
For developers, the allure of creating a truly intelligent Audio Chat Bot is undeniable. It’s a challenge that sits at the intersection of complex engineering and human-centric design. We’ve all seen the polished demos where an AI converses with perfect, fluid grace.
But as any developer who has ventured into this space knows, the gap between a simple demo and a production-ready, real-time voice agent is a vast chasm filled with latency, network complexity, and a hundred hidden points of failure.
The market is flooded with “no-code” and “all-in-one” platforms that promise to bridge this gap for you. They offer a simple, pre-packaged solution, a “black box” that gets you started quickly. But for a true builder, a black box is a cage. It hides the inner workings, limits your creativity, and puts an unmovable ceiling on your application’s performance.
This guide is for the architects, the creators, the developers who don’t want a black box. It’s a blueprint for building a “glass box”, a real-time Audio Chat Bot where you have full, granular API control over every single component. This is the path to creating a voice experience that is not just functional, but exceptional.
Table of contents
- Why is Full API Control a Non-Negotiable for Developers?
- What is the Engineering Blueprint for a Real-Time Audio Chat Bot?
- How Do You Implement the Real-Time Conversational Loop Step-by-Step?
- What Advanced Techniques Elevate a Bot from Functional to Exceptional?
- Conclusion
- Frequently Asked Questions (FAQs)
Why is Full API Control a Non-Negotiable for Developers?
Choosing an API-first architecture over a closed platform is the single most important decision you will make. It’s a strategic choice that prioritizes power, flexibility, and long-term viability over short-term convenience.
How Does an API-First Approach Prevent Vendor Lock-In?
The world of AI is moving at a blistering pace. The best Large Language Model on the market today could be surpassed by a new, more efficient, or more powerful model in six months. In a closed, “black box” platform, you are completely at the mercy of the vendor to integrate that new technology.
With an API-driven approach, you are in control. You can swap out your Speech-to-Text engine, upgrade your LLM, or test a new Text-to-Speech voice with a few changes to your code, ensuring your application is always at the cutting edge.
Why is Granular Control Essential for Performance?
In a real-time voice conversation, every millisecond counts. A closed platform gives you no visibility into the performance bottlenecks. An API-driven architecture, however, is a “glass box.” You can measure the latency of every single step in the chain: the audio transport, the STT transcription, the LLM’s “time to first token,” and the TTS synthesis.
This visibility is what allows you to obsessively optimize your system for the lowest possible latency, which is the key to a natural-sounding conversation. The demand for this speed is not just a preference; it’s an expectation.
A recent HubSpot survey found that a remarkable 90% of customers rate an “immediate” response as important or very important when they have a customer service question.
How Does It Unlock True Customization?
A closed platform forces you to work within the constraints of its pre-built logic. An API-first approach gives you a blank canvas. You can build sophisticated, multi-step workflows that involve complex “tool calling,” create dynamic conversational paths based on a user’s sentiment, and design a bot with a personality that is truly unique to your brand.
Also Read: The Rise of Conversational Voice AI Assistants in Banking
What is the Engineering Blueprint for a Real-Time Audio Chat Bot?
To build a high-performance Audio Chat Bot with full API control, you must think like a system architect. Your application is not a single entity; it’s a distributed system of specialized components, all communicating in real-time.

Think of it like building a high-performance race car from scratch. You wouldn’t just buy a standard engine off the shelf; you’d choose the best components for each part of the system.
- The Chassis (The Voice Infrastructure): This is the foundational frame of your car. It must be incredibly strong, lightweight, and aerodynamic. In the world of voice, this is your voice infrastructure. A platform like FreJun AI provides this essential chassis. It’s the high-performance, ultra-low-latency framework that handles all the real-world connectivity and provides the smooth, stable ride for your other components.
- The Engine (The LLM): This is the core of your car’s power. This is your Large Language Model. With an API-first approach, you get to choose your engine, do you want the raw power of a GPT-4o, or the high-efficiency performance of a Gemma 2?
- The Sensors (The STT): These are the car’s sensors, feeding it real-time data about the track ahead. This is your Speech-to-Text engine, which must be incredibly fast and accurate.
- The Exhaust Note (The TTS): This is the sound your car makes, its personality. This is your Text-to-Speech engine. You can choose a voice that is aggressive and sporty or smooth and luxurious, perfectly matching your brand.
Also Read: How to Enhance Voice Bot Efficiency in E-Commerce
How Do You Implement the Real-Time Conversational Loop Step-by-Step?
Now, let’s get into the code. The core of your application will be a “main event loop” that orchestrates the flow of data between these components.
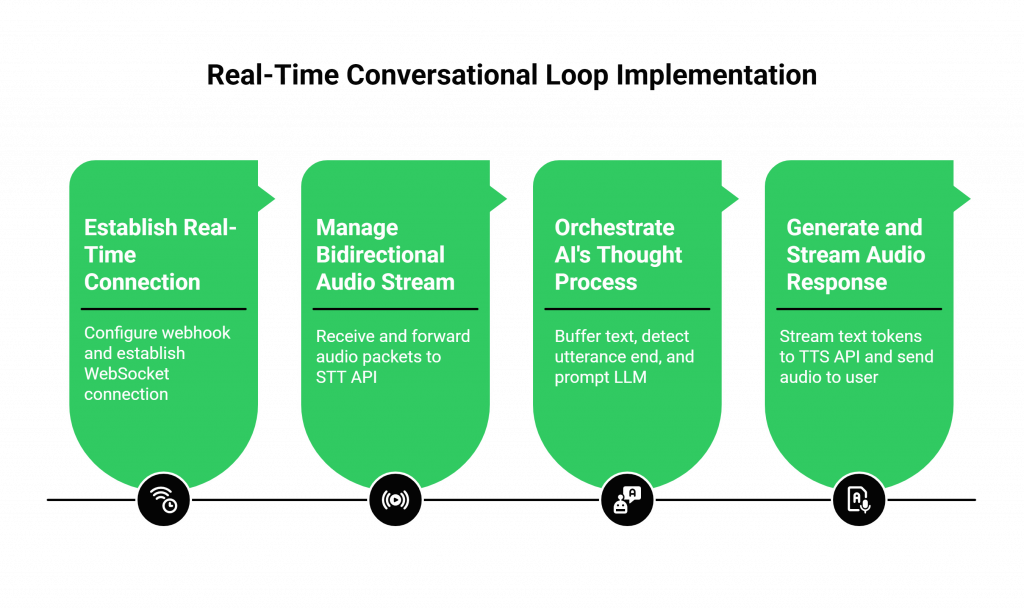
Step 1: How Do You Establish the Real-Time Connection?
It all starts with the connection to the outside world. With a voice API for developers like FreJun AI, you’ll configure a webhook for your phone number or web client. When a call starts, your server receives an initial webhook.
Your server’s response to this webhook is a command that tells the FreJun AI platform to establish a persistent, two-way audio stream using WebSockets. This is the starting pistol for your real-time loop.
Step 2: How Do You Manage the Bidirectional Audio Stream?
Once the WebSocket is open, your server has a live, raw audio feed from the user. Your server’s primary job is to act as a high-speed traffic controller. It receives the incoming audio packets from FreJun AI and immediately forwards them to your chosen streaming STT API.
Step 3: How Do You Orchestrate the AI’s “Thought Process”?
As the STT API sends back a live transcript, your server begins its most important work.
- It buffers the incoming text and uses an “end-of-utterance” detection algorithm to know when the user has finished speaking.
- It then constructs a detailed prompt for your LLM, including the full conversation history (which should be stored in a fast, external cache like Redis) and the user’s latest message.
- It makes a streaming API call to your LLM. A streaming LLM is crucial for low latency, as it starts returning the response word-by-word, rather than waiting to generate the entire sentence.
Step 4: How Do You Generate and Stream the Audio Response?
As your server receives the text tokens from the streaming LLM, it doesn’t wait. It immediately begins sending these tokens to your chosen streaming TTS API. The TTS API, in turn, begins sending back chunks of audio data. Your server takes this generated audio and streams it back to the FreJun AI platform through the open WebSocket, which then plays it to the user. This “first-word-out” approach is the key to a snappy, responsive bot.
Ready to build a voice assistant that your customers will love? Sign up for FreJun AI’s developer-first voice API.
Also Read: How To Build Secure Voice Agents For Healthcare?
What Advanced Techniques Elevate a Bot from Functional to Exceptional?
Once you have the basic loop running, full API control allows you to implement advanced features that are often impossible in a closed platform.
- Interruptibility (“Barge-In”): This is the ability of the user to interrupt the bot while it’s speaking. This requires a voice infrastructure that supports full-duplex audio and an application that can detect incoming user audio and gracefully stop its own playback.
- Acoustic Event Detection: Your application can be programmed to listen for more than just words. It can detect long periods of silence (prompting the user with a “are you still there?”), or it can detect DTMF tones (keypad presses) to securely capture sensitive information without it ever touching the AI models.
The business impact of creating such a high-quality experience is enormous. A recent report from PwC found that customers are willing to pay up to 16% more for a great customer experience.
Conclusion
Building a real-time Audio Chat Bot with full API control is the ultimate expression of a developer’s craft. It’s about moving beyond the drag-and-drop interfaces and architecting a high-performance, custom solution from the ground up. It’s a commitment to performance, a dedication to flexibility, and a belief that the best customer experiences are built, not bought off the shelf.
By combining the best AI models on the market with a high-performance, developer-first voice infrastructure, you have all the tools you need to build the future of customer communication.
Want to learn more about the infrastructure that powers the most advanced audio chat bots? Schedule a demo with FreJun AI today.
Also Read: What Is an Auto Caller? Features, Use Cases, and Top Tools in 2025
Frequently Asked Questions (FAQs)
The main advantage is control. It gives you the freedom to choose your own “best-of-breed” AI models (STT, LLM, TTS), build completely custom logic, and optimize every component for the best possible performance.
A non-streaming (or “batch”) API requires you to send the entire piece of data at once and wait for the full response. A streaming API allows you to send and receive data in a continuous flow of small chunks. For a real-time Audio Chat Bot, using streaming APIs for every component is essential for achieving low latency.
A WebSocket is a communication protocol that provides a persistent, two-way connection between a client and a server. It’s perfect for real-time voice because it allows audio data to be streamed back and forth continuously with very low delay.
This is the process of algorithmically determining when a user has finished speaking their sentence or phrase. This is a critical piece of logic in your backend that tells your application when to stop listening and start “thinking” (i.e., call the LLM).
Look for a provider that is “developer-first.” This means they should have excellent, detailed documentation, robust and easy-to-use SDKs, and a strong focus on API performance, reliability, and security. A model-agnostic approach is also a major plus.
Yes, absolutely. RAG is a form of “tool calling.” Your backend application would simply make an additional API call to your vector database to retrieve the relevant context before it calls the LLM.
Security is handled in layers. You must use API keys for authentication, webhook signature validation to protect your endpoints, and a voice provider that offers end-to-end encryption (SRTP/TLS) for the voice data itself.
“Barge-in,” or interruptibility, is the feature that allows a user to speak over the bot and have the bot gracefully stop talking and listen to them. This is a key feature for making a bot feel more natural and less robotic.
FreJun AI provides the foundational voice infrastructure. It is the specialized component that handles the complex telephony and the ultra-low-latency, real-time audio streaming via APIs and WebSockets. It acts as the high-performance “chassis” upon which you can build your custom AI engine.
Not necessarily. While it requires a development investment, the operational costs can be much lower at scale. You have the freedom to choose the most cost-effective AI models (including open-source models), and you can optimize your infrastructure to only pay for the resources you use.