
For years, the dream of having a truly natural, real-time conversation with an AI has been tantalizingly close, yet always just out of reach. We have had the intelligence, thanks to massive, cloud-based Large Language Models (LLMs). But we have been perpetually fighting a losing battle against a fundamental law of physics: the speed of light.
The time it takes for a user’s voice to travel across the country to a centralized data center and for the AI’s response to make the entire journey back, a delay known as latency has been the single biggest barrier to a truly seamless experience. Now, a new architectural paradigm is shattering this barrier: edge computing.
The process of building voice bots is undergoing a profound transformation. We are moving from a purely centralized model to a more intelligent, distributed AI architecture.
By pushing key parts of the AI processing closer to the user, edge AI processing is drastically reducing latency, unlocking a new level of responsiveness that is finally making real-time, human-like conversation a practical reality. This is not just an incremental improvement; it is a quantum leap forward in the quest to build the perfect voice agent.
Table of contents
Why Has Latency Been the Arch-Nemesis of Voice AI?
To understand the power of the edge, we must first have a deep respect for the problem it solves. In a voice conversation, latency is the enemy. It is the awkward pause of dead air after you ask a question, the moment of silence that makes an AI feel slow, clunky, and unintelligent. This delay is the cumulative sum of several steps:
- Network Lat. (User to Cloud): The time for your voice to travel to the data center.
- STT Latency: The time for Speech-to-Text to transcribe your voice.
- LLM Latency: The time for the AI “brain” to think of a response.
- TTS Latency: The time for Text-to-Speech to create the audio response.
- Network Lat. (Cloud to User): The time for that audio to travel back to you.
While developers are making the AI models (STT, LLM, TTS) faster, the two biggest and most stubborn components of this delay have always been the round-trip network time. For a traditional, fully cloud-based voice bot, achieving this has been nearly impossible due to the sheer physical distance the data must travel.
Also Read: VoIP API: Building Voice Communication into Your Applications
What is Edge Computing and How Does It Change the Game?
Edge computing is a powerful architectural shift. Instead of processing all data in a few massive, centralized cloud data centers, it involves performing computation at “the edge” of the network, in smaller, distributed data centers that are physically much closer to the end-user.
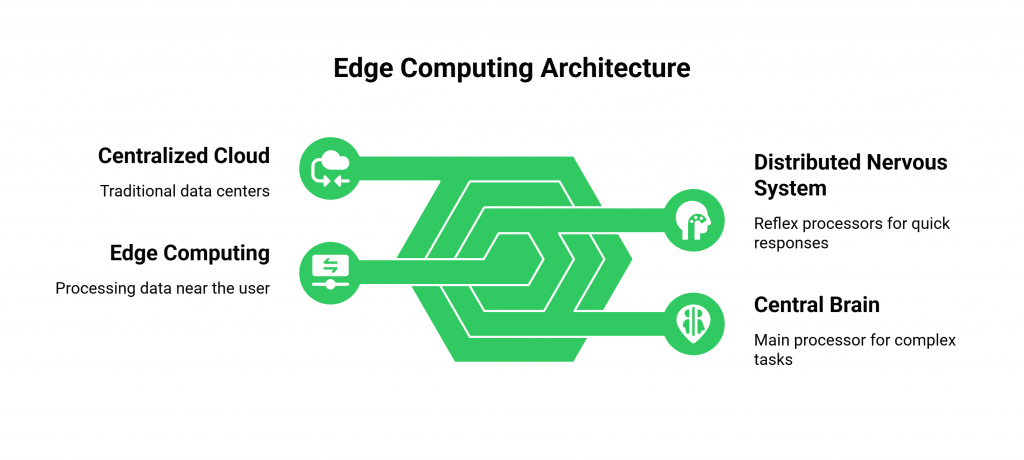
From a Central Brain to a Distributed Nervous System
Think of it this way:
- The Old Model (Centralized Cloud): A single, massive brain located in one city. A signal from your hand (the user) has to travel all the way to this brain and back again for you to feel a response.
- The New Model (Edge Computing): A distributed AI architecture. The main brain still exists for deep, complex thoughts, but there are also smaller, faster “reflex” processors in your spinal cord and limbs (the edge servers). A simple touch reflex is processed locally, resulting in an instantaneous reaction.
When we are building voice bots, this “reflex processing” is the key. By placing parts of the AI workflow on these edge servers, we drastically shorten the distance the data has to travel for the most common, time-sensitive parts of the conversation.
How Does Edge AI Processing Work in a Real-Time Call?
The modern approach to building voice bots is a sophisticated, hybrid cloud voice bots model. It is not about abandoning the powerful, large-scale models in the central cloud. It is about using them more intelligently, in partnership with smaller, faster models at the edge.
The “Hot Path” and the “Cold Path”
The workflow is split into two paths:
The “Hot Path” (at the Edge)
This path handles the most immediate, real-time parts of the conversation. The goal here is pure speed. This is where low-latency call handling is paramount.
- The Call Connection: The initial phone call is connected at an edge server from a provider like FreJun AI, immediately minimizing the first leg of network latency.
- Initial STT and Intent Recognition: A lightweight, fast STT model and a smaller, specialized Natural Language Understanding (NLU) model can run at the edge. Their job is to quickly transcribe the user’s speech and figure out the basic intent. For simple, common requests (“What is my balance?”), the edge agent might be able to handle it entirely on its own.
- Quick Responses and “Thinking” Prompts: If the edge agent can answer, it does so instantly. If it needs the “big brain,” its job is to provide an immediate acknowledgment to the user, like, “Okay, let me pull up your account details.” This fills the silence while the more complex query is processed.
The “Cold Path” (in the Central Cloud)
- Complex Queries: When the edge agent determines that a more complex reasoning or data lookup is needed, it seamlessly passes the transcribed text and conversational context to the massive LLM in the central cloud.
- The Deep Brain: The large LLM does its work, and sends the text response back to the edge agent.
- The Final Response: The edge agent then takes this text, synthesizes it into speech using a local TTS engine, and delivers it to the user.
This hybrid model gives you the best of both worlds: the lightning-fast reflexes of the edge, and the deep, creative intelligence of the central cloud.
This table summarizes the division of labor in a distributed AI architecture.
| Task | Location | Primary Goal | Key Technologies |
| Call Connection & Media Streaming | Edge | Lowest Possible Latency | Edge-native voice infrastructure (e.g., FreJun AI’s Teler). |
| Simple Intent Recognition & Quick Answers | Edge | Instantaneous Response | Lightweight STT/NLU models; on-device inference (future). |
| Complex Reasoning & Data Retrieval | Central Cloud | Deep Intelligence and Accuracy | Massive Large Language Models (LLMs). |
| Final Audio Synthesis (TTS) | Edge | Fast, High-Quality Audio | Streaming TTS engines. |
Ready to start building voice bots that feel truly instantaneous? Sign up for FreJun AI
Also Read: Voice Call API: Automating and Scaling Customer Communication
The Future: On-Device Inference
The logical next step in this evolution is to push the “hot path” processing even further out, from the provider’s edge server directly onto the user’s own device (their smartphone). This is the world of on-device inference.
As mobile processors become more powerful and AI models become smaller and more efficient, it will become possible to run the entire initial STT and NLU process directly on the user’s phone. This would reduce the initial network latency to virtually zero.
The device would only need to send a small, structured intent message to the edge or cloud, rather than a heavy audio stream. This is the ultimate goal of the distributed AI architecture and will be a major focus of innovation in the coming years.
How Does FreJun AI Enable This Edge-Native Future?
At FreJun AI, our entire platform was built on the architectural principles of the edge. We are not a traditional, centralized telecom company that is trying to adapt to the new world. FreJun AI is a modern, developer-first voice infrastructure provider that was born in it.
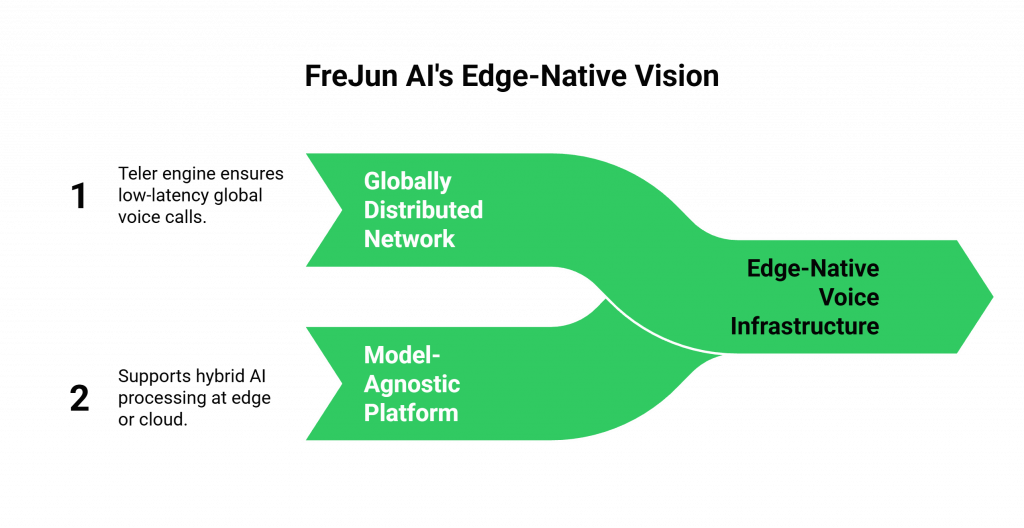
- A Globally Distributed, Edge-Native Network: Our Teler engine is a network of Points of Presence around the globe. This is the essential foundation for low-latency call handling.
- A Flexible, Model-Agnostic Platform: Our architecture is designed to support this hybrid model. We provide the high-performance, edge-based “plumbing” for the voice call, but we give you, the developer, the complete freedom to decide where and how you want to run your AI processing, whether it is at the edge, in the central cloud, or a combination of both.
We handle the complex voice infrastructure so you can focus on building your intelligent hybrid cloud voice bots.
Also Read: The Ultimate Guide to Choosing the Right Voice Calling SDK for Your Product
Conclusion
The process of building voice bots that can have truly natural, real-time conversations is no longer a dream limited by the speed of light. The architectural shift to edge computing is fundamentally changing the equation.
By moving the most time-sensitive parts of the AI workflow closer to the user, we can slash the latency that has long plagued voice AI, creating an experience that is not just intelligent, but truly instantaneous.
This distributed AI architecture, combining the reflexes of the edge with the deep intelligence of the cloud, is not just a passing trend; it is the future of human-to-machine communication.
Want to do a technical deep dive into how you can deploy your AI models at the edge and connect them to our low-latency voice network? Schedule a demo for FreJun Teler.
Also Read: How to Select the Best Cloud Telephony Solution for Your Industry
Frequently Asked Questions (FAQs)
The main benefit is a dramatic reduction in latency. By processing the initial parts of the conversation at a server that is physically closer to the user, edge AI processing makes the voice bot’s responses feel much faster and more natural.
A distributed AI architecture is a system design where different parts of the AI’s processing are spread out across different locations. For voice bots, this typically means running lightweight, fast models at the edge for real-time interaction and using larger, more powerful models in a central cloud for complex thinking.
Edge AI processing happens on a provider’s server that is located at the “edge” of the network, close to the user. On-device inference is the next step, where the AI processing happens directly on the user’s own device (e.g., their smartphone), which reduces latency even further.
It enables low-latency call handling by minimizing network travel time. The voice call is connected and the initial audio processing is done at an edge server, which is much closer to the user than a traditional, centralized cloud data center.
A hybrid cloud voice bot is another term for a voice bot that uses this distributed architecture. It uses a combination of “edge cloud” resources for speed and “central cloud” resources for deep intelligence.
Often, yes. Use a small, optimized model at the edge for fast, simple tasks. A larger, comprehensive model in the cloud handles complex reasoning.
A well-designed system uses edge AI to give instant prompts, masking the cloud AI’s processing time for complex queries.