
For a developer, the classic voice API interaction is a familiar, predictable dance: the user speaks, the audio is processed, a response is sent, and the connection goes quiet. This turn-by-turn, request-response model is perfect for simple, transactional IVRs. But a new class of voice application is emerging, one that shatters this simple model. Imagine a real-time language translation service, an AI-powered therapy session that lasts for an hour, or a live transcription for a multi-person board meeting.
These are not a series of short, discrete turns; they are continuous, stateful, and often long running voice sessions. The traditional voice API, built on the stateless principles of the web, is simply not architected for this challenge.
The future of voice is not just about short commands; it is about extended, fluid, and uninterrupted conversations. To power these experiences, developers need a new kind of tool: a voice API for developers that is designed from the ground up to handle persistent audio streams.
This requires a fundamental architectural shift, moving from a stateless, request-response model to a stateful, streaming model. This is the core capability of a true real time conversation API, and it is the key to unlocking the next generation of immersive and sophisticated voice applications.
Table of contents
What is the Difference Between a “Turn” and a “Session”?
To understand the architectural challenge, we must first define our terms. The difference between a traditional, turn-based interaction and a continuous voice session is profound.
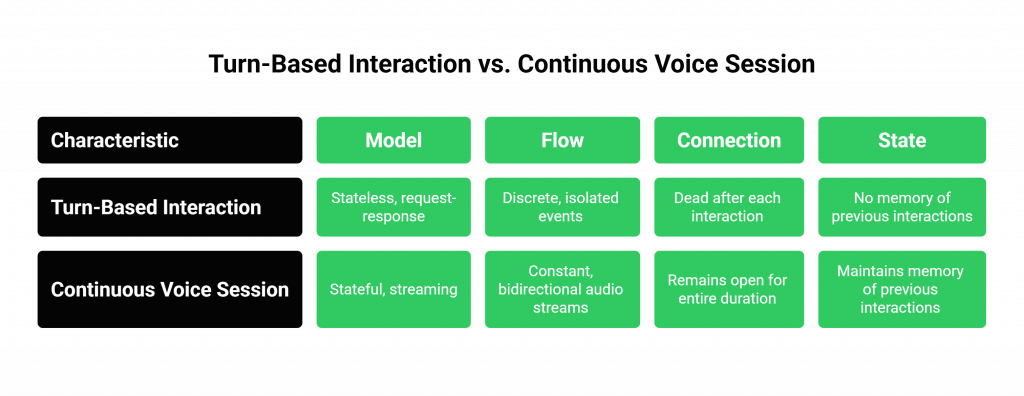
The Old Model: The Turn-Based Interaction
Think of a classic IVR.
- The Model: This is a stateless, request-response model, much like a traditional web server.
- The Flow: The user speaks a command. The platform captures that audio, processes it, and then sends a notification (a webhook) to your application. Your application sends back a command. The platform executes it. The connection is then effectively “dead” until the user speaks again.
- The Analogy: It is like a series of text messages. Each message is a separate, isolated event.
The New Model: The Continuous Voice Session
Now, think of a live, simultaneous language interpretation app.
- The Model: This is a stateful, streaming model.
- The Flow: The connection is established once at the beginning of the call and remains open for the entire duration. There is a constant, bidirectional flow of persistent audio streams. Audio from all parties is continuously flowing to your application for processing, and your application is continuously sending back the translated audio.
- The Analogy: It is like an open phone line or a live radio broadcast. The channel is always on.
This is the key distinction. Long running voice sessions are not a series of discrete events; they are a single, continuous, stateful event. The demand for such real-time capabilities is exploding, with the global real-time communication market projected to reach over $45 billion by 2027, driven by these advanced, session-based applications.
Also Read: Can A Smarter Voice Recognition SDK Improve App Experience?
Why Do Traditional, REST-Based Voice APIs Fail at This?
The traditional voice API for developers, which is often based purely on the request-response model of RESTful APIs and webhooks, struggles mightily with the demands of a continuous session.

- The Inefficiency of HTTP: The HTTP protocol was not designed for continuous, real-time streaming. Trying to use it for this purpose (e.g., through techniques like long polling) is incredibly inefficient. It involves a high overhead of repeatedly setting up and tearing down connections for tiny chunks of data.
- The Latency Penalty: This constant connection overhead adds a significant amount of latency at every single step. This might be acceptable for a slow, turn-by-turn IVR, but it makes a truly real-time, fluid conversation completely impossible.
- The Half-Duplex Problem: The request-response model is inherently “half-duplex.” You are either sending a request or receiving a response. It is very difficult to create a truly “full-duplex” experience, where your application can be receiving the user’s audio at the exact same moment it is sending the AI’s audio, which is essential for natural interruption (barge-in).
The Architectural Solution: WebSockets and a Stateful Media Core
To solve these problems, a modern voice API for developers must be built on a different architectural foundation. It needs a mechanism for persistent, bidirectional communication and a core infrastructure that is designed to manage the state of these long-lived connections.
The Central Role of the WebSocket API
The WebSocket protocol is the technical heart of the solution.
- What It Is: A WebSocket is a communication protocol that provides a full-duplex, persistent communication channel over a single TCP connection.
- How It Works: Your application uses the voice API to instruct the provider’s media server to establish a WebSocket connection to your application server. Once this “tunnel” is established, it stays open. The voice platform can then stream the persistent audio streams from the call directly to your application with ultra-low latency, and your application can stream its own audio back up the same tunnel.
Also Read: Why Use a Voice Recognition SDK for High Volume Audio Processing
The Need for a Resilient, Stateful Infrastructure
Managing tens of thousands of these persistent WebSocket connections is a massive engineering challenge. It requires a voice streaming engine that is:
- Stateful by Design: The provider’s media servers must be able to maintain the state of each of these long running voice sessions.
- Highly Available and Fault-Tolerant: What happens if a single media server that is managing a thousand live sessions fails? A carrier-grade platform like FreJun AI’s Teler engine is built with multiple layers of redundancy. It is designed to detect such failures and, where possible, seamlessly migrate sessions to a healthy server with minimal disruption to the end-user. The importance of this reliability cannot be overstated.
This table provides a clear comparison of the two architectural models.
| Characteristic | Stateless (REST/Webhook) Model | Stateful (WebSocket) Model for Continuous Sessions |
| Connection Model | A new, temporary connection for each turn. | A single, persistent connection for the entire session. |
| Data Flow | Half-duplex (request or response). | Full-duplex (sending and receiving simultaneously). |
| Latency | Higher, due to repeated connection overhead. | Ultra-low, with minimal overhead after the initial handshake. |
| Suitability for Long Sessions | Poor. Inefficient and not truly real-time. | Excellent. Designed specifically for long running voice sessions. |
| Architectural Complexity | Simpler for basic, turn-by-turn applications. | More complex, but essential for any advanced, real-time application. |
Ready to build applications that can handle long, complex, and continuous conversations? Sign up for FreJun AI
Also Read: Modern Voice Recognition SDK Supporting Multilingual Apps
Conclusion
The evolution of the voice API for developers is a story of moving from the stateless simplicity of the web to the stateful complexity of real-time communication. While the traditional, request-response model was sufficient for the first generation of simple voice applications, the future belongs to continuous, immersive, and long-running conversational experiences. This new class of application demands a new class of infrastructure.
A true real time conversation API, built on the power of WebSockets and a resilient, stateful media core, is the essential enabling technology for this future. It is the key that unlocks the door to building the next generation of long running voice sessions, from simultaneous translation to deep, conversational AI.
Want to do a deep dive into our WebSocket API and the architecture of our stateful media engine? Schedule a demo for FreJun Teler.
Also Read: AI-Powered IVR Software: The Future of Call Automation
Frequently Asked Questions (FAQs)
It is a live phone call that maintains a single, persistent connection for an extended period, allowing for a continuous, uninterrupted flow of audio data.
Persistent audio streams refer to the constant, real-time flow of audio data to and from an application over a dedicated connection, like a WebSocket, for the entire duration of a call.
A real time conversation api is a voice API that is specifically designed to handle the demands of live, interactive dialogues, with a focus on low latency and stateful session management.
A REST API is stateless and has high overhead for each request, making it too slow and inefficient for the continuous data flow of long running voice sessions.
The main advantage is that they provide a persistent, low-latency, and bidirectional communication channel, which is perfect for streaming real-time audio.
A stateful system is one that “remembers” the context and history of an ongoing interaction. A continuous voice session is stateful, while a simple web request is stateless.
Yes. Because a WebSocket is full-duplex, your application can receive the user’s audio (they are interrupting) at the exact same moment it is sending the AI’s audio.