
As a developer, you’ve built something remarkable. Your text-based chatbot is a work of art, a finely tuned engine of logic. It is powered by a sophisticated LLM, and deeply integrated with your business’s core systems. It can answer questions, resolve issues, and guide users with precision. But for all its intelligence, it remains trapped behind a keyboard. It works as a silent partner in a world that is increasingly finding its voice.
The next logical step is to transform this silent intelligence into a fully-fledged Chatbot Voice Assistant. The common misconception is that this is a frontend challenge, a matter of simply adding a microphone button to a user interface. The reality, however, is that the true work, the complex orchestration, and the heavy lifting all happen on the backend.
Creating a real-time voice experience is an architectural challenge. It’s about building a high-speed, resilient, and intelligent service that can act as the “central nervous system” for your AI. This guide is a backend developer’s roadmap to adding voice capabilities, moving beyond the UI to explore the server-side architecture that makes a truly conversational AI possible.
Table of contents
Why Should Voice Capabilities Be a Backend-First Concern?
While the microphone button may live on the client-side, the “soul” of your voice assistant lives on the server. Centralizing the voice processing logic in your backend is a critical architectural decision that provides a foundation for security, scalability, and flexibility.
Think of it this way: your frontend client (a web browser or mobile app) should be treated as a “dumb terminal.” It’s a simple microphone and speaker. Your backend, on the other hand, is the entire recording studio. It’s the sound engineer that cleans up the audio, the producer that directs the talent, and the mixing board that puts it all together.
This separation of concerns offers three powerful advantages:
- Centralized Logic and Control: All your AI processing, the Speech-to-Text, the core LLM logic, and the Text-to-Speech, lives in one place. This makes it dramatically easier to manage, update, and debug.
- Enhanced Security: Your API keys for your various AI models, your proprietary business logic, and your connection strings are all kept safely on your secure server, never exposed to the client-side.
- Ultimate Flexibility: The same backend voice service can power multiple frontends. You can build a voice interface for your website, a mobile app, and even a traditional phone line, and they can all talk to the same intelligent backend.
Also Read: How To Build Multimodal AI Agents With Voice?
What is the Core “Voice Stack” for a Backend Implementation?
To build this server-side “recording studio,” you need to assemble a team of specialized AI experts and a high-speed communication network to connect them.
- The Intake Desk (The Voice Infrastructure): The first and most critical component is the service that receives the raw audio from the client. It’s the “mailroom” that accepts the audio package and delivers it to your studio. This is the specialized role of a voice infrastructure platform like FreJun AI.
- The Transcriber (Speech-to-Text – STT): This is the AI expert whose only job is to listen to the raw audio and type it out into a perfect, written transcript.
- The Strategist (Your Existing Chatbot’s LLM): This is the “brain” you’ve already built. It’s the expert that reads the transcript, understands the user’s goal, and formulates an intelligent, text-based response.
- The Announcer (Text-to-Speech – TTS): This is the voice talent. This expert takes the strategist’s written response and performs it as natural, human-like speech.
Your backend application’s primary role is to be the “Project Manager,” orchestrating this team of experts with microsecond precision.
What is Your Step-by-Step Guide to Backend Voice Integration?
Now, let’s connect these components. The following is a high-level tutorial for the server-side data flow of a single turn in a conversation.
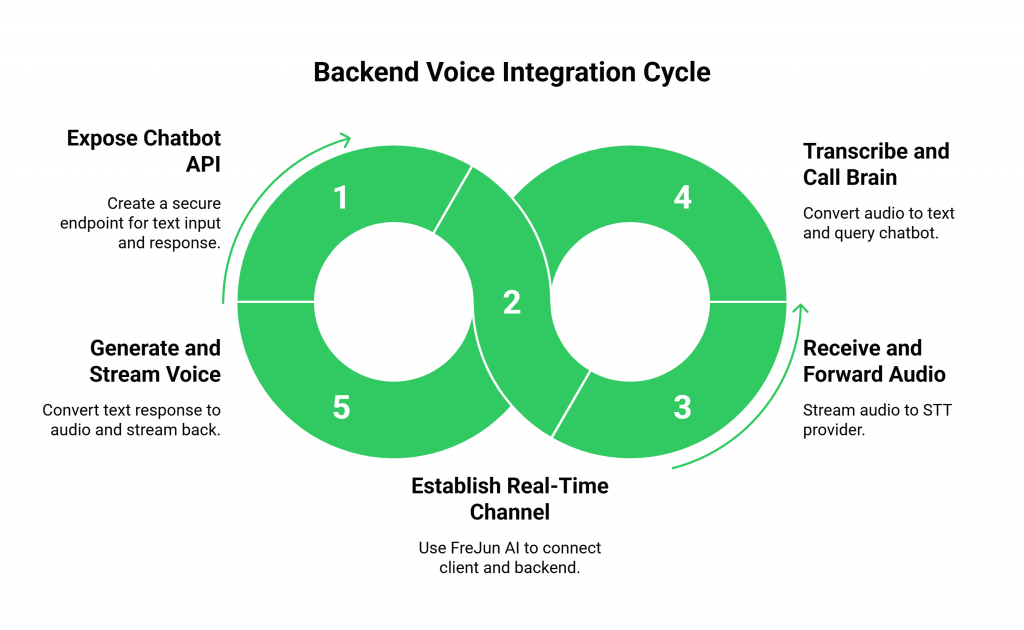
Step 1: How Do You Expose Your Existing Chatbot’s Brain?
Before you can add voice, your existing text-based chatbot must be accessible via an API. You need to create a secure endpoint on your server that can accept a piece of text (the user’s message) and will return your bot’s text-based response. This is the “front door” to the intelligence you’ve already created.
Step 2: How Do You Establish the Real-Time Communication Channel?
This is where you bridge the client to your backend. With a voice infrastructure provider like FreJun AI, this process is made simple.
- On your frontend, you’ll use FreJun AI’s lightweight client-side SDK to add a microphone button. This SDK’s primary job is to handle the complexity of accessing the device’s microphone and establishing a secure, real-time connection to the FreJun AI cloud.
- When a user starts a voice session, your backend server receives a webhook notification from FreJun AI.
- Your server then responds with a command that tells the FreJun AI platform to open a persistent, two-way audio stream (a WebSocket) directly to your backend server. Your backend is now officially “on the line.”
Also Read: How To Setup Voice Webhook Flows For LLM Agents?
Step 3: How Do You Build the Backend Orchestration Service?
This is the heart of the implementation. Your backend server is now receiving a live, raw audio stream from the user. It must now conduct the AI orchestra in a high-speed, continuous loop.
- Receive and Forward Audio: Your server takes the incoming raw audio packets from the FreJun AI WebSocket and immediately forwards them to the streaming API of your chosen STT provider.
- Transcribe and Call the Brain: The STT API sends back a live, rolling transcript. Your server listens for the end of the user’s utterance, then takes the final transcript and makes an API call to your existing chatbot’s “brain” endpoint (from Step 1).
- Generate and Stream the Voice: Your chatbot’s API returns its text response. Your server immediately begins streaming this text to your chosen streaming TTS API. As the TTS API generates audio packets, your server streams them back to the user through the open FreJun AI WebSocket.
This entire round trip must feel instantaneous. The experience of a seamless Chatbot Voice Assistant is a direct result of this high-speed backend orchestration.
Ready to build a voice assistant that your customers will love? Sign up for FreJun AI’s developer-first voice API.
What Advanced Backend Considerations Will Elevate Your Voice Chatbot?
Building a production-grade Chatbot Voice Assistant requires thinking beyond the basic loop. Full API control allows you to implement advanced features that create a truly exceptional experience.

How Do You Manage Latency for a Real-Time Feel?
Latency is the ultimate enemy of a natural conversation. Optimizing for speed is a backend-first concern.
- Co-location of Services: To minimize network lag, you should run your backend orchestration service in the same cloud region as your voice infrastructure provider’s nearest point of presence.
- Streaming Everything: For the lowest possible “time to first word,” you must use streaming APIs for every component: the voice infrastructure, the STT, the LLM (if it supports streaming), and the TTS.
- Choose a High-Performance Infrastructure: The speed of your voice API is the ultimate speed limit for your entire system. A platform engineered for ultra-low latency, like FreJun AI, is the critical foundation.
How Do You Implement Intelligent Utterance Detection?
A simple silence-based timer to detect when a user has finished speaking is often not enough. A more advanced backend can analyze the live transcript from the STT in real-time. It can look for grammatical cues (like the end of a sentence) or a drop in the STT’s confidence score to more intelligently and quickly determine that the user has completed their thought.
Also Read: How To Add Real-Time Agent Assist To Contact Centers?
How Do You Build for Scalability and Resilience?
Your backend service must be built to handle a massive number of concurrent conversations. This means designing your orchestration service to be stateless. The memory of each conversation should be stored in an external cache (like Redis), not on the application server itself.
This allows you to run multiple instances of your service behind a load balancer and use auto-scaling to handle traffic spikes gracefully. This robust architecture is vital, as a recent Salesforce report found that 80% of customers now say the experience a company provides is as important as its products.
Conclusion
Adding a voice to your chatbot is more than a simple frontend feature. It’s a major backend upgrade that builds real-time orchestration engine to handle, complex data between user and your AI’s brain. By taking a backend-first, API-driven approach, you gain full control and flexibility.
This lets you create a Chatbot Voice Assistant that is intelligent, scalable, and true to your brand. With strong voice infrastructure as your base, you can turn a silent chatbot into a powerful conversational partner.
Want to learn more about the infrastructure that powers the most advanced voice chat bots? Schedule a demo with FreJun AI today.
Also Read: What Is Click to Call and How Does It Simplify Business Communication?
Frequently Asked Questions (FAQs)
Keeping the logic in the backend provides better security (API keys are not exposed on the client), centralized control (all AI logic is in one place), and flexibility (the same backend can power a web, mobile, and phone interface).
A WebSocket is a communication protocol that provides a persistent, two-way connection between a client and a server. It’s essential for a real-time Chatbot Voice Assistant because it allows raw audio data to be streamed back and forth continuously with very low delay.
No. As long as your existing chatbot can be accessed via an API that accepts and returns text, you can add a voice “front-end” to it. Your new backend service will simply act as a translator between the world of voice and your existing text-based AI.
You should choose models that are optimized for real-time streaming. For STT, prioritize accuracy and support for your users’ accents. For TTS, prioritize a natural, expressive voice with a low “time to first byte” (the time it takes to start generating audio).
A model-agnostic platform like FreJun AI is not tied to a specific AI provider. It gives you the freedom to choose your own STT, LLM, and TTS models from any company, allowing you to build a “best-of-breed” solution.
Utterance detection is the process of determining when a user has finished speaking their sentence or phrase. This is a critical piece of logic in your backend that tells your application when to stop listening and start processing the user’s request with the LLM.
The unique sound comes from the Text-to-Speech (TTS) voice you choose. Many providers offer a wide library of voices, and some even allow you to create a custom, branded voice for your Chatbot Voice Assistant.
Scalability is achieved by building a stateless application that can be run on multiple servers behind a load balancer. This allows you to use cloud auto-scaling to automatically add more server capacity as your call volume increases.
Scalability is achieved by building a stateless application that can be run on multiple servers behind a load balancer. This allows you to use cloud auto-scaling to automatically add more server capacity as your call volume increases.
FreJun AI provides the essential voice infrastructure. It handles the complex and resource-intensive task of managing the real-time audio streams to and from the end-user. It delivers a clean, raw audio stream to your backend via a WebSocket, allowing your orchestration service to focus purely on the AI logic.