
For years, the voice of automation was a monotone, robotic drone, a sound that was instantly recognizable and universally disliked. It was the voice of a machine, and it created a cold, impersonal barrier between a business and its customers. Today, we are standing on the cusp of a new era. The rise of incredibly advanced, expressive TTS models and sophisticated emotional prosody control is finally making it possible to build voice bots that do not just speak, but emote.
They can sound empathetic when a customer is frustrated, cheerful when sharing good news, and urgent when conveying a critical alert. This is the new frontier in building voice bots.
Achieving lifelike voice synthesis is no longer a futuristic dream; it is a complex but achievable engineering challenge. It is the final and most crucial step in creating an AI that is not just intelligent, but also engaging and trustworthy.
For developers and businesses looking to create a truly superior customer experience, mastering the art and science of natural voice generation is the key to building a voice agent that people will actually want to talk to. This guide will explore the technologies and the design principles required to breathe life, emotion, and prosody into your voice bots.
Table of contents
What is Prosody and Why is it the Soul of Conversation?
Before we can control it, we must first understand it. Prosody, in the context of speech, is the “music” of language. It is everything beyond the words themselves. It is the rhythm, the stress, the pitch, and the intonation of our speech.
Think about the simple phrase, “I’m fine.”
- Said with a flat, falling intonation, it means “I am okay.”
- Said with a rising intonation at the end (“I’m fine?”), it becomes a question, expressing uncertainty.
- Said with a sharp, stressed emphasis on the word “fine,” it can convey sarcasm or frustration.
The words are the same, but the prosody completely changes the meaning and the emotional content. For an AI voice agent, a lack of prosody is what makes it sound robotic. It is the reason that a simple, text-based chatbot can often feel more “human” than a monotone voice bot. Mastering prosody is the key to unlocking believable and effective lifelike voice synthesis.
Also Read: Best Practices for Testing and Debugging Voice Calling SDK Integrations
How Do Modern TTS Models Enable Emotional Control?
The revolution in natural voice generation has been driven by massive advancements in the underlying Text-to-Speech (TTS) technology. The old, concatenative synthesis (which stitched together pre-recorded sounds) has been replaced by deep learning and neural network-based models.
The Rise of Neural TTS
Modern TTS engines, like those from Google, Amazon, and a host of innovative startups, use complex neural networks to generate speech from scratch. This approach has several key advantages:
- Incredibly Natural Sound: The speech is far smoother and more human-like than the old, stitched-together models.
- The Ability to Be “Trained”: These models can be trained on vast datasets of human speech, allowing them to learn the subtle nuances of prosody and intonation.
- The Power of Expressive Control: This is the most exciting development. Many advanced neural TTS models are now expressive TTS models. They are built with the ability to be controlled and directed in real-time.
The Toolkit for Emotional Prosody Control
This is where the developer’s work begins. A modern, expressive TTS engine provides a set of powerful “levers” that a developer can use to shape the AI’s speech. This emotional prosody control is often achieved through a special markup language called Speech Synthesis Markup Language (SSML).
SSML is an XML-based language that you can use to annotate your plain text before sending it to the TTS engine. It allows you to control a wide range of vocal characteristics. Here are some of the most common tags and what they do:
| SSML Tag | What It Controls | Example Use Case for a Voice Bot |
| <emphasis> | Places stress on a specific word or phrase. | “Your payment is severely overdue.” |
| <prosody rate=”…”> | Controls the speed of the speech (e.g., “slow,” “medium,” “fast”). | Speaking slower when giving a complex confirmation number. |
| <prosody pitch=”…”> | Controls the baseline pitch of the speech (e.g., “low,” “high”). | Using a slightly higher pitch for a cheerful greeting. |
| <prosody volume=”…”> | Controls the volume of the speech (e.g., “soft,” “loud”). | Speaking louder for an urgent warning. |
| <break time=”…”/> | Inserts a pause of a specific duration. | “Your confirmation number is… [pause] …12345.” |
| <say-as interpret-as=”…”> | Controls how things like dates, numbers, and currencies are pronounced. | Ensuring that “1/2” is read as “January second” and not “one half.” |
| <emotion name=”…”> | [Advanced] Some of the latest models allow you to specify an emotional tone directly. | <emotion name=”excited”>Congratulations, your loan has been approved!</emotion> |
This granular level of control is the key to conversational tone tuning. It is a skill that is becoming increasingly important for any developer building voice bots.
Ready to start building voice bots that can truly connect with your users? Sign up for FreJun AI.
Also Read: How a Voice Calling SDK Can Improve Customer Experience in AI Voice Agents?
How Do You Know When to Use Emotion in Building Voice Bots?
Having the technical tools to control emotion is only the first step. The much harder and more important part is the design: knowing when and how to use these tools to create an authentic and effective experience. A poorly timed or inauthentic emotional expression can be worse than no emotion at all.
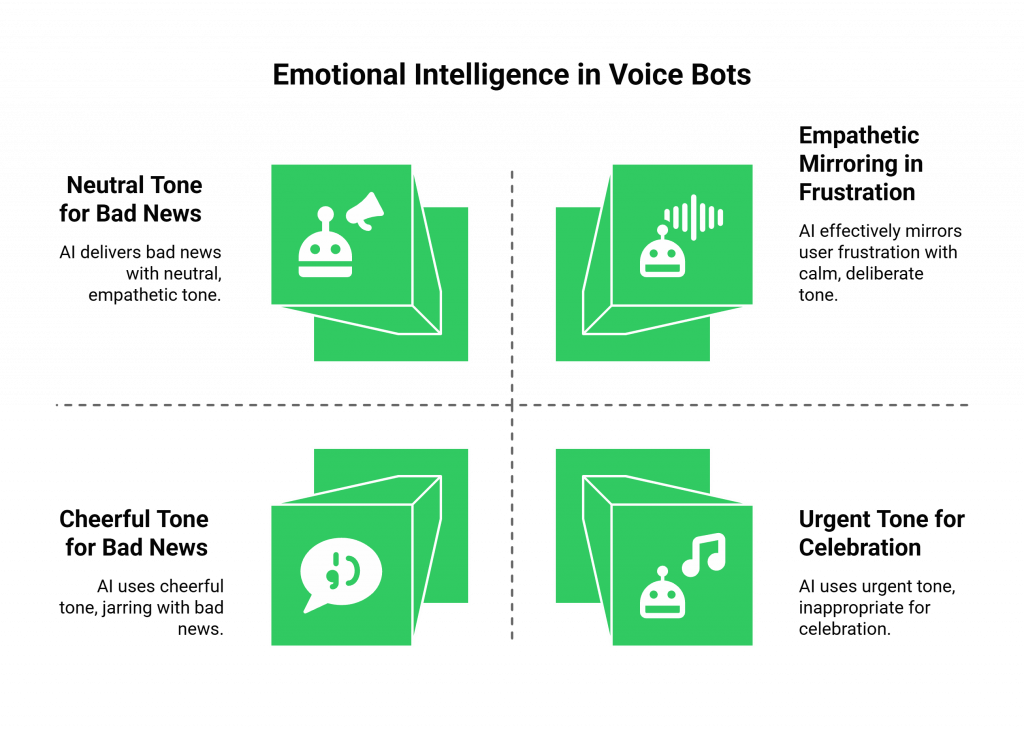
The Principle of “Empathetic Mirroring”
One of the most effective principles in multichannel conversational design is the concept of empathetic mirroring. In a human conversation, we often subconsciously mirror the emotional state of the person we are talking to. An AI can be designed to do the same.
- Detect the User’s Emotion: By integrating a real-time sentiment analysis service, your AI can get a sense of the user’s emotional state from the tone of their voice.
- Adjust the AI’s Tone: If the AI detects that the user is frustrated, it can be programmed to switch to a TTS voice and prosody that is more calm, deliberate, and empathetic. For example, it might slow down its speaking rate and use a slightly lower pitch. If the user is excited, the AI can mirror that with a more upbeat and faster-paced response.
The Importance of Context
The emotional tone must always be appropriate for the context of the conversation.
- Delivering Bad News: When delivering bad news (e.g., “I’m sorry, your flight has been canceled”), the AI should use a neutral, empathetic, and slightly slower tone. A cheerful voice in this context would be incredibly jarring and would damage the user’s trust.
- Handling Urgent Alerts: For a critical alert (e.g., a fraud warning on a bank account), the AI should use a tone that is clear, slightly faster than normal, and uses emphasis to highlight the most important information.
- Celebrating a Success: For good news (e.g., “Your package has been delivered!”), a more cheerful and upbeat tone is perfectly appropriate.
The goal is not to create an AI that is “emotional” in a human sense, but to create one that is emotionally intelligent, one that can understand the emotional context of a situation and respond in a way that is appropriate and helpful.
What is the Role of the Voice Infrastructure in This?
To implement this kind of dynamic, real-time conversational tone tuning, your underlying voice infrastructure must be incredibly fast and flexible. This is where a platform like FreJun AI is essential.
- Low-Latency is Non-Negotiable: For the AI to detect a user’s emotion and adjust its response in real time, the entire round-trip of data must happen in a fraction of a second. Our globally distributed, edge-native architecture is built to provide this low-latency AI voice platform.
- Model-Agnostic Flexibility: The world of expressive TTS models is evolving rapidly. Our platform is model-agnostic. This means you are never locked into a single TTS provider. You are free to choose the most advanced, most expressive, and most natural-sounding voice from any vendor on the market and integrate it into your workflow. We handle the complex voice infrastructure so you can focus on building your AI.
Also Read: Voice Calling SDKs for Enterprises: Scaling Conversations with AI and Telephony
Conclusion
The journey of building voice bots has reached a new and exciting inflection point. We are moving beyond the simple goal of transactional automation and into the more nuanced world of conversational experience design.
The ability to achieve human-like prosody and emotion is the final frontier in making voice AI a truly mainstream and beloved technology. It is a complex challenge that requires a powerful fusion of advanced, expressive TTS models and a thoughtful, empathetic approach to conversational design.
By mastering the tools of emotional prosody control and by building on a high-performance, low-latency voice infrastructure, developers can now create voice agents that do not just transact, but truly connect.
Want to do a deep dive into the technical details of SSML and see a live demonstration of how to control a TTS model’s emotion in real-time? Schedule a demo for FreJun Teler.
Also Read: Solving Cloud Telephony Challenges: Downtime, Scale, and Number Porting
Frequently Asked Questions (FAQs)
“Voice” refers to the fundamental sound quality of the speaker (e.g., deep, high-pitched, raspy). “Prosody” refers to the musicality and emotional color of how words are spoken, including the rhythm, stress, and intonation. You can have a beautiful voice but still sound robotic if you lack prosody.
No. An AI does not “feel” emotions in a human or biological sense. When we talk about an “emotional” AI, we are referring to its ability to simulate emotional expression in its speech to make the conversation feel more natural and empathetic to the human listener.
There’s no single best choice; select a voice that sounds natural, clear, and professional, fitting your brand and interaction context.
The most common mistake is using an inappropriate emotional tone for the situation. For example, using a cheerful, upbeat voice to inform a customer that their credit card has been declined would be a very poor and jarring user experience.
Developers ensure correct pronunciation using a custom lexicon or SSML tags like to provide phonetic spellings to the TTS engine.
Advanced expressive TTS may add a few milliseconds of latency, but overall voice infrastructure latency has a far greater impact on user experience.
A multilingual voice bot should adjust prosody to match each language’s natural cadence, reflecting emotional cues and rhythms accurately.