines?
Latency does not come from a single source. Instead, it accumulates across multiple stages. Understanding these stages helps teams design better systems.
Below is a simplified breakdown of where latency is introduced:
| Pipeline Stage | Description | Latency Risk |
| Audio Capture | Microphone or call audio ingestion | Buffering delay |
| Audio Transport | Sending audio to backend | Network jitter |
| Streaming STT | Speech-to-text processing | Model inference delay |
| LLM Processing | Intent understanding and response | Token generation delay |
| TTS Generation | Text-to-speech synthesis | Audio generation delay |
| Playback | Streaming audio back to user | Buffer and decode delay |
Each stage may only add tens of milliseconds. However, when combined, they can easily exceed one second.
Therefore, a low latency audio SDK must optimize the entire pipeline, not just speech recognition.
How Does Streaming STT Reduce Latency Compared To Batch Transcription?
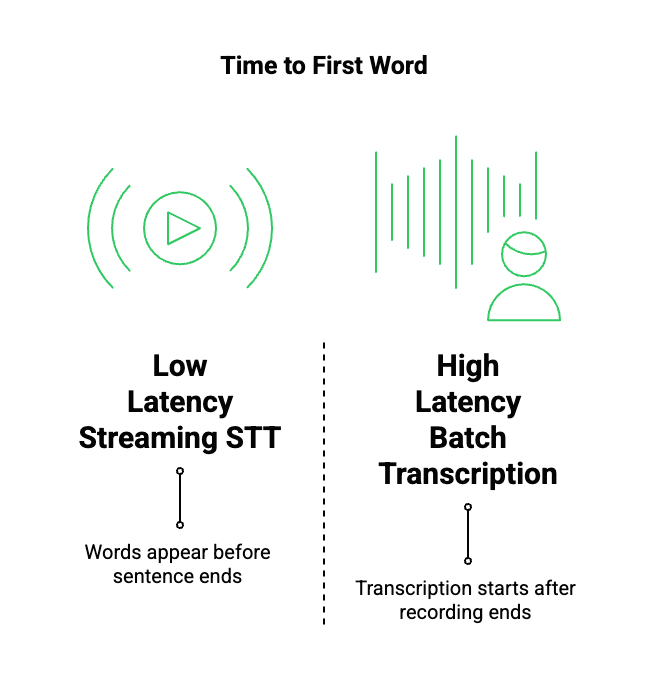
Streaming STT engines are a core requirement for low latency voice recognition. Unlike batch transcription, streaming STT processes audio while the user is speaking.
Batch Transcription (High Latency)
- Audio is recorded fully
- File is sent to STT engine
- Transcription starts only after recording ends
- Result is returned as a complete text
This approach introduces unavoidable waiting time.
Streaming STT (Low Latency)
- Audio is sent in small frames
- Partial transcripts are produced continuously
- Words appear before the sentence ends
- Downstream systems can react early
As a result, streaming STT reduces time to first word, which directly improves perceived responsiveness.
Additionally, streaming STT enables:
- Faster turn detection
- Better interruption handling
- Natural conversational overlap
Because of this, modern voice recognition SDKs rely heavily on streaming STT engines instead of file-based transcription.
Why Is Real-Time Audio Streaming Critical For Natural Conversations?
Even with fast STT, conversations still feel unnatural if audio transport is slow. Therefore, real-time audio streaming is equally important.
In real conversations:
- People interrupt each other
- Responses start before sentences finish
- Silence has meaning
Real-time streaming supports these patterns.
Key Benefits Of Real-Time Audio Streaming
- Continuous bidirectional audio flow
- Immediate detection of speech start and stop
- Support for barge-in and mid-sentence interruption
- Reduced buffering and jitter
Without real-time streaming, systems must guess when a user is done speaking. This often leads to awkward pauses.
Thus, a low latency audio SDK must treat audio as a live stream, not a sequence of uploads.
What Does A Modern AI Voice Pipeline Look Like Today?
Modern voice agents are not single models. Instead, they are pipelines of specialized components, each handling a specific task.
At a high level, a typical AI voice pipeline includes:
- Audio Input: Captures live audio from calls or devices
- Streaming STT Engine: Converts speech into text in real time
- LLM Or AI Agent: Understands intent, manages context, and decides responses
- Context Layer (Memory / RAG): Maintains conversation state and retrieves relevant data
- Tool Calling Layer: Triggers APIs, workflows, or actions
- Streaming TTS Engine: Converts responses back into speech
These components must work together without blocking each other.
Therefore, AI voice pipelines rely on:
- Event-driven architectures
- Streaming APIs
- Non-blocking execution
- Clear separation of concerns
When designed correctly, the system can respond while the user is still speaking.
How Should A Voice Recognition SDK Support Any LLM, STT, Or TTS?
Flexibility is critical. Teams should not be forced into a single AI model or vendor.
A well-designed voice recognition SDK should:
- Remain model-agnostic
- Allow teams to plug in any LLM
- Support multiple streaming STT engines
- Work with different TTS providers
This separation ensures that:
- AI models can evolve independently
- Costs can be optimized over time
- New capabilities can be added without re-architecture
More importantly, the voice SDK should focus on realtime voice processing, not AI logic. The AI remains fully controlled by the application.
Because of this design, teams can build future-proof AI voice pipelines that adapt as models improve.
Where Does Voice Infrastructure Fit In A Low Latency AI Voice System?
After understanding the AI voice pipeline, the next question becomes clear: where does voice infrastructure actually belong?
Voice infrastructure sits between the real world and your AI logic. It is responsible for:
- Capturing live audio from calls or devices
- Streaming audio with minimal delay
- Maintaining stable, bidirectional connections
- Delivering audio reliably across networks
Importantly, it should not:
- Control conversation logic
- Decide responses
- Store long-term memory
- Lock you into specific AI models
Instead, its role is to act as a real-time transport layer for voice.
Because of this separation, voice infrastructure must be:
- Fast
- Predictable
- Streaming-first
- Designed for failure handling
Only then can AI systems respond naturally and consistently.
What Makes Low Latency Voice Streaming Hard At Scale?
Low latency is easy to demonstrate in a demo. However, it is difficult to maintain in production.
Several challenges appear as systems scale:
Network Variability
Users connect from different locations, devices, and networks. As a result:
- Latency fluctuates
- Packet loss increases
- Jitter becomes unpredictable
Therefore, the voice layer must adapt in real time.
Concurrent Conversations
Handling one call is simple. Handling thousands is not.
- Audio streams must remain isolated
- Latency must stay consistent
- Failures must not cascade
Interruptions And Turn Control
People interrupt AI agents often. If the system cannot:
- Detect speech mid-response
- Stop playback immediately
- Resume listening without delay
The conversation breaks down.
Because of these factors, low latency voice streaming is an infrastructure problem, not just an SDK feature.
How Can Teams Build Voice Systems That Stay Fast In Real Conditions?
To stay fast in production, teams must design for worst-case conditions, not best-case scenarios.
Key Design Principles
- Stream everything, block nothing
- Avoid large audio buffers
- Process partial results early
- Keep AI logic asynchronous
- Monitor latency at each stage
Additionally, voice systems should:
- Retry without restarting sessions
- Handle silence intelligently
- Recover from dropped frames gracefully
By following these principles, teams can maintain realtime voice processing even under load.
Where Does FreJun Teler Fit Into This Architecture?
FreJun Teler fits precisely at the voice infrastructure layer of the AI voice pipeline.
It is designed to:
- Capture live audio from inbound and outbound calls
- Stream audio with low latency
- Maintain stable bidirectional voice connections
- Work across PSTN, SIP, and VoIP networks
Crucially, Teler does not replace your AI.
Instead:
- You bring your own LLM
- You choose your STT and TTS providers
- You control conversation logic and memory
Teler focuses only on voice transport and streaming reliability, allowing your AI systems to operate without voice-layer constraints.
How Does FreJun Teler Enable Low Latency Voice Streaming In Practice?
FreJun Teler’s design centers on streaming-first voice handling, not call recording or playback.
Real-Time Audio Capture
- Audio is captured as continuous streams
- No waiting for full utterances
- Minimal buffering at ingress
Streaming Audio Delivery
- Audio frames are streamed immediately to your backend
- Compatible with streaming STT engines
- Supports partial and final transcription flows
Bidirectional Voice Control
- Audio responses are streamed back into live calls
- Playback can be interrupted instantly
- Listening resumes without reconnecting
Network Resilience
- Handles jitter and packet loss gracefully
- Maintains session stability across variable networks
- Keeps latency consistent under load
As a result, Teler acts as a low latency audio SDK purpose-built for AI voice agents, not traditional IVRs.
How Does Teler Support Any LLM, STT, Or TTS Provider?
Flexibility is built into the core architecture.
Teler does not embed:
- A fixed LLM
- A proprietary STT engine
- A locked TTS voice
Instead, it exposes:
- Real-time audio streams
- Event-based session control
- Clear boundaries between voice and AI
This allows teams to:
- Swap LLMs without changing voice logic
- Test multiple streaming STT engines
- Optimize TTS for latency or quality
Because of this, teams can build AI voice pipelines that evolve over time without rewriting infrastructure.
What Does A Production-Ready Voice Recognition SDK Require?
When evaluating a voice recognition SDK, teams should look beyond demos.
A production-ready system must support:
Latency Consistency
- Stable performance across regions
- Predictable time-to-first-response
Observability
- Audio-level logs
- Latency metrics per pipeline stage
- Clear failure diagnostics
Scalability
- Thousands of concurrent streams
- No degradation under load
Control
- Session-level interruption handling
- Fine-grained audio control
- Clear SDK abstractions
Without these, even fast systems become unreliable in real use.
How Do Teams Use This Stack For Inbound Voice Agents?
Inbound voice agents benefit directly from low-latency design.
Typical flow:
- Call arrives
- Audio is streamed immediately
- Streaming STT generates partial text
- LLM begins intent processing early
- TTS response streams back naturally
Because latency is low:
- Users do not wait
- Conversations feel fluid
- Fewer repeats are needed
As a result, resolution rates improve.
How Does Low Latency Impact Outbound AI Voice Agents?
Outbound calls face additional challenges:
- Users answer unexpectedly
- Attention is limited
- Silence leads to hang-ups
Low latency voice streaming helps by:
- Responding immediately after greeting
- Handling interruptions gracefully
- Maintaining natural pacing
Therefore, outbound AI agents rely heavily on realtime voice processing to remain effective.
What Are Common Mistakes Teams Make When Building Voice Agents?
Even experienced teams make avoidable mistakes.
Frequent Issues
- Using batch STT instead of streaming
- Blocking on full LLM responses
- Ignoring interruption handling
- Treating voice as an afterthought
- Hardcoding AI providers
Each of these increases perceived latency.
Instead, teams should:
- Design for streaming first
- Measure latency continuously
- Keep voice and AI loosely coupled
How Should Founders And Engineering Leads Evaluate Voice SDKs?
Before choosing a platform, teams should ask:
- Can this handle real-time streaming end to end?
- Does it support interruptions cleanly?
- Can we change AI providers easily?
- How does it behave under load?
- What latency metrics are exposed?
If these questions cannot be answered clearly, the SDK may not scale.
Final Thoughts
Building a voice recognition SDK for low-latency voice streaming is fundamentally an infrastructure challenge. While AI models continue to improve, the quality of voice experiences still depends on how efficiently audio moves through the system. Streaming STT, real-time transport, interruption handling, and predictable latency all play a critical role in making voice agents feel natural. For teams building AI-driven voice applications, separating voice infrastructure from AI logic is essential for long-term flexibility and scale.
FreJun Teler is designed precisely for this role, providing a real-time, low-latency voice streaming layer that integrates cleanly with any LLM, STT, or TTS stack.
If you’re building production-grade voice agents and want full control without infrastructure complexity, schedule a demo to see how Teler fits into your AI voice architecture.
FAQs –
1. What is a voice recognition SDK used for?
A voice recognition SDK captures audio, converts speech to text, and enables real-time voice interactions in applications.
2. Why is low latency important for voice agents?
Low latency ensures conversations feel natural, responsive, and human-like, without awkward pauses or delayed responses.
3. What is streaming STT?
Streaming STT processes audio continuously, producing partial transcriptions before the speaker finishes talking.
4. How is batch transcription different from streaming STT?
Batch transcription waits for full audio, while streaming STT processes speech in real time, reducing response delays.
5. What causes latency in voice AI systems?
Latency comes from audio buffering, network transport, STT processing, LLM response time, and TTS generation.
6. Can I use any LLM with a voice recognition SDK?
Yes, modern voice SDKs should be model-agnostic and allow integration with any LLM or AI agent.
7. What role does voice infrastructure play in AI pipelines?
Voice infrastructure handles real-time audio streaming while AI systems manage understanding, reasoning, and responses.
8. Is low latency only a network problem?
No, latency is cumulative and depends on architecture, streaming design, model behavior, and infrastructure placement.
9. How do interruptions affect voice agent performance?
Without real-time streaming, interruptions cause delays and broken conversations, reducing trust and usability.
10. Who should care about low latency voice systems?
Founders, product managers, and engineering leads building scalable, AI-driven voice applications should prioritize it.