
As developers, we have become masters of the text-based chatbot. We’ve built sophisticated “brains” that can understand user intent, connect to databases, and provide intelligent answers. Our bots are smart, but for the most part, they are silent. They are logical engines trapped behind a keyboard, waiting for a user to type.
But the next evolution is already here. It is about breaking the silence and giving your chatbot the power of speech. Creating AI chatbot voice functions is not about simply reading text out loud; it’s an architectural challenge that requires a deep dive into the world of real-time APIs. It’s about building a high-speed, event-driven system that can process the fluid, messy, and time-sensitive nature of a human conversation.
This guide is for the developer who wants to move beyond the silent world of text. We will dissect the anatomy of a voice-enabled chatbot, explore the critical role of real-time APIs, and provide a technical blueprint for building a backend that can handle the complex, high-speed orchestration of a truly conversational AI.
Table of contents
Why is a Real-Time API Architecture Essential for Voice?
When a user interacts with a text chatbot, they have a certain tolerance for delay. A one or two-second pause before a text response appears is often acceptable. In a voice conversation, that same one-second pause feels like an eternity. It’s an awkward, unnatural silence that shatters the illusion of a real conversation.
This is why “real-time” is the single most important concept in voice AI. To create a natural-sounding AI chatbot voice, the entire system must be optimized for speed. This is a challenge that traditional, request-response APIs were not designed to handle.
A real-time voice architecture, on the other hand, is built on a foundation of persistent, streaming communication. The demand for such seamless interactions is not just a preference, it’s a core business driver.
A recent report from PwC found that customers are willing to pay up to 16% more for a great customer experience, and a fast, responsive voice AI is a hallmark of a premium experience.
What Are the Core “Voice Functions” of an AI Chatbot?
To voice-enable your chatbot, you need to build a new set of functions in your backend that can handle the entire audio lifecycle. These functions, all powered by real-time APIs, act as the “senses” and “vocal cords” for your existing chatbot’s “brain.”
How Do You Implement the “Listen” Function?
This is the entry point for all voice interactions. The “Listen” function’s job is to capture the raw audio from the user and convert it into text that your chatbot’s brain can understand. This is a multi-step, real-time process:
- Audio Capture: A client-side SDK or a telephony connection establishes a secure, real-time audio stream.
- Audio Streaming: This raw audio is streamed to your backend server.
- Real-Time Transcription: Your backend continuously forwards this audio stream to a Speech-to-Text (STT) API, which sends back a live, rolling transcript.
- Utterance Detection: A crucial piece of logic in your backend detects when the user has finished speaking, packaging the final transcript for the next step.
Also Read: How To Build Multimodal AI Agents With Voice?
How Do You Implement the “Think” Function?
This is where you connect the voice to your existing intelligence. The “Think” function’s job is to take the transcribed text and get a response from your chatbot’s core logic.
- Call the Brain: Your backend takes the final transcript from the “Listen” function and makes a standard API call to your existing chatbot’s API endpoint.
- Context Management: This function is also responsible for maintaining the “memory” of the conversation. It retrieves the conversation history from a cache (like Redis) and sends it to your chatbot’s brain along with the new transcript, ensuring a context-aware response.
- Receive the Response: Your chatbot’s brain returns its intelligent response in text format.
How Do You Implement the “Speak” Function?
This is the final step that closes the conversational loop. The “Speak” function’s job is to take your bot’s text response and convert it into audible, human-like speech.
- Real-Time Synthesis: Your backend takes the text response from the “Think” function and streams it to a Text-to-Speech (TTS) API. Using a streaming TTS is critical for low latency.
- Audio Streaming: The TTS API sends back a stream of generated audio data.
- Playback: Your backend immediately forwards this audio stream to the voice infrastructure, which then plays it to the user.
What is the Role of a Voice Infrastructure API in This Architecture?
As you can see, your backend application is the conductor of a complex, high-speed orchestra. But this orchestra needs a concert hall. The voice infrastructure is that concert hall. It’s the specialized, foundational layer that handles the incredibly complex and resource-intensive task of managing the real-time audio streams.
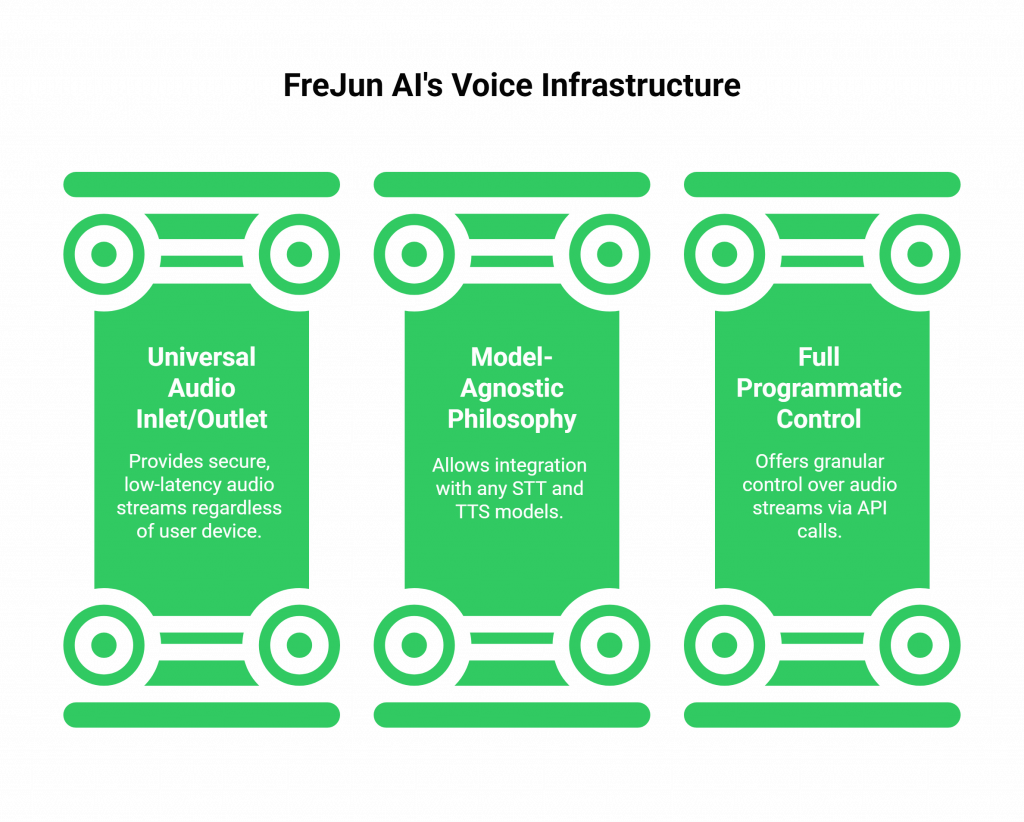
A platform like FreJun AI provides this essential infrastructure through a powerful, developer-first voice API. Our philosophy is simple: “We handle the complex voice infrastructure so you can focus on building your AI.”
- The Universal Audio Inlet/Outlet: FreJun AI is the secure and reliable “front door” for your audio. Our APIs and WebSockets provide a clean, standardized, and ultra-low-latency stream of audio, regardless of whether the user is on a phone call or speaking through their web browser. We handle all the messy work of telephony, codecs, and network traversal.
- The Model-Agnostic Philosophy: We believe you should have the freedom to choose your own “musicians.” Our infrastructure is model-agnostic. This means you can integrate your own existing chatbot “brain” and choose the absolute best STT and TTS models from any provider on the market.
- Full Programmatic Control: Our API gives you the granular control you need to build these complex, real-time functions. You can start, stop, and fork audio streams with simple API calls, giving you the power to orchestrate the conversation with precision.
Ready to start building a truly custom voice experience without the heavy lifting? Sign up and get your FreJun AI API keys in minutes.
Also Read: How To Setup Voice Webhook Flows For LLM Agents?
What Advanced Functions Can You Build with Full API Control?
Once you have this core architecture in place, the power of a full API-driven approach allows you to build sophisticated features that create a truly next-generation AI chatbot voice.
How Do You Implement Interruptibility (“Barge-In”)?
Human conversations are not a perfect turn-by-turn exchange. People interrupt each other. Your backend can be programmed to handle this. It requires your voice infrastructure to support full-duplex audio. Your “Listen” function can be designed to detect incoming user audio even while your “Speak” function is active.
When an interruption is detected, it can gracefully stop the playback and immediately switch focus to processing the user’s new request.
How Do You Build a “Thinking” Indicator?
In a human conversation, when we’re thinking, we often give a small auditory cue, like “hmm…” or “let me see.” You can build this into your “Think” function. If your chatbot’s brain is performing a slow action (like calling an external tool), you can have your “Speak” function play a short, pre-recorded audio file of a “thinking” sound.
This small detail can make a long pause feel much more natural. The need for such human-centric design is growing; a recent report on digital trends found that 63% of consumers are more likely to buy from a company with a great customer experience.
Also Read: How To Add Real-Time Agent Assist To Contact Centers?
Conclusion
Adding an AI chatbot voice is a backend developer’s challenge. It’s about architecting a high-performance, real-time system that can flawlessly orchestrate a team of specialized AI models. By embracing a modern, API-first approach and building on a solid foundation of a developer-centric voice infrastructure, you can move beyond the limitations of the silent web.
You have the power to create a voice interface that is not just a feature, but a truly transformative experience, one that is faster, more accessible, and more human than ever before.
Intrigued by what a truly developer-first voice API can do for your project? Schedule a personalized demo with our technical experts to see the FreJun AI platform in action.
Also Read: What Is Click to Call and How Does It Simplify Business Communication?
Frequently Asked Questions (FAQs)
The backend is critical because it acts as the central orchestration hub. It manages the real-time data flow, securely houses the API keys for all the AI models, and contains the core business logic, ensuring security, scalability, and control.
A standard REST API is based on a simple request-response model. A real-time API, often using WebSockets, provides a persistent, two-way connection that allows for a continuous, low-latency stream of data, which is essential for voice.
No. As long as your existing chatbot can be accessed via an API that accepts and returns text, you can build these voice functions around it. Your backend will act as a translator between the world of voice and your existing text-based AI.
Utterance detection is the process of algorithmically determining when a user has finished speaking their sentence or phrase. This is a critical piece of logic in your backend “Listen” function that tells your application when to stop listening and start processing the request.
The single biggest challenge is minimizing latency. The entire loop, from the user speaking to the bot responding, must happen in under a second to feel natural. This requires a high-performance voice infrastructure and the use of streaming APIs for every component.
A model-agnostic voice infrastructure, like FreJun AI, is not tied to a specific AI provider. It gives you the freedom to choose your own STT, LLM, and TTS models from any company, allowing you to build a solution with the best possible components.
Yes. A key benefit of centralizing your logic in the backend is that the same “Think” and “Speak” functions can be used for any input source. You would simply have a different “Listen” function that ingests audio from a telephony stream (via your voice infrastructure) instead of a web stream.
The unique voice is determined by the Text-to-Speech (TTS) engine you choose. You can select a TTS provider that offers a wide variety of stock voices to find one that matches your brand’s personality, or even work with some providers to create a custom, unique voice.
“Barge-in,” or interruptibility, is the feature that allows a user to speak over the bot and have the bot gracefully stop talking and listen to them. This is an advanced function that creates a more natural and less robotic conversation.
FreJun AI provides the essential voice infrastructure. It handles the complex and resource-intensive task of managing the real-time audio streams to and from the end-user. It delivers a clean, raw audio stream to your backend via a WebSocket, allowing your orchestration service to focus purely on the AI logic.