
The Large Language Model (LLM) is the undisputed brain of the modern conversational AI revolution. It is a powerhouse of reasoning, knowledge, and language generation. But for all its intelligence, an LLM in its native state is deaf. It lives in a silent world of text and has no innate ability to understand the most natural form of human communication: the spoken word.
The technology that acts as the “ears” for this powerful brain, transcribing the chaotic, analog stream of a human voice into the clean, digital text an LLM can understand, is a voice recognition SDK.
But the role of a modern voice recognition SDK is far more sophisticated than just simple transcription. It is not a passive dictation machine; it is an active, intelligent, and highly optimizable component at the very start of the LLM audio pipelines. The way a developer implements and tunes this SDK has a profound and direct impact on the overall performance, speed, and even the intelligence of the entire voice-powered workflow.
This guide will explore the advanced capabilities of a modern SDK and how they can be leveraged to optimize your STT to LLM streaming for true real-time AI inference.
Table of contents
The Core Challenge: Bridging the “Audio-to-Thought” Gap
The journey from a spoken word to an intelligent AI response is a high-speed race against the clock. The very first leg of this race, the process of speech-to-text (STT) transcription is arguably the most critical. If this first step is slow, inaccurate, or lacks context, the entire downstream workflow is compromised. The core challenges are:
- Speed: The transcription must happen in near real-time. The LLM cannot start “thinking” until it receives the text. Any delay in the STT process is a direct addition to the overall latency of the AI’s response.
- Accuracy: The transcription must be as close to perfect as possible. A single misinterpreted word can completely change the meaning of a user’s request, leading the LLM down the wrong path and resulting in a nonsensical or incorrect answer.
- Context: Spoken language is full of ambiguity. Words like “four” and “for” sound the same. The name “Lisa” could be spelled multiple ways. The STT engine needs help to make the right choice.
A basic, out-of-the-box speech recognition service is often not good enough to solve these challenges in a production-grade application. This is where the advanced features of a high-quality voice recognition SDK become indispensable.
Also Read: How Long Does It Take to Go from Prototype to Production While Building Voice Bots?
How Does a Modern Voice Recognition SDK Optimize for Speed?
For real-time AI inference in a voice conversation, every millisecond counts. The goal is to get the transcribed text to the LLM as quickly as humanly possible, even while the user is still speaking.
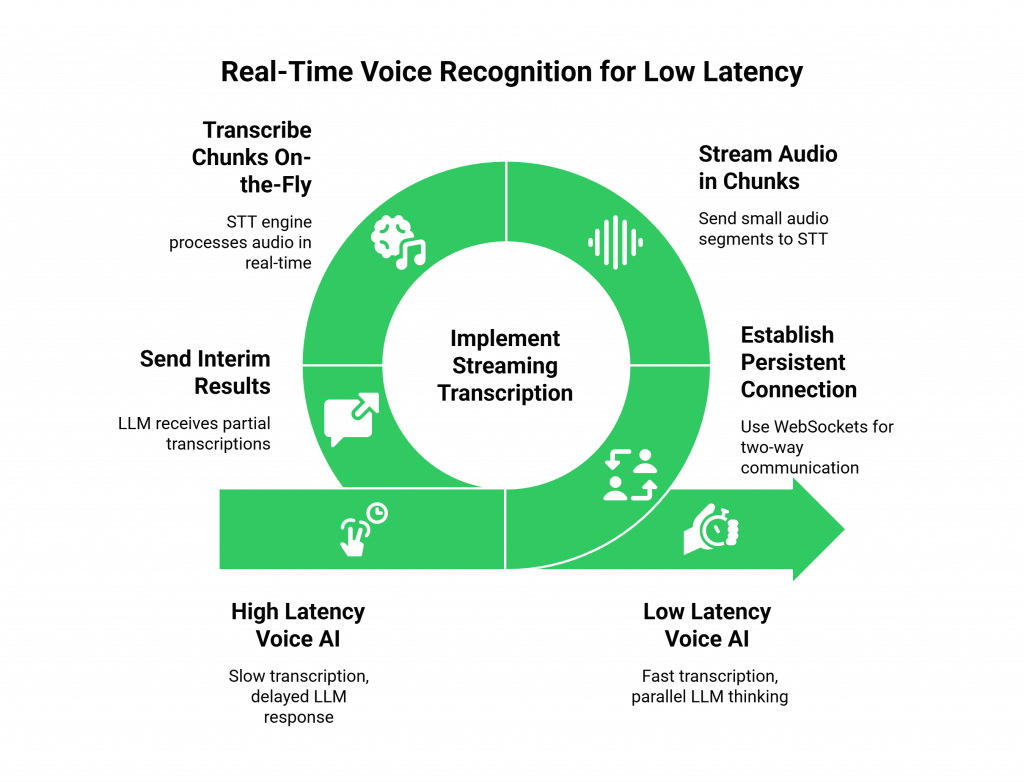
The Power of Real-Time, Streaming Transcription
This is the single most important feature for a low-latency voice AI.
- The Old Way (Batch Processing): A basic STT API would require you to record a full audio clip of the user’s speech, send the entire file to the server, and then wait for the full transcription to be returned. This adds a huge amount of latency, as the LLM has to wait until the user has completely finished speaking.
- The Modern Way (Streaming): A modern voice recognition SDK enables stt to llm streaming. It establishes a persistent, two-way connection (often using WebSockets) to the STT engine. As the user speaks, the SDK streams the audio data in small chunks. The STT engine transcribes these chunks on the fly and sends back a continuous stream of “interim” and “final” transcription results.
This streaming approach means application can start sending initial parts of user’s sentence to LLM while they are talking. It allows LLM to start its “thinking” process in parallel, which can shave hundreds of milliseconds off total response time.
How Does the SDK Optimize for Accuracy and Context?
A fast transcription is useless if it is wrong. A high-quality voice recognition SDK provides a set of powerful tools that allow a developer to “tune” the STT engine and provide it with the specific context it needs to be more accurate.
The Importance of “Speech Adaptation”
This is a set of features that allows you to give the STT model hints about the kind of language it is likely to hear. This is the key to creating context-aware audio processing.
- Phrase Hints: You can provide a list of specific words or phrases that are common in your domain. For example, if you are building a voice bot for a specific brand, you can provide a list of your unique product names (“Hyperion-7,” “Solara Pro”). This makes it much more likely that the STT will recognize these custom terms correctly.
- Model Boosting: Some advanced SDKs allow you to boost the probability of certain words appearing. It is incredibly useful for improving the recognition of proper nouns, like the names of people in your company directory.
- Custom Vocabularies: For highly specialized domains (like medical or legal), you can work with the provider to train a custom speech model. It specifically tuned to your industry’s unique jargon and terminology.
Also Read: How Can Building Voice Bots Improve Customer Experience Across Channels?
This table highlights how these features directly improve the quality of the data being fed into your LLM audio pipelines.
| SDK Feature | What It Does | Impact on Accuracy and Context |
| Real-Time Streaming | Transcribes audio on the fly as the user is speaking. | Reduces overall latency by enabling stt to llm streaming. |
| Phrase Hints & Boosting | Increases the recognition probability of specific words or phrases. | Dramatically improves the accuracy for proper nouns, brand names, and industry jargon. |
| Endpointing Configuration | Allows you to fine-tune the “end of speech” detection. | Prevents the STT from cutting the user off too early or waiting too long after they have finished speaking. |
| Noise-Robust Models | The ability to choose an STT model that is specifically trained for noisy environments. | Improves transcription accuracy for users who are on the go, in a car, or in a crowded place. |
Ready to build an AI that can not only hear but also understand the specific language of your business? Sign up for FreJun AI
How Does FreJun AI’s Architecture Support Optimized Recognition?
At FreJun AI, we understand that the voice recognition SDK is the critical first step in any high-performance voice workflow. Our platform is designed to provide the flexibility and the performance needed for the most demanding AI applications.
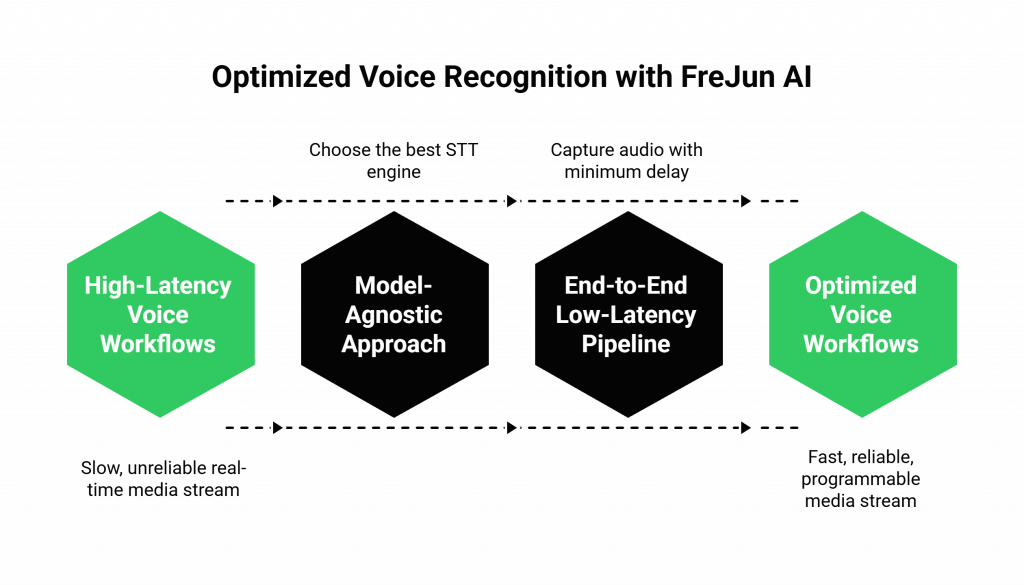
The Power of a Model-Agnostic Approach
Our voice infrastructure is completely model-agnostic. We believe that our job is to provide the fastest, most reliable, and most programmable real-time media stream, but that you should have the freedom to choose the absolute best STT engine for your specific use case.
- Flexibility: Our Real-Time Media API can be configured to stream the live audio from a phone call to any STT provider on the market, whether it is from a major cloud provider like Google or Microsoft, or a specialized startup with a model that is perfect for your industry.
- Future-Proofing: The world of speech recognition is evolving rapidly. Our model-agnostic approach means you can always upgrade to a new, more advanced STT engine in the future without ever having to change your core voice infrastructure.
An End-to-End Low-Latency Pipeline
We provide the foundational low-latency AI voice platform. Our globally distributed, edge-native Teler engine ensures that the initial audio stream is captured with the minimum possible delay. This high-quality, low-latency stream is then ready to be fed into your chosen STT engine, giving your entire LLM audio pipelines the best possible start. This is not just a feature; it is an architectural commitment.
A recent study on digital transformation found that companies that invest in a modern, API-first infrastructure are 2.5 times more likely to see a significant increase in customer satisfaction.
Also Read: What Monetization Strategies Work After Building Voice Bots for Businesses?
Conclusion
The voice recognition SDK is far more than a simple utility for transcription. In the world of modern voice AI, it is a strategic and highly optimizable component that plays a critical role in the overall performance and intelligence of your LLM-powered workflow.
By leveraging advanced features like real-time streaming and speech adaptation, and by building on a flexible, low-latency infrastructure, developers can transform the process of speech recognition from a potential bottleneck into a powerful enabler.
They can create a system that is not only faster and more accurate but also more context-aware, providing the LLM with the high-quality input it needs to truly shine.
Want to do a technical deep dive into how to build a low-latency, streaming STT to LLM pipeline on our platform? Schedule a demo for FreJun Teler.
Also Read: UK Mobile Code Guide for International Callers
Frequently Asked Questions (FAQs)
A voice recognition SDK (Software Development Kit) is a set of software libraries and tools that allows a developer to integrate speech-to-text (STT) capabilities into their own applications. It provides the “ears” for any voice-powered system.
LLM audio pipelines are the end-to-end workflows that process a spoken request and generate a spoken AI response. This typically includes the STT to transcribe the audio, the LLM to process the text, and the TTS to synthesize the audio response.
STT to LLM streaming is an advanced technique where the transcribed text from the STT engine is sent to the Large Language Model (LLM) in real-time, as the user is still speaking. This allows the LLM to begin its processing in parallel, which significantly reduces the overall response latency.
Real-time AI inference means that the AI’s “thinking” process happens almost instantaneously. For a voice conversation, this is critical. Any perceptible delay between a user speaking and the AI responding makes the interaction feel unnatural and robotic.
It enables context-aware audio processing by allowing the developer to provide “hints” to the STT engine. These hints, which can include a list of specific product names or industry jargon, make the transcription much more accurate for that specific conversational domain.
Batch processing requires you to send a complete audio file and wait for the full transcription. Streaming processing transcribes the audio on the fly as it is being spoken, providing a continuous stream of results, which is essential for low-latency applications.
With a model-agnostic platform like FreJun AI, yes. Our platform is designed to provide the real-time audio stream, and you are free to connect that stream to any STT provider you choose.