
The launch of Google’s latest model has ushered in a new era for conversational AI. The power and flexibility of ai voice agents using Gemini 2.0 Flash are setting a new standard for what’s possible in automated, human-like interaction. With its native ability to process audio, a massive context window, and advanced function calling, Gemini 2.0 Flash provides developers with an unprecedented toolkit to build incredibly intelligent and context-aware agents.
Table of contents
- What Makes Gemini 2.0 Flash a Game-Changer for Voice?
- The Hidden Challenge: The Voice Infrastructure Gap
- FreJun: The Missing Infrastructure Layer for Your Gemini Agent
- DIY Telephony vs. A FreJun-Powered Agent: A Comparison
- Step-by-Step Guide: How to Build a Complete AI Voice Agent
- Best Practices for a Flawless Implementation
- Final Thoughts
- Frequently Asked Questions (FAQ)
The path to creating this “brain” has never been clearer. However, a critical and often underestimated challenge remains that prevents these brilliant creations from reaching their full potential. An AI brain, no matter how powerful, is useless if it has no way to connect to the real world.
This guide will walk you through not only how to build the AI core of your voice agent but also how to solve the crucial infrastructure problem that separates a promising prototype from a scalable, enterprise-ready solution.
What Makes Gemini 2.0 Flash a Game-Changer for Voice?
Building ai voice agents using Gemini 2.0 Flash offers a distinct advantage over previous models. It isn’t just an incremental improvement; it’s a fundamental shift in capability. Key features include:

- Native Audio Processing: Unlike older models that require a separate Speech-to-Text (STT) step, Gemini 2.0 Flash can directly process raw audio input. This allows it to understand not just the words being said but also the tone, mood, and even background sounds, leading to a much richer and more contextual understanding of the user.
- Enhanced Multimodal Capabilities: The model can simultaneously analyze text, images, audio, and video. For a voice agent, this means it could potentially analyze a user’s speech while also processing a document they’ve uploaded, creating a deeply integrated and powerful experience.
- Expanded Function Calling: This is the key to making an AI agent actionable. Gemini 2.0 Flash has robust function calling features that allow it to directly integrate with external APIs. This enables the agent to perform real-world tasks like controlling a smart device, querying a database for live information, or booking an appointment in a calendar.
The Hidden Challenge: The Voice Infrastructure Gap
You’ve designed a brilliant agent. It’s powered by Gemini 2.0 Flash, it’s connected to your business systems via function calling, and it’s ready to revolutionize your customer service. Now, you need it to answer a phone call. This is where most projects hit a formidable wall.
The entire ecosystem of AI tools, including Google’s Vertex AI and AI Studio, is designed to provide the “brain” for your agent. They do not provide the underlying infrastructure needed to connect that brain to the Public Switched Telephone Network (PSTN). To make your agent answer a phone call, you would have to build a highly specialized and complex voice infrastructure stack from the ground up. This involves solving a host of non-trivial engineering problems:
- Telephony Protocols: Managing SIP (Session Initiation Protocol) trunks and carrier relationships.
- Real-Time Media Servers: Building and maintaining dedicated servers to handle raw audio streams from thousands of concurrent calls.
- Call Control and State Management: Architecting a system to manage the entire lifecycle of every call, from ringing and connecting to holding and terminating.
- Network Resilience: Engineering solutions to mitigate the jitter, packet loss, and latency inherent in voice networks that can destroy the quality of a real-time conversation.
This is the hidden challenge. Your team, expert in AI and application development, is suddenly forced to become telecom engineers. The project stalls, and the brilliant agent you built remains trapped, unable to be reached by the millions of customers who rely on the telephone.
FreJun: The Missing Infrastructure Layer for Your Gemini Agent
This is the exact problem FreJun was built to solve. We are not another AI platform. We are the specialized voice infrastructure layer that connects the powerful ai voice agents using Gemini 2.0 Flash to the global telephone network.
FreJun AI provide a simple, developer-first API that handles all the complexities of telephony, so you can focus on building the best AI possible.
- We are AI-Agnostic: You bring your own “brain.” FreJun integrates seamlessly with any backend, allowing you to connect directly to the Gemini 2.0 Flash API.
- We Manage the Voice Transport: We handle the phone numbers, the SIP trunks, the media servers, and the low-latency audio streaming.
- We Guarantee Reliability and Scale: Our globally distributed, enterprise-grade infrastructure ensures your phone line is always online and ready to handle high call volumes.
FreJun provides the robust “body” that allows your AI “brain” to have a real, meaningful conversation with the outside world.
DIY Telephony vs. A FreJun-Powered Agent: A Comparison
| Feature | The DIY Telephony Approach | The FreJun + Gemini 2.0 Flash Approach |
| Infrastructure | You build, manage, and scale your own voice servers, SIP trunks, and network protocols. | Fully managed. FreJun handles all telephony, streaming, and server infrastructure. |
| Scalability | Extremely difficult and costly to build a globally distributed, high-concurrency system. | Built-in. Our platform elastically scales to handle any number of concurrent calls on demand. |
| Development Time | Months, or even years, to build a stable, production-ready system. | Weeks. Launch your globally scalable voice agent in a fraction of the time. |
| Developer Focus | Divided 50/50 between building the AI and wrestling with low-level network engineering. | 100% focused on building the best possible conversational experience with Gemini 2.0 Flash. |
| Maintenance & Cost | Massive capital expenditure and ongoing operational costs for servers, bandwidth, and a specialized DevOps team. | Predictable, usage-based pricing with no upfront capital expenditure and zero infrastructure maintenance. |
Step-by-Step Guide: How to Build a Complete AI Voice Agent
This guide outlines the modern, scalable architecture for building ai voice agents using Gemini 2.0 Flash that can handle real phone calls.
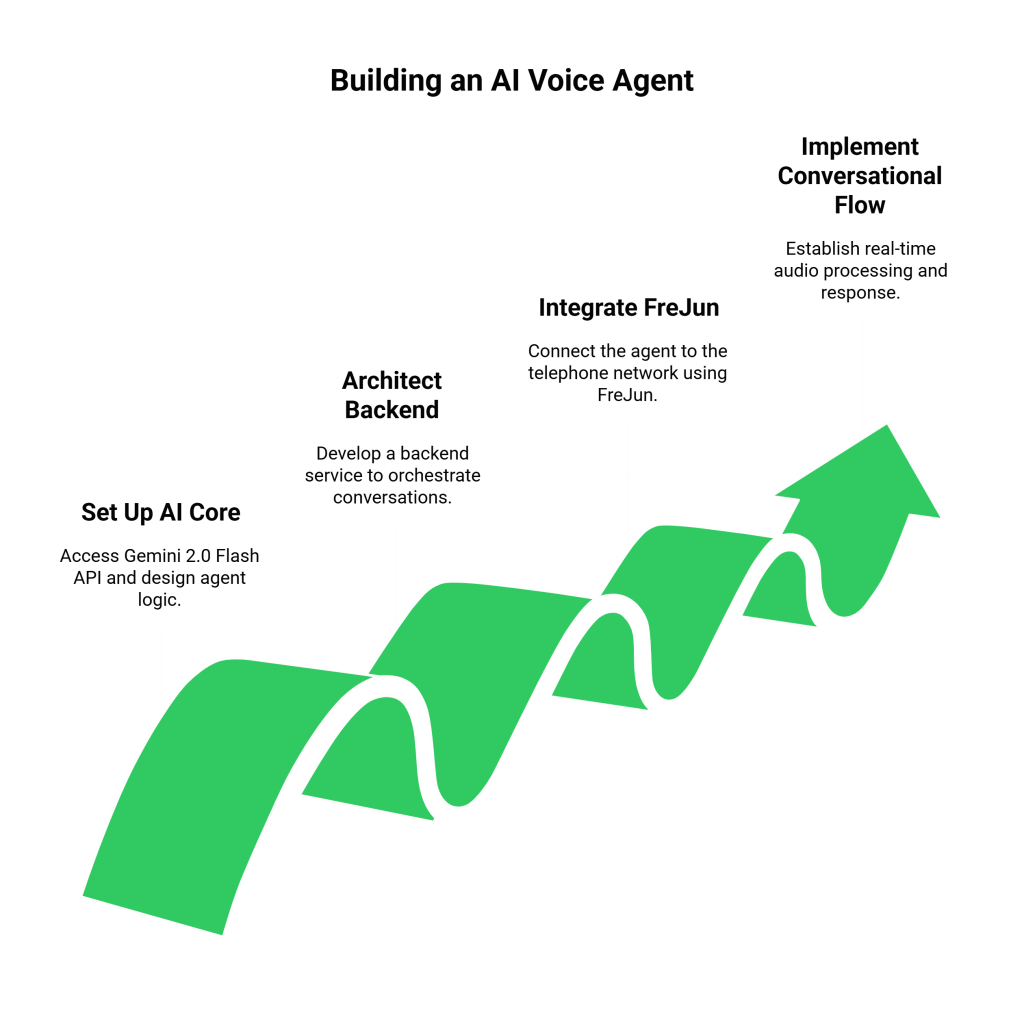
Step 1: Set Up Your AI Core with Gemini 2.0 Flash
First, get access to the Gemini 2.0 Flash API through Google AI Studio or Vertex AI and obtain your API credentials. Design the core logic of your agent, including its personality, instructions, and the tools it can use via function calling.
Step 2: Architect Your Backend Application
Using your preferred framework (like Python with FastAPI or Node.js with Express), build a backend service that will orchestrate the conversation. This service will be the central hub that communicates with both FreJun and the Gemini API.
Step 3: Integrate FreJun for the Voice Channel
This is the critical step that connects your agent to the telephone network.
- Sign up for FreJun and instantly provision a virtual phone number.
- Use FreJun’s server-side SDK in your backend to handle incoming WebSocket connections from our platform.
- In the FreJun dashboard, configure your new number’s webhook to point to your backend’s API endpoint.
Step 4: Implement the Real-Time Conversational Flow
When a customer dials your FreJun number, your backend will spring into action:
- FreJun establishes a WebSocket connection and streams the live audio to your backend.
- Your backend receives the raw audio stream and forwards it directly to the Gemini 2.0 Flash API.
- Gemini processes the audio natively, understands the intent, and executes any necessary function calls by communicating with your backend.
- Gemini returns a text response to your backend.
- Your backend sends this text response to your chosen Text-to-Speech (TTS) service to be synthesized into audio.
- Your backend streams the synthesized audio back to the FreJun API, which plays it to the caller with ultra-low latency.
With this architecture, you have a complete, enterprise-ready ai voice agents using Gemini 2.0 Flash.
Best Practices for a Flawless Implementation
- Leverage Grounding and Multimodality: Utilize Gemini’s ability to access up-to-date information and process multiple data types to create richer, more accurate conversations.
- Design for Graceful Failure: No AI is perfect. Program clear fallback paths in your conversational logic and design a seamless handoff to a human agent when the bot gets stuck. FreJun’s API can facilitate this live call transfer.
- Ensure Security and Privacy: Manage all API keys and user data securely. Encrypt all communication and ensure your data handling practices comply with all relevant privacy regulations.
- Continuously Monitor and Iterate: Use call analytics and conversation logs to understand how users are interacting with your agent. This data is invaluable for refining its instructions, improving its tool usage, and enhancing the overall user experience.
Final Thoughts
The power of ai voice agents using Gemini 2.0 Flash is undeniable. It represents a paradigm shift in our ability to create intelligent, helpful, and truly conversational AI. But that intelligence is only as valuable as its accessibility. A brilliant AI that is trapped in a digital sandbox cannot solve real-world business problems at scale.
The strategic path forward is to combine the best AI brain with the best voice infrastructure. By leveraging a specialized platform like FreJun, you can offload the immense burden of telecom engineering and focus your valuable resources on what truly differentiates your business: the intelligence of your AI and the quality of the customer experience you deliver.
Build an agent that’s as smart as Gemini, and let us give it a voice that can reach the world.
Further Reading – AI for Sales Call Analysis: Boost Performance & Insights
Frequently Asked Questions (FAQ)
No, it integrates with them. You use Google’s platforms to access and manage the Gemini 2.0 Flash model (the “brain”). FreJun provides the separate, essential voice infrastructure (the “body”) that connects that brain to the telephone network.
Yes. FreJun is designed to stream the raw, unprocessed audio from the phone call directly to your backend. You can then forward this raw audio to the Gemini 2.0 Flash API, allowing you to take full advantage of its native audio understanding capabilities.
Function calling is managed by your backend. When Gemini determines that it needs to call a function, it will send a request to your backend. Your backend code will then execute the function (e.g., make a database query), send the result back to Gemini, and then Gemini will use that result to formulate its final response.
Absolutely not. We abstract away all the complexity of telephony. If you can work with a standard backend API and a WebSocket, you have all the skills needed to build powerful ai voice agents using Gemini 2.0 Flash.
This architecture is highly scalable. FreJun’s infrastructure is built to handle massive call concurrency. By designing your backend to be stateless, you can use standard cloud auto-scaling to handle any amount of traffic, ensuring your service is both resilient and cost-effective.