
Imagine you are traveling in a foreign country. You lose your wallet. Panic sets in. You call the local police station or the bank, but the person on the other end only speaks a language you do not understand. You try to explain, but the barrier is too high and you hang up, frustrated and helpless.
Now, apply this to business. Every day, customers call companies looking for help. If your support line only speaks English, you are effectively hanging up on a massive portion of the world’s population. In a global economy, language is the last great barrier.
But today, that barrier is crumbling. Thanks to advances in AI, we can now build systems that understand and speak dozens of languages fluently. We can create a global voice for your brand that adapts to the caller instantly.
Building this requires a specific tool: a voice recognition software API. This tool acts as the universal translator, converting spoken sounds from any language into text that your system can process.
However, understanding the words is only half the battle. You also need to transport those words clearly and quickly across borders. In this guide, we will explore how to build multilingual speech recognition systems, how to handle real-time language detection, and why the underlying infrastructure provided by platforms like FreJun AI is the secret ingredient to making it all work.
Table of contents
- Why Is Multilingual Support Essential for Global Business?
- How Does a Voice Recognition Software API Handle Multiple Languages?
- What Is the Role of Language Detection?
- How Do You Build a Global Voice Infrastructure?
- How to Implement Multilingual Speech? (Step-by-Step)
- What Are the Challenges of Multilingual Speech?
- How Does FreJun AI Solve the Latency Problem?
- Can You Use AI for Real-Time Translation?
- What About Privacy and Data Sovereignty?
- Conclusion
- Frequently Asked Questions (FAQs)
Why Is Multilingual Support Essential for Global Business?
For a long time, English was considered the “universal language” of business. While that is still true in boardrooms, it is not true for consumers. When people are spending their own money or asking for help, they want to speak in their mother tongue.
It is a matter of trust. It is hard to trust a company when you cannot understand the terms and conditions.
76% of online shoppers prefer to buy products with information in their native language. Even more telling, 40% will never buy from websites in other languages.
If you ignore multilingual support, you are actively turning away customers. A voice recognition software API allows you to scale your support to new regions without hiring armies of local agents. You can have one AI agent that speaks Spanish, Mandarin, Hindi, and Arabic, available 24/7.
How Does a Voice Recognition Software API Handle Multiple Languages?
To understand how to implement this, we need to look at how the technology processes sound.
Human speech is just a wave of air pressure. A voice recognition software API takes that wave and breaks it down into “phonemes,” which are the smallest units of sound.
Acoustic Models
Different languages use different sounds. The “r” sound in French is very different from the “r” sound in English or Spanish. The API uses an acoustic model trained on thousands of hours of audio from a specific language to recognize these unique sounds.
Language Models
Once the sounds are identified, the API uses a language model to guess the words. It knows that in English, “the” is likely to be followed by a noun. In Spanish, the grammar rules are different.
When you integrate a voice recognition software API, you typically send a configuration code telling it which “brain” to use. For example, you might send a tag like en-US for American English or ja-JP for Japanese.
The challenge arises when you do not know what language the caller will speak.
Also Read: Automating License Renewals with AI Calls
What Is the Role of Language Detection?
Imagine a call center in Europe. A call comes in. It could be French, German, Italian, or Dutch. You cannot ask the user to “Press 1 for German” if they don’t understand the instruction to press 1.
You need automated language detection. This is a feature of advanced voice recognition software API systems.
Here is how it works:
- The Listen: The system captures the first few seconds of audio (e.g., “Hallo, ich brauche Hilfe”).
- The Analysis: The API analyzes the phonemes and intonation.
- The Switch: The system identifies the language as German (de-DE) and instantly switches the speech-to-text engine and the response bot to German mode.
- The Response: The AI replies, “Wie kann ich Ihnen helfen?”
The Latency Challenge
This process must happen in milliseconds. If the user says “Hello” and waits five seconds for the system to figure out it is English, they will hang up.
This is where FreJun AI becomes critical. We handle the complex voice infrastructure so you can focus on building your AI. For language detection to work fast, the audio stream must be pristine and the connection must be low latency. FreJun streams the media in real time, ensuring that the detection engine gets the data immediately.
How Do You Build a Global Voice Infrastructure?
If you are serving customers in Brazil, India, and Germany, you cannot host your voice server in a single basement in New York. The laws of physics will hurt you.
Data takes time to travel. If a user in Mumbai speaks, and the audio has to travel to New York to be processed, there will be a delay. In a conversation, even a half-second delay makes people talk over each other. This is called “latency.”
To support global voice, you need a distributed infrastructure.
Global Points of Presence (PoPs)
You need servers located close to your users. When a user calls from Europe, the call should be handled by a European server.
Elastic SIP Trunking
You need a way to connect calls from local telephone networks to your cloud. FreJun Teler provides elastic SIP trunking. This allows you to purchase phone numbers in over 100 countries. Whether a customer calls a local number in London or Lagos, FreJun Teler accepts the call locally and routes it efficiently.
How to Implement Multilingual Speech? (Step-by-Step)
If you are a developer looking to build this, here is your roadmap.
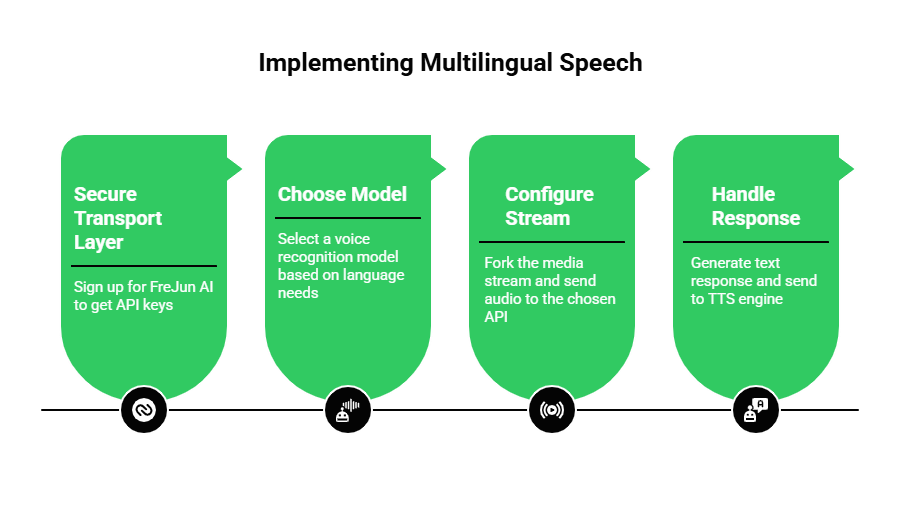
Step 1: Secure Your Transport Layer
Before you pick a translation engine, you need a way to get the audio from the phone network to your code. Sign up for FreJun AI to get your API keys. FreJun will act as your “ears,” capturing the audio from the PSTN (telephone network).
Step 2: Choose Your Model
FreJun is model-agnostic. This is a huge advantage for multilingual support. Some AI models are better at Asian languages (like Chinese), while others are better at Romance languages (like Spanish).
- You can route audio to OpenAI’s Whisper for general purpose.
- You can route to Google Speech-to-Text for specific dialect support.
- You can route to Deepgram for speed.
Step 3: Configure the Stream
Use FreJun’s SDK to fork the media stream. Send the raw audio to your chosen voice recognition software API.
- If you know the language (e.g., a specific Spanish marketing campaign), hardcode the language tag es-ES.
- If you don’t know, enable the detect_language feature in your transcription service.
Step 4: Handle the Response (TTS)
Once the user’s intent is understood, generate a text response. Then, send that text to a Text-to-Speech (TTS) engine that supports the matching language. Finally, stream that audio back through FreJun to the caller.
What Are the Challenges of Multilingual Speech?
It sounds magical, but it is difficult to get right. Here are the common hurdles developers face.
1. Code-Switching
In many parts of the world, people mix languages. A caller in India might speak “Hinglish” (Hindi + English). A caller in Miami might speak “Spanglish.” Most basic APIs get confused by this. They try to force the sounds into one language, resulting in gibberish.
To solve this, you need high-fidelity audio. The clearer the audio, the better the AI can distinguish the subtle shifts in pronunciation. FreJun’s focus on uncompressed, low-latency media streaming gives the AI the best possible chance to decode these complex speech patterns.
2. Accents and Dialects
English is spoken differently in Scotland, Texas, and Singapore. Spanish is different in Spain versus Mexico.
A robust multilingual speech recognition system must handle these variations.
| Challenge | Impact on Voice Bot | Solution |
| Heavy Accents | Bot misunderstands words | Use “fine-tuned” models trained on local accents. |
| Background Noise | Disrupts language detection | Use FreJun’s noise-suppression capabilities. |
| Latency | awkward pauses during translation | Use a low-latency transport layer (FreJun). |
| Vocabulary | Local slang is missed | Update the custom vocabulary in the API regularly. |
Also Read: Handling Parent Queries with Voice AI
How Does FreJun AI Solve the Latency Problem?
We keep mentioning latency because it is the killer of voice AI. In a multilingual flow, the processing time is doubled.
- Step 1: Transcribe (Speech to Text)
- Step 2: Translate (Text to Text)
- Step 3: Generate Audio (Text to Speech)
Each step takes milliseconds. If you add network lag on top of that, the pause becomes unbearable.
FreJun AI minimizes the network lag. By optimizing the routing of the media packets, we shave precious milliseconds off the total round-trip time. We ensure that the audio arrives at the translation engine instantly.
Furthermore, with FreJun Teler, we ensure the call setup is instant. When you scale your operations to new countries, Teler handles the carrier negotiations and connectivity, ensuring a stable line quality that is essential for accurate recognition.
Can You Use AI for Real-Time Translation?
Yes. This is often called the “Universal Translator” use case.
Imagine a conference call. One person speaks Japanese. The other speaks English. An AI sits in the middle.
- FreJun captures the Japanese audio.
- The API transcribes it to Japanese text.
- An LLM translates it to English text.
- A TTS engine speaks the English text to the other party.
This requires extreme speed. It is the Formula 1 of voice engineering. You cannot afford a slow infrastructure. FreJun’s architecture is built exactly for these high-performance streaming use cases.
What About Privacy and Data Sovereignty?
When you go global, you deal with global laws. The EU has GDPR. California has CCPA.
When you capture voice data from a German citizen, you have to be careful where that data is stored and processed.
Using a voice recognition software API adds a layer of complexity. You need to ensure that the API provider is compliant.
FreJun helps by providing a secure transport layer. We encrypt voice data in transit using SRTP (Secure Real-time Transport Protocol) and do not store your data to train our own models. We simply transport it securely to your chosen processor. This gives enterprises the control they need to meet strict compliance standards across different regions.
Also Read: Automating Fee Reminders with AI Calls
Conclusion
The world is not monolingual. Your business shouldn’t be either.
By leveraging a voice recognition software API, you can break down language barriers and serve customers in the way they prefer—in their own voice, in their own language. It builds trust, increases sales, and democratizes access to your services.
However, the software is only as good as the connection it runs on. Multilingual speech recognition and real-time language detection require a flawless, high-speed audio stream. If the audio is choppy, the translation fails.
FreJun AI provides the global voice infrastructure you need. With FreJun Teler handling the global connectivity and our low-latency streaming technology delivering the audio, you can build a truly polyglot AI agent that sounds natural in any language.
Want to discuss your global voice strategy? Schedule a demo with our team at FreJun Teler and let us help you speak the world’s languages.
Also Read: How Businesses Use Outbound Calls for Lead Generation & Pipeline Growth
Frequently Asked Questions (FAQs)
1. What is a voice recognition software API?
A voice recognition software API is a tool that allows developers to convert spoken language into text programmatically. It enables applications to “hear” and understand what users are saying.
2. How does the API know which language to listen for?
You can either tell the API the language code (like fr-FR for French) or use an “auto-detect” feature where the API listens to the first few seconds of audio and guesses the language.
3. Can I support multiple languages in one call?
Yes. Advanced systems can handle code-switching, where a user switches between languages. However, this requires very high-quality audio and sophisticated AI models.
4. Does FreJun AI provide the translation model?
No. FreJun provides the voice infrastructure (the transport). We capture the audio and stream it to your chosen translation or transcription provider (like Google or OpenAI). This gives you the flexibility to choose the best model for each language.
5. What is the hardest part of multilingual voice support?
Latency (delay) and accents. Translating takes time, and heavy accents can confuse the AI. Using a high-quality infrastructure provider like FreJun helps minimize these issues.
6. What is FreJun Teler?
FreJun Teler is our telephony solution that provides elastic SIP trunking. It allows you to buy and manage phone numbers globally, ensuring you can connect with customers in different countries locally.
7. Is real-time translation possible on a phone call?
Yes, but it requires a very fast internet connection and optimized infrastructure. The delay must be kept under a second for the conversation to feel natural.
8. Which languages can I support?
Most modern APIs support over 50 languages, including major ones like English, Spanish, Mandarin, Hindi, Arabic, and Portuguese.
9. How do I handle data privacy in Europe (GDPR)?
You must ensure that your voice provider and your API processor are GDPR compliant. FreJun encrypts data in transit and allows you to control where your data is sent, helping you meet these requirements.
10. Do I need to hire linguists to build this?
Not necessarily. Modern AI models are pre-trained on millions of hours of audio. However, having a native speaker test your bot is always a good idea to ensure it understands cultural nuances.