
In the world of artificial intelligence, there is a single, indisputable truth: a model is only as good as the data it is trained on. For teams building voice bots, this truth presents a formidable challenge. A sophisticated voice agent needs to understand a vast and messy world of human speech, a world of different accents, background noises, and an almost infinite variety of phrasing.
The traditional approach of waiting to collect thousands of hours of real-world customer calls to train a model is slow, expensive, and fraught with privacy risks. This is the “data dilemma,” and it is the single biggest bottleneck in the development of high-performance voice AI.
Fortunately, a powerful solution has emerged: synthetic data. This is not just “fake” data; it is a sophisticated technique for creating large, high-quality, and perfectly tailored datasets from scratch. By leveraging synthetic voice datasets, development teams can break free from the constraints of real-world data, solving the “cold start” problem, eliminating bias, and dramatically accelerating the journey from concept to a production-ready building voice bots.
This article will explore how ai data augmentation and conversational dataset generation are fundamentally changing the way we build and train the next generation of voice AI.
Table of contents
What is the “Data Dilemma” in Speech Model Training?
Every team building voice bots eventually runs into the data dilemma. The machine learning models at the heart of a voice agent, especially the Automatic Speech Recognition (ASR or STT) and Natural Language Understanding (NLU) components are incredibly data-hungry.
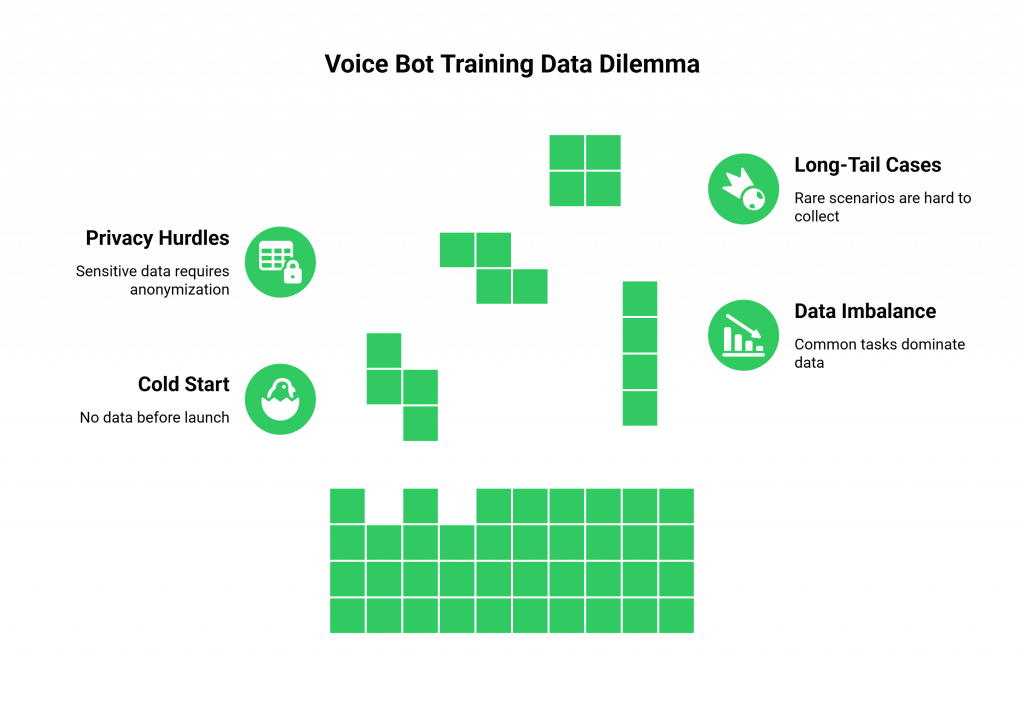
To perform well, they need to be trained on a massive and diverse set of examples. However, acquiring and using real-world data is plagued with problems. The primary limitations of real-world data include:
- The “Cold Start” Problem: This is the classic chicken-and-egg scenario. You are building voice bots for a new product or service. To make the bot effective, you need data from real user calls. But you cannot get real user calls until you launch the bot. This leaves you starting from zero, often forced to launch with a poorly performing, generic model.
- Inherent Data Imbalance: The real-world data you do collect is almost never evenly distributed. Your call logs might show that 95% of inquiries are simple “what’s my balance?” questions, while only 5% are complex and critical “I think my account is compromised” scenarios. Training a model on this imbalanced dataset will result in a bot that is excellent at the simple task but fails miserably at the rare but crucial one.
- Major Privacy and Compliance Hurdles: Real call recordings are a minefield of Personally Identifiable Information (PII), financial details, and other sensitive data. Using this data for speech model training requires a complex and costly process of anonymization and scrubbing, which can itself strip the data of valuable context. Navigating the legal requirements of regulations like GDPR and HIPAA can slow down development by months.
- A Lack of “Long-Tail” Edge Cases: Your real data will cover the most common scenarios, but it will likely miss the thousands of rare, unusual, or “long-tail” ways that a user might phrase a request. A robust voice bot needs to be able to handle these edge cases gracefully, but it is nearly impossible to collect enough real-world examples of them.
Also Read: How to Enable Global Calling Through a Voice Calling SDK (Without Telecom Headaches)
How Does Synthetic Data Provide a Powerful Solution?
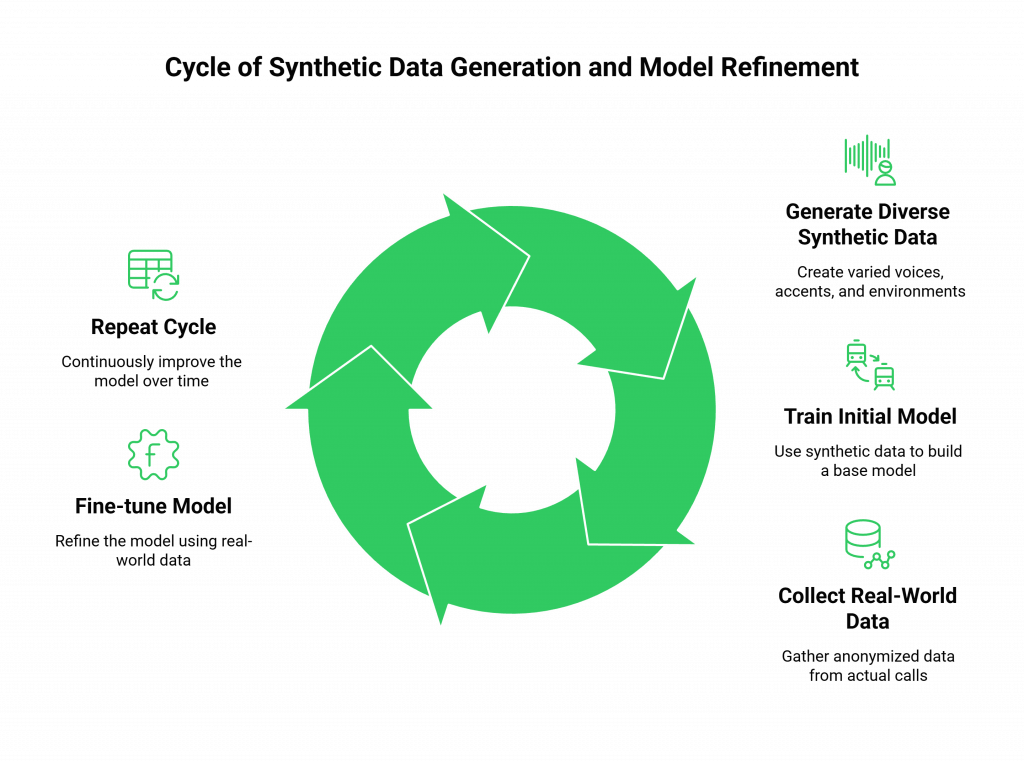
Synthetic data is artificially generated data that is designed to mimic the statistical properties and patterns of real-world data. In the context of voice AI, this means creating vast, high-quality synthetic voice datasets from the ground up, giving you complete control over the final product. The process of conversational dataset generation is a sophisticated workflow that goes far beyond just creating random audio files. The process typically involves these key stages:
- Define the Scenarios: It starts with a clear definition of the intents (what the user wants to do, e.g., “check balance”), entities (the key pieces of information, e.g., “account number”), and conversational flows you want to model.
- Generate Text Variations: Using a Large Language Model (LLM), you can generate thousands or even millions of different text-based variations for each intent. For example, you can generate 5,000 different ways a person might ask to reset their password.
- Synthesize High-Quality Audio: This text data is then fed into an advanced Text-to-Speech (TTS) engine. This is not a single, robotic voice. Modern TTS services can generate speech in a wide variety of voices, accents, genders, and emotional tones.
- Introduce Realistic Noise: To make the simulated call data truly effective, you can then layer in realistic background noise, the sound of a busy coffee shop, a car on the highway, a dog barking.
The result is a massive, perfectly labeled, and completely privacy-compliant dataset that you can use for your speech model training.
Also Read: Voice Calling SDKs Explained: The Invisible Layer Behind Every AI Voice Agent
What Are the Key Use Cases for Synthetic Data When Building Voice Bots?
Leveraging synthetic data is not just a theoretical exercise; it is a practical strategy that solves some of the biggest challenges in the voice AI development lifecycle.
Key use cases include:
- Bootstrapping New Models (Solving the “Cold Start” Problem): This is the most powerful application. You can use conversational dataset generation to create a massive, high-quality dataset and train a highly effective, custom model for your voice bot before it has ever taken a single live call.
- Balancing Biased Datasets: If your small, existing set of real data is heavily skewed toward one type of call, you can use ai data augmentation to fix this. You can generate thousands of simulated call data examples for your underrepresented intents, creating a much more balanced and robust final model.
- Stress-Testing and Improving Robustness: You can use synthetic data as a targeted tool to make your bot more resilient. Intentionally generate audio with challenging accents, low-quality audio, or unusual phrasing to find the breaking points of your model and then use that data to improve it.
- Accelerating Development While Ensuring Privacy: This is a huge benefit for enterprise teams. Your developers can be given access to massive, realistic synthetic voice datasets to build and test their models without ever needing to touch sensitive, PII-laden customer recordings. This removes privacy and compliance bottlenecks and dramatically speeds up the development process.
Ready to connect your finely-tuned model to a real-time, production-grade voice channel? Sign up for FreJun AI.
What Are the Best Practices for Generating High-Quality Synthetic Data?
The effectiveness of your speech model training will depend on the quality of your synthetic data. It is not just about generating a lot of data; it is about generating the right data.
How Do You Ensure Diversity and Realism?
Your synthetic data must reflect the messy reality of the real world.
- Vary the Voices: Use a TTS service that offers a wide range of voices, genders, ages, and speaking rates.
- Introduce Diverse Accents: If your customer base is global or linguistically diverse, you must generate audio that includes the accents your bot will encounter.
- Simulate Real-World Environments: The world is not a soundproof recording studio. Layering in realistic background noise (e.g., a coffee shop, a moving car, a crying baby) is critical for training a model that will not fail the moment it encounters a call from a noisy environment.
How Do You Avoid “Model Collapse”?
There is a potential long-term risk to relying solely on synthetic data. The phenomenon of “model collapse” is a major topic of research in the AI community.
- The Risk: If you train a new AI model only on data that was generated by a previous AI model, there is a risk that, over many generations, the models will start to forget the true diversity and nuance of real human speech. They can fall into a feedback loop where they only reinforce the patterns of their own creation.
- The Best Practice: A Hybrid Approach: The most effective and sustainable strategy is a hybrid one. Use synthetic data to solve the cold start problem and to augment your dataset. But as your voice bot starts to handle real calls, you should create a pipeline to collect, anonymize, and use this real-world data to continuously fine-tune and improve your models.
Also Read: How to Build Scalable Voice Calling Apps Using a Voice Calling SDK?
Conclusion
The data dilemma has long been the biggest barrier to building voice bots that are truly intelligent, robust, and reliable. The rise of sophisticated synthetic voice datasets has finally provided a powerful and accessible solution to this problem.
Synthetic data lets teams create large, high-quality, privacy-compliant datasets on demand. It solves the cold start problem, reduces bias, and builds bots resilient to real-world chaos.
The future of voice AI is hybrid. Synthetic data provides controlled precision, while real-world data offers ground truth. Together, they enable the next generation of conversational experiences.
Want to discuss how our robust voice infrastructure can support the real-time demands of your voice bot, no matter how its models are trained? Schedule a demo for FreJun Teler.
Also Read: Top 5 Cloud Telephony Providers Compared: Features, Pricing & Support
Frequently Asked Questions (FAQs)
The “cold start” problem occurs when a new voice bot lacks real call data; synthetic data lets you create a large training dataset from scratch.
No. High-quality synthetic voice datasets use structured designs and advanced AI to generate realistic, statistically representative real-world speech audio.
Realism comes from advanced TTS engines producing diverse voices and accents, plus realistic background noise to mimic real-world calls.
Synthetic data is useful, but hybrid approaches using real data for fine-tuning prevent long-term issues like model collapse.
Model collapse occurs when AI trained solely on AI-generated data drifts from real speech patterns; using real-world data for fine-tuning prevents it.
You can include audio with target accents in data generation, teaching your model to handle linguistic diversity effectively.
Though it needs powerful AI models, automated conversational dataset generation is far cheaper than manually collecting, transcribing, and labeling real call recordings.