
Open-source breakthroughs like Meta’s Llama 2 are reshaping customer support AI, allowing businesses of any size to create tailored, context-aware agents. Yet, deploying these models over the phone introduces tough challenges, real-time streaming, telephony integration, and ultra-low latency. FreJun AI solves this by providing the voice infrastructure that links your AI stack to the global telephone network.
Table of contents
- The Open-Source Revolution in Customer Support AI
- What is Llama 2, and Why is it Ideal for Voice Bots?
- The Unseen Challenge: Bridging Your Bot to the Telephone Network
- FreJun: The Voice Infrastructure Layer for Your Llama 2 Bot
- How to Build a Voice Bot Using Llama 2? An Architectural Guide
- DIY Voice Infrastructure vs. FreJun: Where to Focus Your Resources
- Best Practices for a High-Performing Llama 2 Voice Bot
- From Model to Mission-Critical Asset
- Frequently Asked Questions (FAQs)
In this guide, we explore how to combine Llama 2’s conversational intelligence with FreJun’s reliable transport layer to deliver responsive, production-ready voice support at scale.
The Open-Source Revolution in Customer Support AI
For years, building a truly intelligent, conversational AI for customer support was the exclusive domain of large corporations with massive budgets. Proprietary models and the complex infrastructure required to run them created a high barrier to entry. Today, the landscape has fundamentally changed. The release of powerful, open-source models like Meta’s Llama 2 has democratized access to state-of-the-art AI, empowering businesses of all sizes to build their own custom support solutions.
This new accessibility allows companies to create highly tailored, domain-specific support agents that understand their products and customers intimately. However, as many development teams are discovering, having a powerful AI “brain” is only the first step. The real challenge lies in giving that brain a voice and connecting it seamlessly to the most universal and immediate channel of customer communication: the telephone.
What is Llama 2, and Why is it Ideal for Voice Bots?
Meta developed Llama 2, a family of powerful open-source large language models ranging from 7 billion to 70 billion parameters. They specifically optimized the Llama 2-Chat variants for dialogue, making them exceptionally well-suited for building conversational applications like customer support bots.

Ask ChatGPTHere’s why Llama 2 is an excellent choice for this task:
- Optimized for Dialogue: Its fine-tuning on conversational data enables it to maintain context, understand nuances, and generate natural, human-like responses.
- Open-Source Flexibility: Unlike closed, proprietary models, you can customize Llama 2, fine-tune it on your company’s data, and self-host it for maximum control and data privacy.
- Scalability: The range of model sizes allows you to choose the right balance of performance and cost. The smaller 7B model is often preferred for its lower latency and cost-efficiency, which are critical for real-time voice interactions.
- Strong Ecosystem: A robust ecosystem of tools like LangChain, Hugging Face, and vector databases has grown around Llama 2, simplifying development and enabling advanced features.
These attributes make building a voice bot using Llama 2 an attractive proposition for any business looking to automate and enhance its customer support operations.
Also Read: How to Build a Voice Bot Using Mistral Medium 3 for Customer Support?
The Unseen Challenge: Bridging Your Bot to the Telephone Network
While the tutorials for setting up a Llama 2 chatbot in a web interface are plentiful, they quietly omit the hardest part of building a true voice bot: real-time voice communication. A complete voice solution requires a complex, low-latency pipeline of multiple technologies working in perfect harmony. The typical architecture involves:
- Speech-to-Text (STT): An engine like OpenAI’s Whisper must instantly and accurately transcribe the caller’s spoken words into text.
- The LLM (Llama 2): Your Llama 2 model processes the text and generates a response.
- Text-to-Speech (TTS): An engine like ElevenLabs or Google TTS must convert the text response back into natural-sounding audio.
The real challenge is the voice transport layer, the underlying telephony infrastructure that manages the phone call itself. This involves handling SIP trunks, streaming audio bi-directionally with minimal packet loss, and engineering the entire stack to reduce latency to a few hundred milliseconds.
A delay of even one second can make a conversation feel stilted and unnatural, destroying the customer experience. Building this layer is a deep, specialized engineering problem that distracts from the core goal of creating an intelligent bot.
FreJun: The Voice Infrastructure Layer for Your Llama 2 Bot
This is precisely where FreJun steps in. FreJun is not an LLM provider. We provide the robust, developer-first voice infrastructure that handles all the complex telephony, so you can focus on building your AI. Our platform is the essential “plumbing” that connects your sophisticated voice bot using Llama 2 to the global telephone network.
With FreJun, you bring your entire AI stack. Our model-agnostic API allows you to integrate any STT, LLM, and TTS service you choose. We manage the real-time media streaming, ensuring every word from the caller is captured clearly and every response is delivered back with the lowest possible latency. Your application maintains full control over the AI logic and conversation state, while our platform guarantees a stable, clear, and scalable voice connection.
Also Read: Virtual Number Solutions for Professional Communication with WhatsApp Integration in Canada
How to Build a Voice Bot Using Llama 2? An Architectural Guide
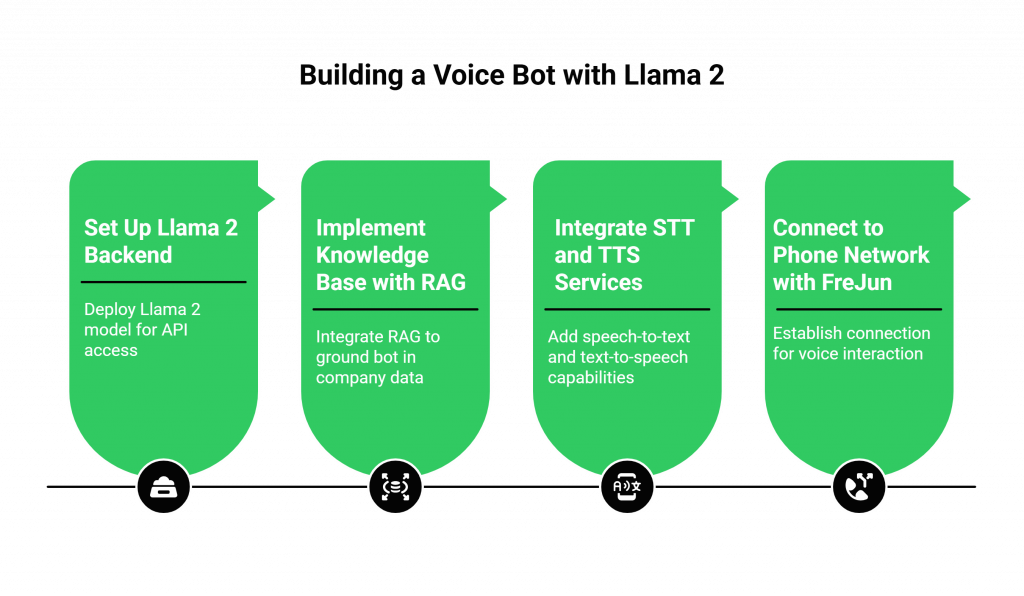
Let’s walk through the architectural steps to build a smart, context-aware customer support voice bot.
Step 1: Set Up Your Llama 2 Backend
First, you need to deploy your Llama 2 model so it can be accessed via an API.
- Choose a Model: Start with the Llama-2-7b-chat model for a good balance of performance, cost, and low latency.
- Deployment: You can deploy the model on a cloud platform like Baseten, which simplifies the process, or set it up locally using tools like llama.cpp for more control. You will need to obtain access to the model weights via Meta and Hugging Face.
- Orchestration: Use a framework like LangChain to manage your application logic. LangChain helps with prompt chaining, managing conversation history (memory), and integrating other components.
Step 2: Implement a Knowledge Base with RAG
To prevent your bot from “hallucinating” or providing incorrect information, you must ground it in your company’s actual data. This is achieved using Retrieval-Augmented Generation (RAG).
- Create a Vector Store: Load your knowledge base documents (e.g., product manuals, FAQs, policy documents) into a vector database like DeepLake. This process converts your text into numerical representations that the AI can easily search.
- Integrate Retrieval: When a user asks a question, your application first queries the vector store to find the most relevant information.
- Augment the Prompt: This retrieved information is then added to the prompt that is sent to Llama 2, ensuring its response is based on factual, up-to-date company knowledge. This is a critical step for building a trustworthy voice bot using Llama 2.
Step 3: Integrate Your STT and TTS Services
This is where you give your bot its “ears” and “mouth.”
- Speech-to-Text: Integrate a real-time STT service. OpenAI’s Whisper is a powerful and popular choice, with libraries like Whisper.js available for web-based applications.
- Text-to-Speech: Choose a low-latency TTS service with natural-sounding voices. Services like ElevenLabs are known for their quality and speed.
At this point, you have an AI backend that can receive text, think, and generate a text response. You also have the tools to convert speech-to-text and text-to-speech. Now, you need to connect it to a phone call.
Step 4: Connect to the Phone Network with FreJun
This final step is what turns your text-based application into a true voice bot.
- Initiate the Call: Using FreJun’s API, you can either place an outbound call or configure a FreJun-provided number to handle inbound customer support calls.
- Stream Audio: Once the call is connected, FreJun captures the caller’s audio in real-time and streams it to your application.
- Run the AI Pipeline: Your backend receives the audio stream and passes it to your Whisper service for transcription. The resulting text is fed into your RAG and Llama 2 workflow. Llama 2 generates a response, which is then sent to your TTS service.
- Deliver the Response: Your TTS service streams the generated audio back to the FreJun API, which plays it to the caller with minimal delay, completing the conversational loop.
Also Read: How to Build AI Voice Agents Using Grok 4?
DIY Voice Infrastructure vs. FreJun: Where to Focus Your Resources
| Feature | The DIY Infrastructure Approach | The FreJun Infrastructure Approach |
| Primary Focus | Divided between AI logic (Llama 2, RAG) and complex telephony engineering. | 100% focused on building and refining your voice bot using Llama 2 and its knowledge base. |
| Core Expertise | Requires hiring specialized VoIP/telecom engineers. | Leverages FreJun’s team of voice experts for a fully managed, enterprise-grade solution. |
| Latency | A constant, difficult engineering challenge to minimize audio delay across the entire stack. | Solved by design. Our platform is engineered from the ground up for low-latency conversational AI. |
| Time to Market | Months of development to build a stable, scalable voice layer before your bot can even take a call. | Launch in days. Integrate your AI with our API and start handling calls immediately. |
| Scalability & Reliability | Your responsibility to manage uptime, redundancy, and scaling for peak call volumes. | Handled for you. Our geographically distributed infrastructure ensures high availability and scales on demand. |
Also Read: Virtual Number Solutions for Professional Growth with WhatsApp Integration in Russia
Best Practices for a High-Performing Llama 2 Voice Bot
- Mitigate Hallucinations: Always use a RAG architecture. Relying on the base model’s knowledge alone for customer support is risky. Grounding responses in your own verified data is non-negotiable.
- Design for Graceful Failure:Implement fallback prompts for when the bot gets confused, such as “I’m sorry, I’m having trouble understanding.” Could you rephrase that?”). Always provide a clear path to escalate the call to a human agent.
- Fine-Tune for Domain Specificity: For advanced performance, consider fine-tuning your Llama 2 model using methods like QLoRA on your own customer interaction data. This can improve its understanding of your specific industry jargon and customer intents.
- Optimize the Entire Pipeline: Monitor and optimize the latency of each component. Even if your Llama 2 model is fast, a slow STT or TTS service can ruin the conversational flow.
From Model to Mission-Critical Asset
A Llama 2 model on a server is an impressive piece of technology. A fully integrated voice bot using Llama 2, grounded in your company’s knowledge and accessible 24/7 over the phone, is a mission-critical business asset. It can dramatically reduce support costs, improve customer satisfaction, and free up your human agents to handle the most complex and valuable interactions.
The path to achieving this is not by becoming a telecommunications company. It is by leveraging best-in-class, specialized solutions for each part of the problem. Use the power and flexibility of open-source AI like Llama 2 to build the intelligence. And partner with an expert in voice infrastructure like FreJun to deliver that intelligence to your customers with the clarity, speed, and reliability they expect.
Also Read: How to Build AI Voice Agents Using DeepSeek-V3?
Frequently Asked Questions (FAQs)
Llama 2 is open-source, highly customizable, and its chat–tuned variants are specifically designed for dialogue. This allows you to build a secure, self-hosted bot that understands your business’s unique context.
RAG is a technique where the AI model retrieves relevant information from a private knowledge base (like your company’s FAQs) before answering a question. This is crucial for customer support as it ensures the bot provides accurate, factual information and minimises the risk of making things up (hallucination).
The smaller 7-billion-parameter model (Llama-2-7b-chat) is generally recommended. It offers a better balance of speed and performance, resulting in lower latency, which is essential for a natural-sounding conversation.
FreJun provides the voice transport layer. We handle all the complex telephony infrastructure required to connect a live phone call to your backend AI application. Our API manages the real-time streaming of audio between the caller and your STT/TTS services, allowing you to focus on the AI logic.