
Building an AI chat with voice goes far beyond plugging in STT, NLP, and TTS services. The real challenge lies in managing low-latency, real-time voice infrastructure. FreJun solves this critical hurdle by providing a production-ready voice transport layer that connects your AI, transcription, and voice synthesis systems seamlessly.
FreJun AI lets you focus on crafting intelligent conversations while handling telephony, audio streaming, and call stability. With FreJun, developers can launch scalable, voice-enabled AI applications in days, not months.
Table of contents
- What Does It Really Take to Build AI Chat with Voice?
- The 3 Pillars of a Voice-Enabled AI Chatbot
- The Hidden Hurdle: Why Is Voice Infrastructure the Hardest Part?
- How to Build AI Chat with Voice? A Practical Guide
- DIY Voice Infrastructure vs. FreJun’s Transport Layer: A Comparison
- Best Practices for Deploying Production-Grade Voice AI
- Final Thoughts: Focus on AI, Not Infrastructure
- Frequently Asked Questions (FAQ)
What Does It Really Take to Build AI Chat with Voice?
You have a powerful, text-based AI or Large Language Model (LLM) that can answer questions, book appointments, and solve customer problems with remarkable accuracy. Now, you want to give it a voice. The goal is to transform your chatbot into a conversational agent that can interact seamlessly over the phone, creating a more natural and accessible user experience. The challenge, however, is far more complex than simply connecting a microphone and a speaker.
Many developers dive in, focusing on a stack of APIs for speech-to-text (STT), natural language processing (NLP), and text-to-speech (TTS). They meticulously select models like OpenAI’s Whisper for transcription and ElevenLabs for voice generation, assuming that stitching these services together is the complete solution. But they soon encounter the real bottleneck: the complex, unforgiving world of real-time voice infrastructure.
The truth is that managing telephony, ensuring low-latency audio streaming, and maintaining a stable connection during a live conversation is a monumental task. Awkward delays, dropped words, and choppy audio can destroy the user experience, making even the most intelligent AI feel clunky and unprofessional. This is where the project often stalls not because the AI isn’t smart enough, but because the plumbing is broken.
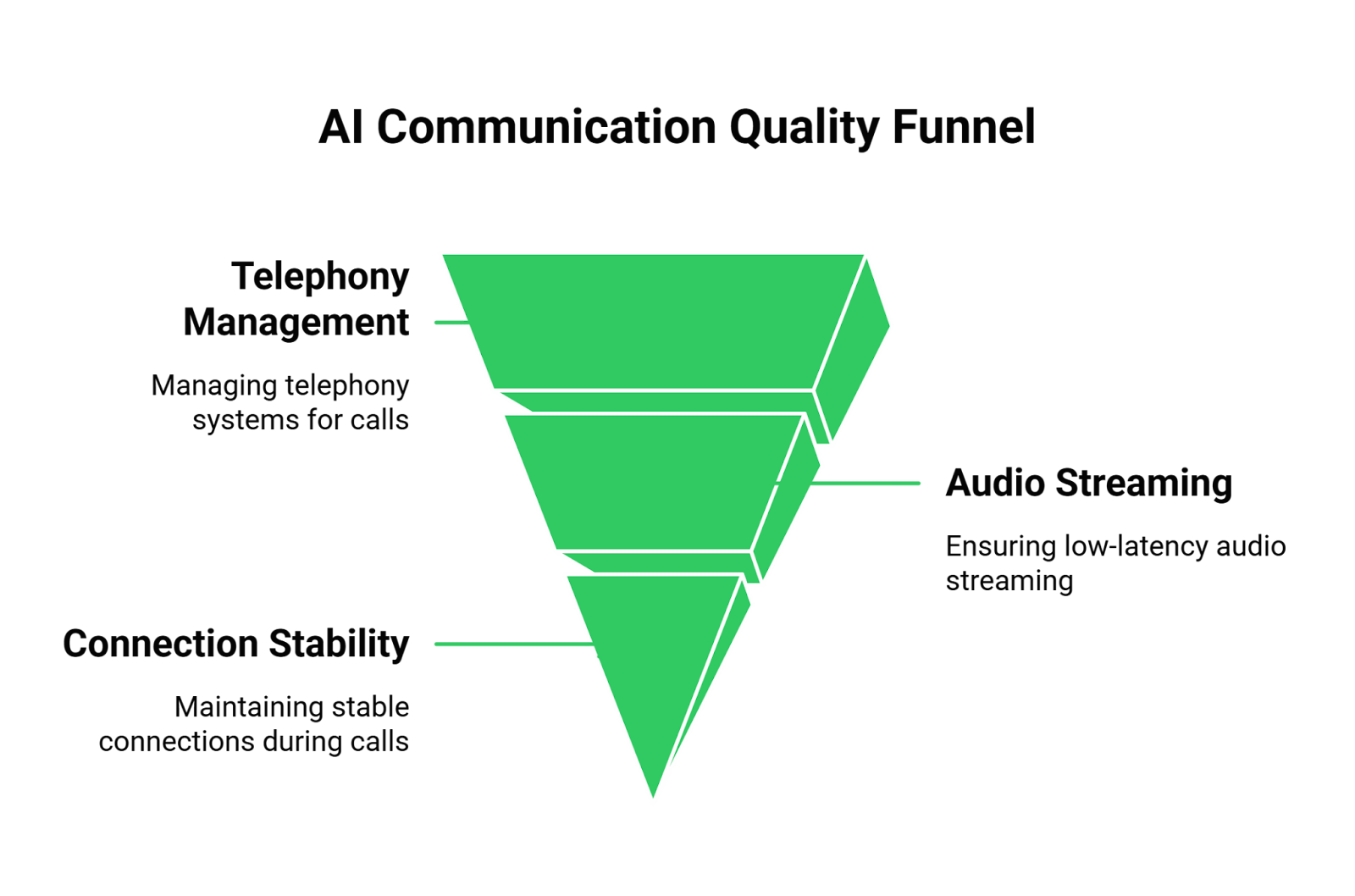
This is the problem FreJun AI was built to solve. We handle the complex voice infrastructure so you can focus on what you do best: building your AI. Our platform acts as a high-speed, reliable transport layer designed for speed and clarity, turning your text-based AI into a powerful voice agent without forcing you to become a telecom expert.
The 3 Pillars of a Voice-Enabled AI Chatbot
Before tackling the infrastructure, it’s essential to understand the core technological components that enable an AI chat with voice. These three pillars work in concert to create a fluid conversational loop.
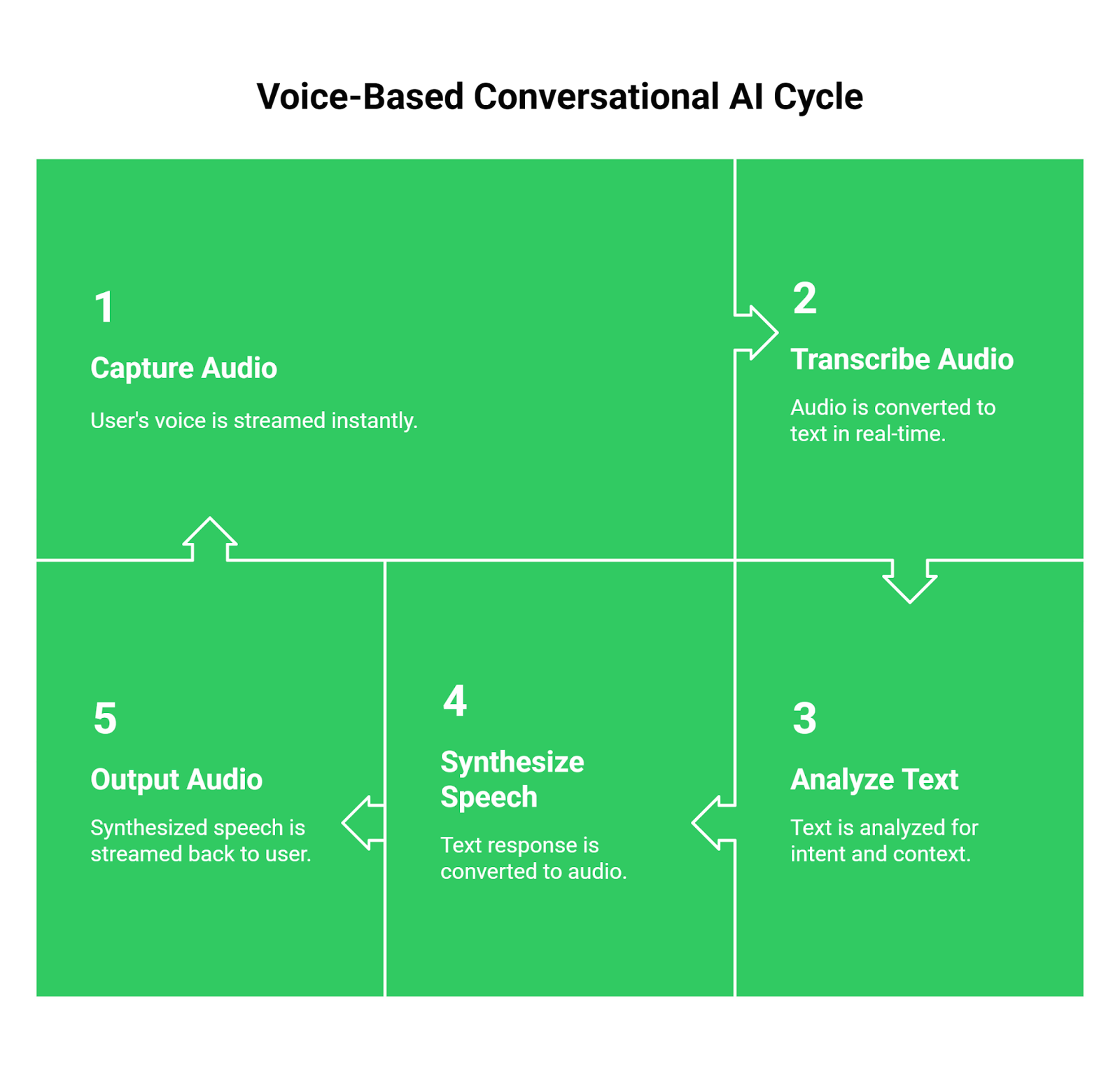
Speech-to-Text (STT) or Speech Recognition
This is the “ears” of your AI. An STT engine captures the user’s spoken words from a live audio stream and transcribes them into machine-readable text. Modern STT services, such as Google Cloud Speech-to-Text or OpenAI’s Whisper, use deep learning models trained on vast datasets to accurately interpret various accents, dialects, and speaking styles. The quality of your STT directly impacts the AI’s ability to understand the user’s intent correctly.
Natural Language Processing (NLP) Engine
This is the “brain.” Once the user’s speech is converted to text, it’s sent to an NLP engine or an LLM like OpenAI’s GPT-4. This component is responsible for understanding the context, discerning the user’s intent, and generating a coherent and relevant response. The sophistication of your NLP model determines the quality of the conversation whether it can handle complex queries, remember previous parts of the dialogue, and provide truly helpful answers.
Text-to-Speech (TTS) Synthesis
This is the “voice” of your AI. The text response generated by the NLP engine is sent to a TTS service, which converts it back into spoken audio. Advanced TTS engines like those from Google or ElevenLabs use sophisticated algorithms to create natural-sounding speech, complete with realistic intonation, pauses, and emotional emphasis. This final step is crucial for creating an engaging and human-like interaction.
While you bring your own STT, NLP, and TTS services, FreJun provides the critical infrastructure that allows these components to communicate in real-time over a phone call.
The Hidden Hurdle: Why Is Voice Infrastructure the Hardest Part?
Connecting APIs in a development environment is one thing. Deploying a scalable, real-time voice agent that can handle live phone calls is another. The real challenge is not finding the right AI models; it is managing the underlying voice transport layer. Here’s what that involves:
- Real-Time Media Streaming: Capturing raw audio from an inbound or outbound phone call and streaming it with minimal delay to your STT service.
- Low-Latency Transport: Reliably piping the STT’s text output to your NLP engine, then the NLP’s text response to your TTS service, and finally streaming the TTS audio response back to the user on the call.
- Maintaining Dialogue State: Ensuring the connection remains stable throughout the conversation so your application can manage the conversational context without interruption.
- Eliminating Awkward Pauses: The entire stack must be optimized for speed. A few hundred milliseconds of delay at each step can add up, creating unnatural pauses that break the conversational flow and signal to the user they are talking to a slow machine.
This is the complex, mission-critical infrastructure that FreJun AI handles for you. Instead of spending months building and debugging your own telephony stack, you can leverage our production-grade platform to get your AI talking in days.
How to Build AI Chat with Voice? A Practical Guide
With a robust voice transport layer like FreJun, the process of building a sophisticated AI chat with voice becomes dramatically simpler. Here is a step-by-step guide to bringing your voice agent to life.
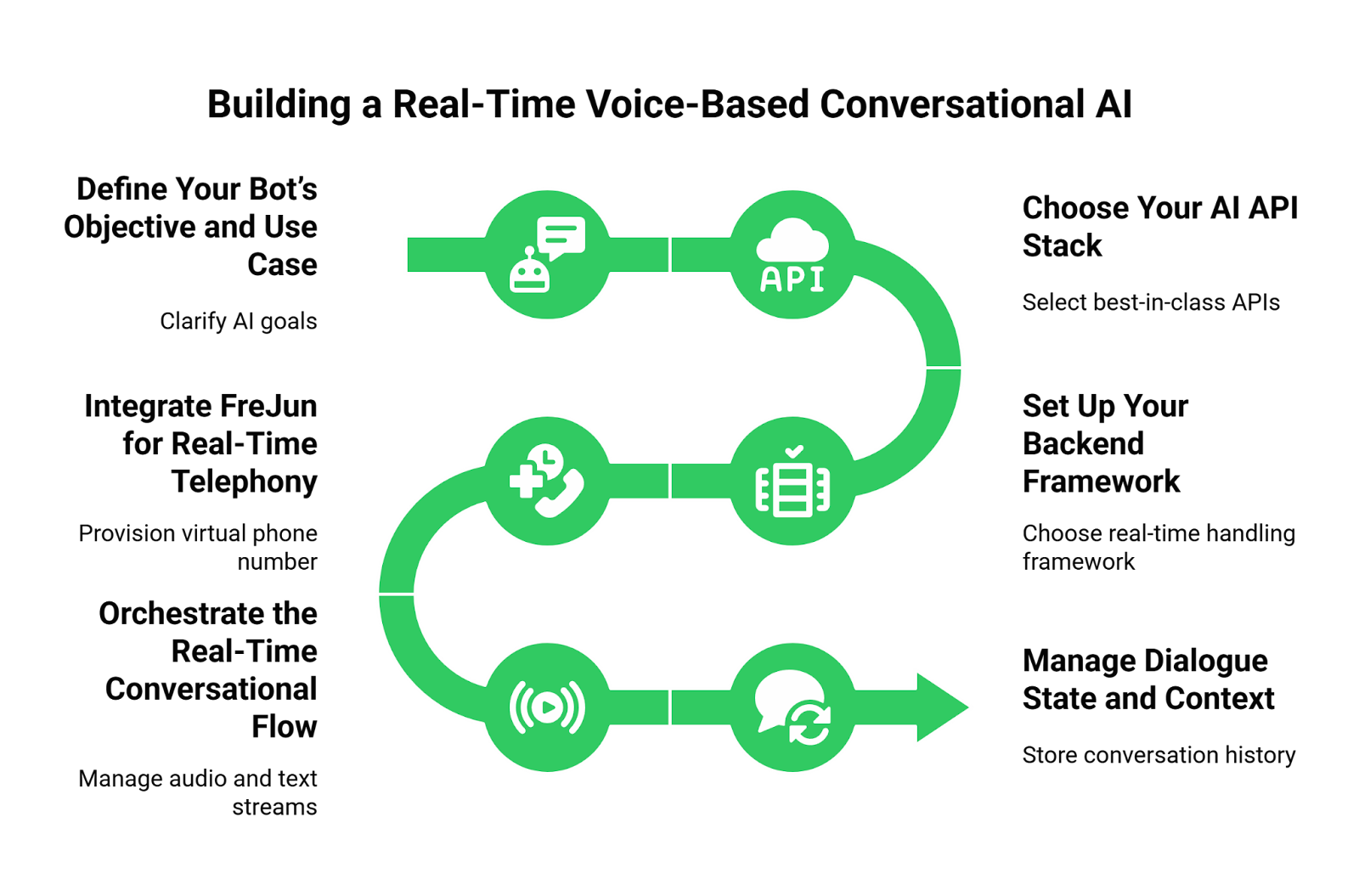
Step 1: Define the Purpose and Scope
First, clarify what you want your voice agent to accomplish. Is it a 24/7 customer support agent, an intelligent IVR system, an AI receptionist, or an outbound agent for lead qualification? Defining the use case will guide your choice of AI models and the conversational flows you need to design.
Step 2: Choose Your AI and Voice Synthesis Stack
Select the services that will act as your AI’s brain and voice. FreJun is model-agnostic, giving you complete freedom.
- Speech-to-Text (STT): Choose a service like Google Speech-to-Text, Azure Speech Services, or OpenAI Whisper.
- Natural Language Processing (NLP): Select an LLM like OpenAI GPT-4, Google Cloud Natural Language, or your own custom model.
- Text-to-Speech (TTS): Pick a voice synthesis engine like ElevenLabs, Google Cloud TTS, or PlayHT for natural-sounding audio output.
Step 3: Set Up Your Backend Application
Establish your programming environment using a language like Python or Node.js. Your application will be responsible for managing the conversational logic. With FreJun, you don’t interact with complex telephony protocols. You simply receive an audio stream and send an audio stream back.
Step 4: Stream Voice Input with FreJun
This is where FreJun AI simplifies everything. Our API captures real-time, low-latency audio from any inbound or outbound phone call. You simply direct this raw audio stream to your chosen STT service for transcription. FreJun ensures every word is captured clearly and without delay, providing a clean input for your AI.
Step 5: Process with Your AI and Generate a Response
Once your STT service transcribes the user’s speech, your backend application takes over.
- Pass the transcribed text to your NLP engine (e.g., GPT-4) via an API call.
- Your application maintains full control over the dialogue state, allowing it to track context and manage the conversation.
- Receive the text response generated by your AI.
Step 6: Generate and Stream Voice Response with FreJun
Pipe the text response from your AI to your chosen TTS service. The TTS engine will generate an audio file or stream. You then pipe this response audio directly to the FreJun API, which streams it back over the call with ultra-low latency. This completes the conversational loop, delivering a fluid and natural-sounding response to the user.
DIY Voice Infrastructure vs. FreJun’s Transport Layer: A Comparison
Choosing the right approach for your voice infrastructure can be the difference between launching in weeks versus months (or not at all). Here is how a do-it-yourself approach compares to leveraging FreJun’s specialized platform.
| Feature | DIY Voice Infrastructure | FreJun’s Voice Transport Layer |
| Setup Time & Complexity | High. Requires deep telecom knowledge, managing SIP trunks, and complex server configurations. | Low. A few API calls to integrate. Launch in days, not months. |
| Latency Management | Difficult. You are responsible for optimizing the entire stack to minimize delays. | Core focus. Entire stack is engineered for low-latency, real-time conversations. |
| Scalability & Reliability | Costly and complex. Requires building geographically distributed, redundant infrastructure. | Built-in. Runs on resilient, enterprise-grade infrastructure designed for high availability. |
| Developer Focus | Divided between AI logic and complex voice plumbing (telephony, streaming). | 100% on AI logic. FreJun handles the entire voice infrastructure layer. |
| Control over AI | Full control, but requires building the surrounding infrastructure from scratch. | Full control. Model-agnostic API lets you bring your own AI, STT, and TTS. |
| Support | None. You are on your own to troubleshoot issues with carriers and streaming protocols. | Dedicated. Expert integration support from pre-launch planning to post-launch optimization. |
Best Practices for Deploying Production-Grade Voice AI
Building a successful AI chat with voice goes beyond the initial setup. Follow these best practices to ensure your voice agent is effective, reliable, and secure.

- Test with Diverse Users: Before going live, test your system with a wide range of users to account for different accents, speaking speeds, and background noises. This helps refine both your STT model’s accuracy and your NLP model’s understanding of real-world queries.
- Monitor and Iterate: Deployment is just the beginning. Continuously monitor conversations (with user consent) and use the feedback to fine-tune your AI. Update your language model to handle new questions and improve the expressiveness of your TTS engine.
- Prioritize Low Latency: A natural conversation depends on speed. By using an optimized transport layer like FreJun, you can minimize the awkward pauses between a user speaking and the AI responding, which is critical for user engagement.
- Ensure Data Security and Privacy: Voice data is sensitive. Ensure your entire pipeline, from call capture to transcription and storage, is secure. FreJun provides security by design, ensuring the integrity and confidentiality of your data as it moves through our platform.
Final Thoughts: Focus on AI, Not Infrastructure
The goal of creating an AI chat with voice is to build smarter, more natural, and more efficient conversations. However, the path to achieving this is often blocked by the immense complexity of real-time voice infrastructure. Businesses that attempt to build this from the ground up find themselves mired in telephony protocols and latency issues, distracting them from their primary objective: creating a brilliant AI.
FreJun fundamentally changes this equation. By abstracting away the voice layer, we empower you to channel all your resources into what truly differentiates your application, the intelligence of your AI. Our robust API, developer-first SDKs, and enterprise-grade infrastructure provide the foundation you need to move from concept to a production-grade voice agent at an accelerated pace.
Don’t let the plumbing get in the way of your vision. Let FreJun AI handle the complex voice transport, and get your AI talking.
Also Read: How to Set Up WhatsApp Business for Multi-Agent Support Teams?
Frequently Asked Questions (FAQ)
No. FreJun is a voice transport layer. Our platform is model-agnostic, which means you bring your own AI/LLM, STT, and TTS services. We provide the critical infrastructure that connects a live phone call to your chosen services in real-time, handling all the complex telephony and low-latency media streaming.
FreJun acts as the bridge. Furthermore, our API captures live audio from a phone call and streams it to you. Meanwhile, you send this audio to your STT service (like Whisper) for transcription. Subsequently, you send the resulting text to your AI (like GPT-4) for a response. Finally, you send that text response to a TTS service, and stream the resulting audio back through our API to the user on the call. Consequently, we manage the call and the audio transport while you manage the AI logic.
The primary benefit is speed to market and reliability. Furthermore, building and maintaining a production-grade, low-latency voice infrastructure becomes extremely difficult, costly, and time-consuming. Therefore, FreJun provides this as a service, consequently allowing you to bypass months of development and focus entirely on building and refining your AI’s conversational abilities.
Yes. Our platform is designed to handle both inbound calls (e.g., for customer support or an AI receptionist) and outbound calls (e.g., for appointment reminders or lead qualification campaigns).
Our entire platform is engineered for low latency. We have optimized every component from call capture to media streaming to minimize the delay between when a user speaks, your AI processes the request, and the voice response is played back. This eliminates the awkward pauses that make typical voicebots feel unnatural.