
The speed of light is the ultimate speed limit. For a voice AI, the speed of sound, or more accurately, the speed of data transfer is the ultimate barrier to a truly natural conversation. You can have the most brilliant AI in the world, but if its response takes two seconds to reach the user, the conversation feels stilted, robotic, and frustrating.
The solution is not to make the AI think faster, but to shorten the distance its thoughts have to travel. The solution is to move the AI to the edge. This is the core principle behind building edge-native voice agents.
Traditional, fully cloud-based voice AI has a fundamental problem: the round trip. A user’s voice has to travel from their phone, across the internet to a distant data center where the AI lives, and the AI’s response has to make the entire journey back. This journey takes time, measured in milliseconds, and every millisecond of latency is an enemy of natural conversation.
By leveraging a modern architecture with components like FreJun AI’s AgentKit, Teler, and our Realtime API, developers can now build sophisticated edge-native voice agents that slash this latency, creating conversations that are not just intelligent, but truly instantaneous.
Table of contents
What is an Edge-Native Voice Agent?
To understand “edge-native,” we must first understand “the edge.” In the world of cloud computing, “the edge” refers to a computing location that is physically closer to the end-user or the source of the data. Instead of a massive, centralized data center in one part of the country, an edge network consists of many smaller, distributed points of presence around the world.
An edge-native voice agent is a voice AI that is specifically designed to run its most time-sensitive processes at these edge locations. T
his is a profound architectural shift. Instead of all the “thinking” happening in a central “brain,” the most critical, real-time parts of the conversation like understanding the user’s immediate utterance and generating a quick response, happen at a location that is geographically much closer to the user. This drastically reduces the physical distance the data has to travel, which is the key to minimizing latency.
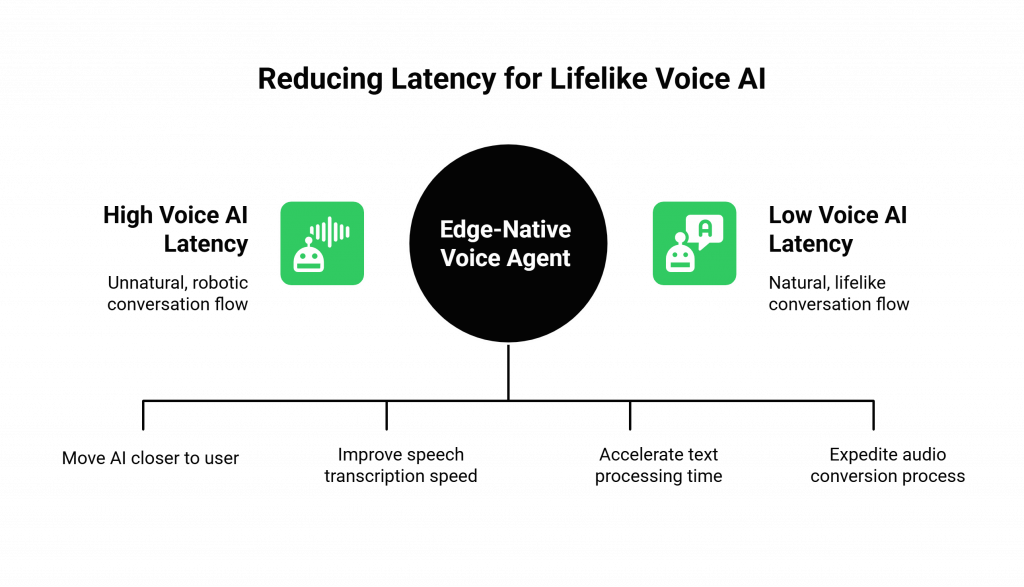
Why is Low Latency the Holy Grail for Voice AI?
In a normal human conversation, the time between one person finishing a sentence and the other person starting to respond is typically just a few hundred milliseconds. If this gap becomes too long, the conversation feels unnatural and awkward. For a voice AI, this gap is called “latency,” and it is the single biggest factor that determines whether an agent feels lifelike or robotic.
The Anatomy of Latency
The total latency in a voice AI interaction is the sum of several distinct delays:
- Network Latency: The time it takes for data packets to travel from the user’s device to the server and back. This is largely determined by physical distance.
- STT Latency: The time it takes for the Speech-to-Text engine to transcribe the user’s voice into text.
- LLM Latency: The time it takes for the Large Language Model to process the text and generate a response. This is often the biggest component.
- TTS Latency: The time it takes for the Text-to-Speech engine to convert the response text back into audio.
While we are constantly working to make the AI models themselves faster, the single biggest variable we can control is network latency. By moving the AI closer to the user, we can make this part of the equation as small as possible. This is the core mission of an edge-native voice agent.
Also Read: Automating Tour Bookings with Voice AI
The FreJun AI Architecture: Building Blocks for the Edge
To build these sophisticated edge agents, you need an architecture that is designed from the ground up to be flexible, decoupled, and distributed. This is the philosophy behind FreJun AI’s platform. Our system is not a single, monolithic black box; it is a set of powerful, interconnected components that developers can use to construct their ideal voice workflow.
Here are the key components and how they enable the creation of edge-native voice agents:
| Component | Role in the Architecture | Function for Edge-Native Agents |
| Teler | The core voice infrastructure engine. | Handles the initial connection from the telephone network at the nearest edge location, instantly minimizing the first leg of network latency. |
| MCP Server | The Media Control Plane; the “nervous system.” | Sits at the edge and orchestrates the real-time flow of audio between Teler and your AgentKit, acting as the high-speed local traffic controller. |
| AgentKit | The logical “brain” of your AI. | This is where the magic happens. You can deploy a lightweight version of your AgentKit directly on an edge server to handle the most time-sensitive parts of the conversation. |
| Realtime API | The developer’s toolkit for orchestrating the conversation. | Gives you the granular, real-time control needed to manage the state and flow of a conversation happening at the edge. |
How to Build an Edge-Native Voice Agent: A Step-by-Step Workflow
Using these components, a developer can construct a sophisticated hybrid architecture. The goal is to perform the most latency-sensitive tasks at the edge, while potentially using the central cloud for more complex, less time-sensitive “heavy thinking.”
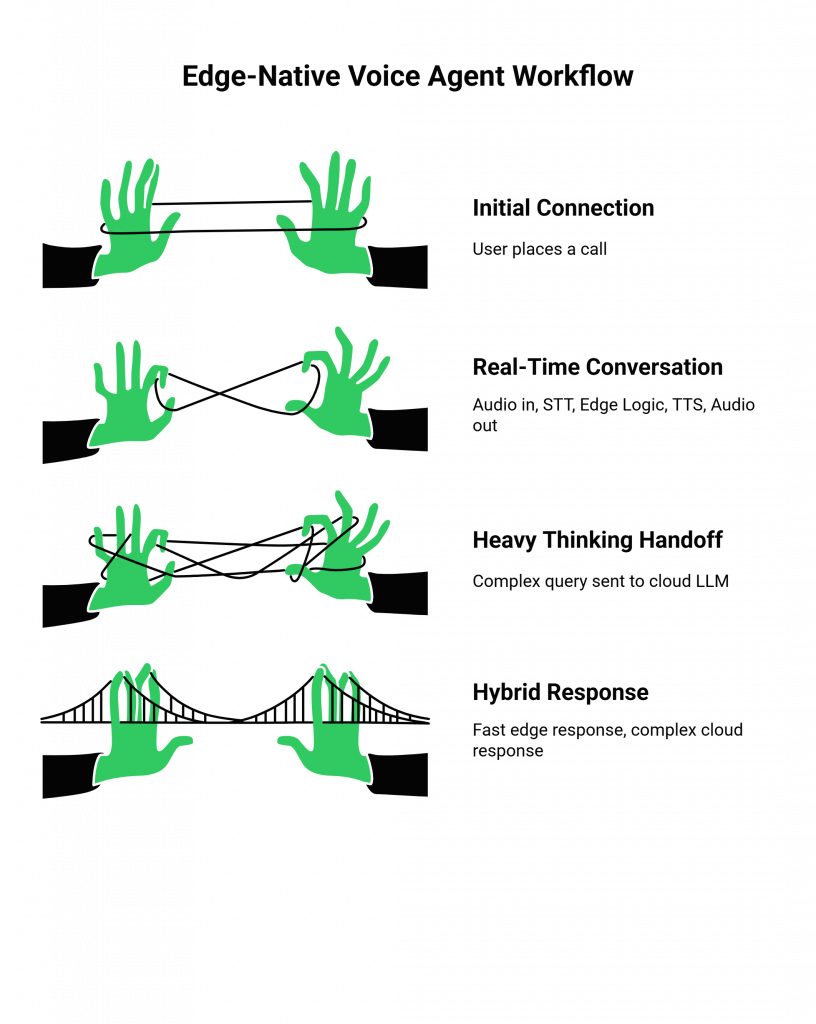
Here is a simplified workflow for a call handled by an edge-native voice agent:
Step 1: The Initial Connection (Handled by Teler at the Edge)
A user places a call. FreJun’s Teler engine, deployed at one of our many global edge locations, picks up the call. The system automatically selects the Teler instance that is geographically closest to the caller, immediately shortening the initial communication path.
Also Read: AI Voicebot for Flight Change Requests
Step 2: The Real-Time Conversation Loop (Managed by the MCP Server and Edge AgentKit)
This is where the core of the real-time interaction happens, orchestrated by our Realtime API.
- Audio In: Teler streams the raw audio from the caller to the local MCP Server at the edge.
- Edge STT: The MCP Server forwards this audio to a lightweight, fast STT model running as part of your AgentKit on the same edge server. The transcription happens locally, with minimal delay.
- Edge Logic: The transcribed text is then passed to a local, “lightweight” part of your AgentKit’s LLM. This edge model is not designed to write a novel; it is designed to handle the most common, quick-turnaround parts of the conversation (e.g., answering a simple question, confirming a detail). It makes an instant decision.
- Edge TTS: The text response from the edge LLM is immediately passed to a local TTS engine, which converts it back to audio.
- Audio Out: The MCP Server streams this audio back through Teler to the user.
This entire loop happens at the edge, with the data traveling only a very short distance. The result is a response that is almost instantaneous.
Ready to start building conversations at the speed of thought? Sign up for FreJun AI and get access to our Realtime API to explore the power of the edge.
Step 3: The “Heavy Thinking” Handoff (From the Edge to the Cloud)
What if the user asks a complex question that the lightweight edge model cannot handle? This is where the intelligence of the Realtime API comes in.
- The edge AgentKit can recognize that it needs more “brainpower.”
- It can then use the Realtime API to seamlessly pass the conversational context and the complex query to a larger, more powerful LLM running in a central cloud data center.
- While the central LLM is “thinking,” the edge AgentKit can even play a “thinking” prompt to the user (e.g., “That’s a great question, let me check on that for you.”) to manage the conversation.
- Once the central LLM generates its response, it sends it back to the edge AgentKit, which then delivers it to the user.
This hybrid model gives you the best of both worlds: the lightning-fast responsiveness of an edge-native voice agent for most of the conversation, combined with the deep intelligence of a centralized cloud brain for the most complex tasks. The potential of this architecture is immense.
According to Gartner, by 2025, more than 50% of enterprise-managed data will be created and processed outside the data center or cloud, a clear indicator of the shift toward edge computing.
Also Read: How Teler Improves AgentKit’s Intelligent Agents with Voice?
Conclusion
The future of voice AI lies not in a single, all-powerful brain in the cloud, but in a distributed, intelligent network that extends all the way to the edge. The pursuit of truly natural, human-like conversation is a battle against latency, and the only way to win is to shorten the distance.
By providing a flexible, decoupled architecture with components like Teler, MCP Servers, and a powerful Realtime API, FreJun AI gives developers the essential building blocks to create the next generation of edge-native voice agents.
This is more than just an architectural pattern; it is a fundamental step toward a world where our conversations with AI are not just intelligent, but truly instantaneous.
Want to dive deeper into our Realtime API and discuss how to design a custom edge architecture for your use case? Schedule a demo for FreJun Teler.
Also Read: Call Log: Everything You Need to Know About Call Records
Frequently Asked Questions (FAQs)
It is a voice AI that is architecturally designed to run its most time-sensitive processing tasks (like STT and quick LLM responses) at a computing location (“the edge”) that is physically closer to the end-user. This minimizes network latency and makes the conversation feel more instantaneous.
The primary benefit is a dramatic reduction in latency. By shortening the physical distance data has to travel, you can create a much more natural, real-time conversational experience for the user.
AgentKit is the “brain” of your AI. In an edge setup, a lightweight AgentKit handles fast, simple conversation turns. A more powerful version in the central cloud manages complex tasks.
Teler is our core voice infrastructure, which has points of presence at the edge. It connects the call at the closest possible point to the user. The MCP Server is the media orchestrator that also runs at the edge, managing the high-speed flow of audio between Teler and your edge AgentKit.
The Realtime API is a powerful toolset for developers. It gives real-time control over the entire call flow. Developers can manage conversation state and orchestrate handoffs between edge-based and cloud-based AI processes.
No, and that is the strength of this architecture. You can create a hybrid model. Run latency-sensitive tasks at the edge. Hand off complex, “heavy thinking” tasks to a larger AI model in the cloud.
FreJun AI provides edge-based voice infrastructure. It lets you deploy AI models on your preferred edge provider, such as AWS Wavelength or Cloudflare Workers.
It requires a complex design, but FreJun AI’s Realtime API abstracts complexity. It give developers tools to manage the distributed architecture effectively.