
In the world of DevOps, there is a sacred pact with the user: the service must always be on. For a website or a mobile app, this means ensuring that a user’s click always gets a response. But when your service is a real-time voice bot, the stakes are dramatically higher. An “outage” is not a slow-loading webpage; it is a dropped call, a moment of dead air, or a complete failure to answer the phone.
For the DevOps teams tasked with building voice bots, maintaining mission-critical uptime is a unique and formidable challenge. It is an intricate dance of managing a complex, distributed system that spans from your own application code all the way to the global telephone network.
The secret to mastering this challenge lies in extending the core principles of modern DevOps, automation, monitoring, and resilience, to the unique domain of real-time communication. It is about treating your voice infrastructure not as a static, third-party utility, but as a dynamic, observable, and fully integrated part of your application stack.
This requires a new set of tools and a new way of thinking, where observability for telephony is just as critical as the infrastructure health monitoring for your own servers.
Table of contents
Why is Maintaining Uptime So Different for Voice?
A voice bot is not a standard, stateless web application. It is a complex, stateful, and highly time-sensitive system with many more potential points of failure than a typical app. A DevOps team that approaches it with a traditional mindset will be caught off guard.
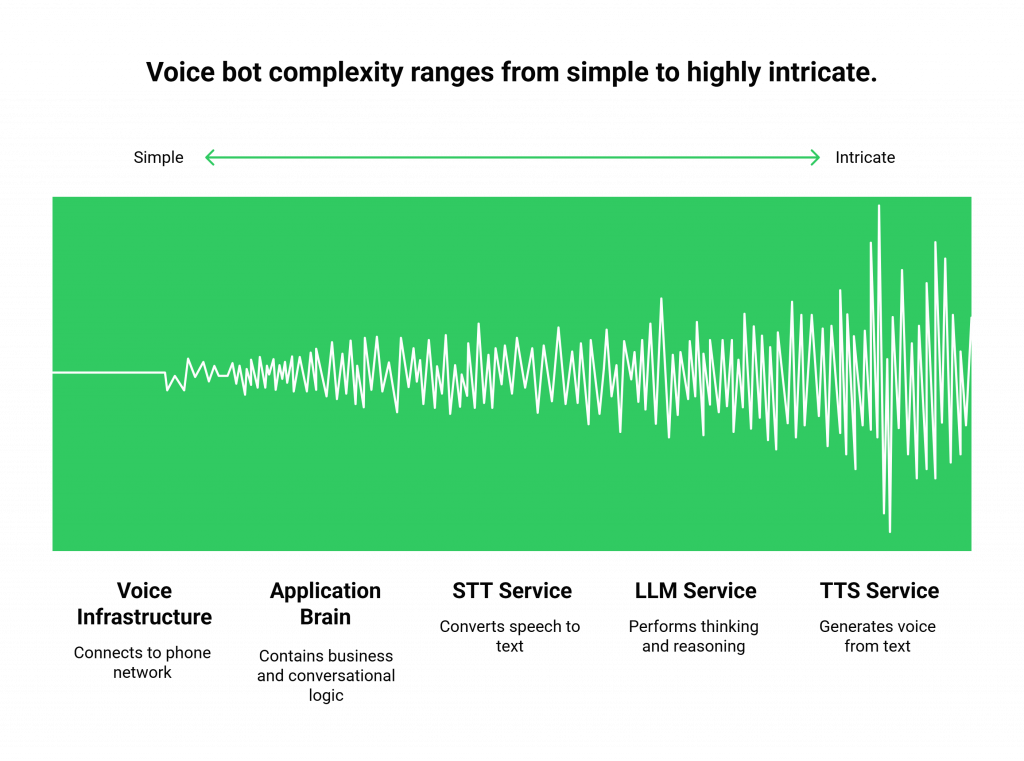
The Many Moving Parts of a Voice Bot
A single voice bot conversation is a high-speed relay race between multiple, independent services that must work in perfect, sub-second harmony.
- The Voice Infrastructure (e.g., FreJun AI’s Teler): The underlying platform that connects to the phone network.
- Your Application’s “Brain” (Your AgentKit): The code you write that contains the business and conversational logic.
- The STT Service: The Speech-to-Text engine.
- The LLM Service: The Large Language Model that does the “thinking.”
- The TTS Service: The Text-to-Speech engine that generates the voice.
A failure in any one of these components can break the entire conversation. This is a far more complex dependency chain than a typical web app that just talks to a database.
The Intolerance of Latency and Failure
In a web application, a small delay or a temporary error is often manageable. The user can simply hit “refresh.” In a live phone call, there is no refresh button.
- Latency is Failure: A delay of more than a few hundred milliseconds is not just a performance issue; it is a functional failure of the conversation.
- Errors are Catastrophic: If your LLM’s API has a 2-second timeout, that translates to 2 seconds of dead air on the phone, which will almost always cause the user to hang up in frustration.
Also Read: Voice Calling SDKs for Enterprises: Scaling Conversations with AI and Telephony
What is the DevOps Framework for High-Availability Voice Bots?
To maintain uptime while building voice bots, a DevOps team must adopt a comprehensive strategy that covers the entire lifecycle of the application, from development to deployment to ongoing operations. This strategy is built on three core pillars: proactive monitoring, automated resilience, and a robust CI/CD pipeline.
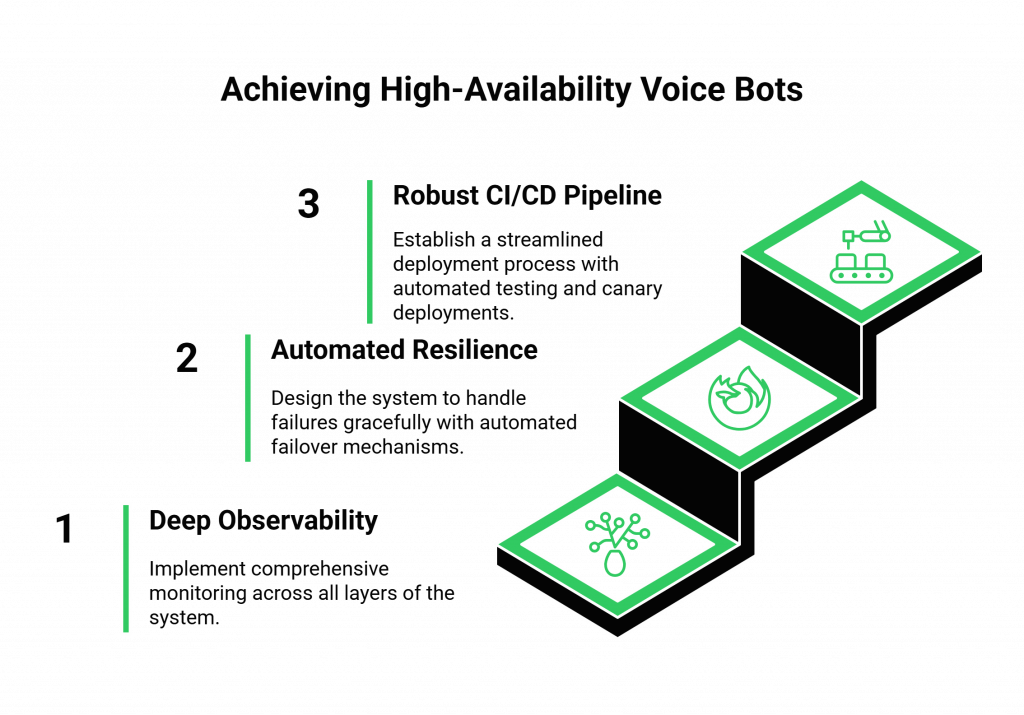
Pillar 1: Deep Observability at Every Layer
You cannot fix what you cannot see. Observability for telephony and the entire AI stack is the absolute foundation of a reliable system. This goes far beyond a simple “is the server up?” check.
- Infrastructure Health Monitoring: This is the baseline. You need to monitor the CPU, memory, and network status of the servers hosting your application’s “brain” (your AgentKit).
- Voice Infrastructure Monitoring: Your voice platform provider is a critical dependency. A modern provider like FreJun AI offers a real-time status page and detailed health metrics for their own network. You should integrate these metrics into your central monitoring dashboard.
- End-to-End Transaction Tracing: This is the most critical part of devops monitoring for voice ai. For every single conversational turn, you must be able to trace the entire journey of the data: the time it took for the audio to be transcribed by the STT, the time the LLM took to generate a response, and the time the TTS took to synthesize the audio. If your total latency suddenly spikes, you need to be able to instantly pinpoint which of these components is the bottleneck.
- Real-Time Alerting: You need to set up automated alerts for both systemic failures (e.g., your application server is down) and performance degradation (e.g., the average LLM response time has exceeded 1.5 seconds).
Pillar 2: Designing for Resilience with Automated Failover
In a distributed system, individual components will fail. A resilient architecture is not one that never fails, but one that can gracefully handle the failure of its parts.
- Redundancy for Your Application: Your AgentKit should never be a single point of failure. It should be deployed across multiple servers or containers and multiple availability zones, with a load balancer in front. If one instance crashes, the traffic should be automatically rerouted to a healthy one.
- Automated Failover for AI Agents: What if your primary LLM provider (e.g., OpenAI) has an outage? A production-grade system should be designed with an automated failover for ai agents. Your application code should have a try…catch block around the LLM API call. If the primary provider fails or times out, your code should automatically retry the request with a secondary provider (e.g., Anthropic or a self-hosted model).
- Graceful Degradation: For non-critical features, you can design the system to “fail gracefully.” For example, if your AI’s connection to the CRM goes down, it might not be able to look up a customer’s order history, but it should still be able to answer general questions. It can say, “I’m having trouble accessing account details right now, but I can still help you with general product information.”
Also Read: How to Enable Global Calling Through a Voice Calling SDK (Without Telecom Headaches)
Pillar 3: A Robust CI/CD Pipeline for Voice Automation
The speed and safety of your deployments are critical for maintaining uptime. A ci cd for voice automation pipeline needs to include a few specialized stages.
- Automated “Golden Path” Testing: As part of your pipeline, you should have an automated test that makes a real phone call to your application in a staging environment and validates that the core conversational path is working correctly. This is your first line of defense against deploying a broken build.
- Canary Deployments: When you deploy a new version of your voice bot’s logic, do not send 100% of your traffic to it at once. Use a canary deployment strategy where you initially route a small percentage of calls (e.g., 1%) to the new version.
You can then monitor the performance and error rates in real-time. If everything looks good, you can gradually increase the traffic. If you see a problem, you can instantly roll back with minimal impact on your users. The adoption of these advanced deployment strategies is a key indicator of DevOps maturity.
This table provides a summary of the key strategies for maintaining uptime.
| DevOps Pillar | Key Strategy | Why It’s Critical for Building Voice Bots |
| Observability | End-to-end transaction tracing for the entire AI workflow (STT, LLM, TTS). | Instantly pinpoints the source of latency, which is the most common and critical issue in a voice conversation. |
| Resilience | Implementing automated failover for your third-party AI model dependencies. | Protects your service from the inevitable outages of your AI providers, ensuring your bot is still responsive. |
| CI/CD | Using canary deployments for new versions of your bot’s logic. | Allows you to safely and gradually roll out changes, minimizing the risk of a bad deployment causing a major outage. |
Ready to build your voice bot on an infrastructure that provides the reliability and observability you need? Sign up for FreJun AI and explore our powerful platform features.
Also Read: Voice Calling SDKs Explained: The Invisible Layer Behind Every AI Voice Agent
Conclusion
The process of building voice bots that can meet the rigorous uptime and performance demands of a production environment is a masterclass in modern DevOps. It requires a holistic strategy that extends beyond the application code to encompass the entire, complex ecosystem of real-time communication.
By embracing a deep commitment to observability for telephony and the entire AI stack, by designing for resilience with automated failover for ai agents, and by implementing a sophisticated ci cd for voice automation pipeline, DevOps teams can confidently manage the unique challenges of this new frontier.
The result is a voice bot that is not just intelligent, but is also a truly reliable, scalable, and mission-critical asset for the business.
Want a technical deep dive into how our platform’s observability features can integrate with your existing DevOps monitoring tools? Schedule a demo with our team at FreJun Teler.
Also Read: Cloud Telephony for Hybrid, Flexible, and BYOD Work Models
Frequently Asked Questions (FAQs)
The biggest challenge is the real-time, stateful, and highly distributed nature of a voice application. A failure in any one of the many independent components (voice platform, STT, LLM, TTS, your own application) can break the entire user experience, making monitoring and resilience critical.
Observability for telephony is the ability to have deep, real-time visibility into the performance and health of the underlying voice infrastructure. This includes monitoring call connectivity, audio quality metrics (like jitter and packet loss), and the success of API calls to the voice platform.
Infrastructure health monitoring for a voice bot involves monitoring two key areas: the health of your own application’s servers (your AgentKit) and the health of your third-party voice provider’s platform (like FreJun AI’s Teler engine), which you should be able to see via a public status page.
Automated failover for AI agents is a design pattern where your application is built to automatically switch to a secondary or backup AI model (e.g., a different LLM provider) if the primary one fails or becomes too slow. This is crucial for maintaining uptime when you are dependent on third-party AI services.
A CI/CD for voice automation pipeline should include specialized testing stages. A key difference is the need for an automated “end-to-end” test that makes a real phone call to your application in a staging environment to validate the core conversational flow before deploying to production.
A canary deployment is a strategy for safely releasing new software. Instead of directing all traffic to the new version at once, you start by sending a small percentage of real user traffic to it. You then monitor its performance closely. If it is stable, you gradually increase the traffic until all users are on the new version.
Effective DevOps monitoring for voice AI requires “end-to-end transaction tracing.” You must log the timestamp at each step of the conversational turn: when the audio is received, when the STT finishes, when the LLM responds, and when the TTS finishes. The differences between these timestamps will tell you exactly where the latency is coming from.
FreJun AI provides a highly reliable, carrier-grade voice infrastructure as the foundation. We also provide the critical observability tools you need, such as detailed call logs, real-time quality metrics, and a public status page, which are essential for your infrastructure health monitoring.
There are network simulation tools (like tc in Linux or third-party tools) that allow you to artificially introduce latency, jitter, and packet loss into your test environment. This allows you to see how your application will behave for a user on a poor mobile connection.
The “golden path” (or “happy path”) is the most common, successful journey that a user takes through your application. Your most important automated tests should be focused on ensuring that this core path is always working correctly.