
You have built an intelligent AI powered by a Large Language Model, but it can’t speak to users on a phone call. Why? Because turning that smart, text-based bot into a real-time voice assistant is incredibly hard. It involves audio streaming, latency control, and complex telephony infrastructure. That’s where most teams get stuck. This full-stack guide walks you through every layer of voice bot integration, from architecture and APIs to common pitfalls, and shows how platforms like FreJun AI make it possible to launch reliable, scalable voice AI in production.
Table of contents
- The Core Architecture of a Modern Voice Bot
- Why Piecemeal Voice Solutions Fall Short for AI?
- A Step-by-Step Guide to Building Your Voice Bot
- The Technology Stack: Key Tools and APIs for 2025
- FreJun vs. Building From Scratch: A Head-to-Head Comparison
- Best Practices for a Seamless Conversational Experience
- Key Challenges in Voice Integration and How to Overcome Them
- Final Thoughts: The Strategic Value of Robust Voice Infrastructure
- Frequently Asked Questions (FAQs)
The Core Architecture of a Modern Voice Bot
A production-grade voice bot is not a single piece of software. It’s a sophisticated ecosystem of interconnected services working in harmony to create a seamless, real-time conversation. A failure or delay in any single component can break the entire experience. The architecture involves multiple layers:
- Voice Transport Layer: This is the foundation. It’s the “plumbing” responsible for capturing audio from a phone call and streaming it to your services, then taking the generated audio response and streaming it back to the caller. For this to work, the transport layer must be exceptionally fast, reliable, and capable of handling real-time, low-latency media streaming.
- Speech-to-Text (STT) Service: Once the raw audio is captured, it’s sent to an STT engine (like Google Speech-to-Text or Azure) to be transcribed into text. The accuracy of this service, especially with accents and background noise, is critical.
- AI/LLM Core Logic: The transcribed text is then sent to your backend, which forwards it to your chosen Large Language Model (e.g., OpenAI, Anthropic). This is the “brain” of your operation. Your backend application maintains the conversational context, manages the dialogue state, and orchestrates the flow of information.
- Text-to-Speech (TTS) Service: The LLM generates a text-based response. This text is then sent to a TTS engine (like ElevenLabs) to synthesize it into natural-sounding audio. The quality of the TTS voice greatly impacts the user experience.
- Return to Transport Layer: The synthesized audio is piped back to the voice transport layer, which plays it back to the user over the phone call, completing the conversational loop.
Your backend application sits in the middle of this, acting as the conductor for this complex orchestra. It must manage session context, handle errors, and ensure each step happens with minimal delay.
Why Piecemeal Voice Solutions Fall Short for AI?
Many development teams initially attempt to build their voice infrastructure from the ground up, stitching together various APIs and open-source telephony projects. While this approach might work for a simple proof-of-concept, it rarely scales to a production-grade, enterprise-ready solution.

Here’s why this DIY approach is often inefficient and costly:
- High Latency: The biggest killer of a natural conversation is delay. Juggling raw audio streams, managing telephony protocols (like SIP), and ensuring near-instantaneous data transfer between your servers and the telecom network is a specialized engineering discipline. Every millisecond of delay you introduce creates awkward pauses that make your AI bot feel slow and unintelligent.
- Infrastructure Complexity: Telephony is a world of its own, filled with complex protocols, carrier negotiations, and regulatory hurdles. Building and maintaining a resilient, geographically distributed infrastructure that guarantees uptime is a massive undertaking that distracts your team from focusing on the core AI logic.
- Scalability Issues: Handling a handful of concurrent calls is one thing. Scaling to hundreds or thousands without a drop in quality or reliability requires robust, load-balanced architecture that is expensive to build and maintain.
- Lack of Developer-First Tooling: Generic telephony APIs are not designed for the specific needs of AI bot voice integration. They lack the SDKs and event-driven frameworks needed to easily manage real-time voice streams and integrate them into a modern AI stack.
This is where a dedicated voice transport platform like FreJun becomes a strategic advantage. FreJun handles the complex voice infrastructure, the low-latency streaming, the call management, the enterprise-grade reliability, so you can focus exclusively on building and refining your AI’s intelligence.
Also Read: US VoIP Number Implementation for International Trade in Saudi Arabia
A Step-by-Step Guide to Building Your Voice Bot
With a platform like FreJun managing the telephony, the process of implementing AI bot voice integration becomes dramatically simpler. The workflow is streamlined into a clear, manageable pipeline.
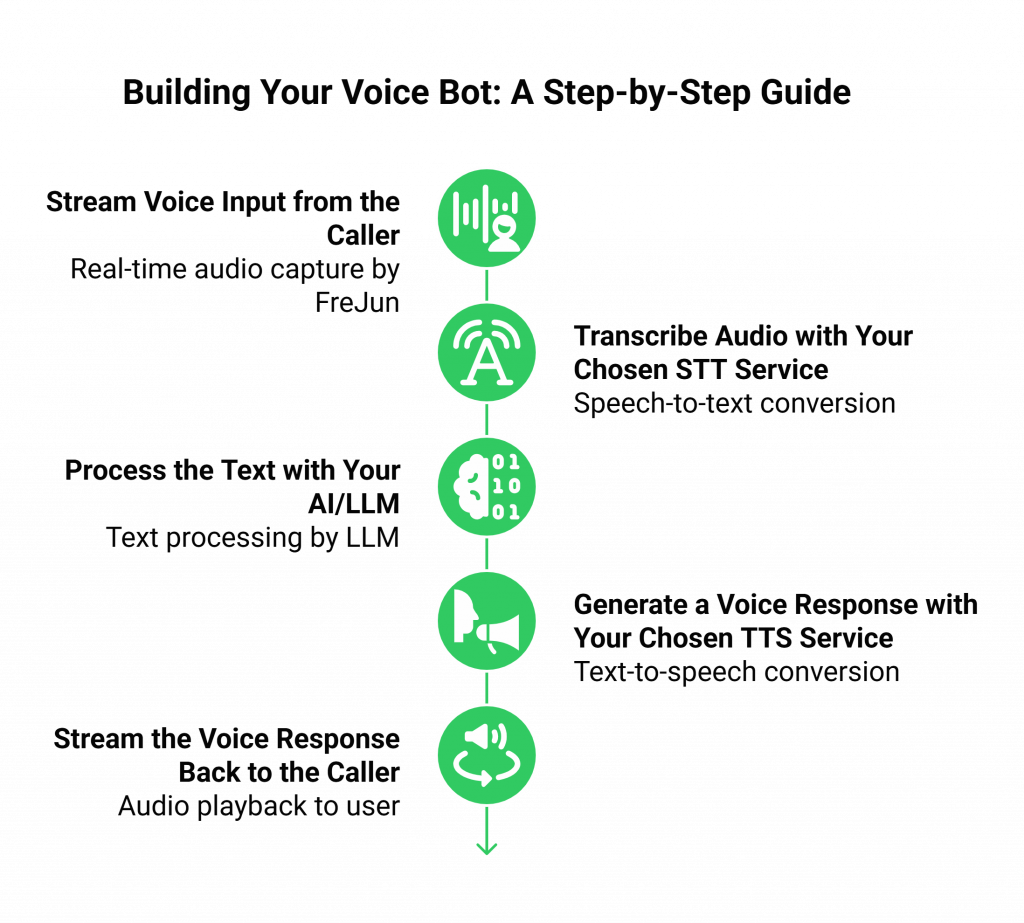
Here is the step-by-step process:
Step 1: Stream Voice Input from the Caller
When a user calls your FreJun-provisioned number, the FreJun API immediately captures the real-time audio stream. Instead of you having to deal with complex telephony protocols, FreJun delivers a clean, low-latency stream of raw audio data directly to your application via a WebSocket or another real-time protocol.
Step 2: Transcribe Audio with Your Chosen STT Service
Your backend application receives this raw audio stream. You then pipe this audio data to your preferred third-party Speech-to-Text (STT) provider (e.g., Google, Azure, Amazon Transcribe). The STT service transcribes the speech into text and returns it to your application.
Step 3: Process the Text with Your AI/LLM
With the transcribed text in hand, your application now has a standard input to work with. You forward this text to your Large Language Model. Your application maintains full control over the dialogue state, allowing you to enrich the prompt with conversational history, customer data from a CRM, or information from other internal APIs before sending it to the LLM.
Step 4: Generate a Voice Response with Your Chosen TTS Service
The LLM generates a text response. Your backend takes this text and sends it to your preferred Text-to-Speech (TTS) service (e.g., ElevenLabs). The TTS service converts the text into a high-quality, natural-sounding audio file or stream.
Step 5: Stream the Voice Response Back to the Caller
Your application pipes the synthesized audio from the TTS service directly to the FreJun API. FreJun handles the final step of playing this audio back to the user over the phone call with minimal latency, completing the conversational loop and preparing for the user’s next response.
This modular approach gives you complete freedom to choose the best STT, LLM, and TTS services for your needs while offloading the complex, real-time voice infrastructure to a specialized platform.
The Technology Stack: Key Tools and APIs for 2025
Building a full-stack voice bot requires a combination of modern technologies. Here is a typical stack you might use:
- Voice Transport Layer: FreJun AI for handling inbound and outbound phone calls, managing real-time audio streams with low latency, and providing developer-first SDKs.
- Backend Framework: Node.js/Express or Python/FastAPI are excellent choices for building the backend orchestration layer due to their strong performance with I/O operations and robust ecosystems.
- AI/LLM Services: OpenAI (GPT-4), Anthropic (Claude), or open-source models for handling the core conversational logic and intelligence.
- Speech-to-Text (STT) APIs: Google Cloud Speech-to-Text, Azure Cognitive Services, or Amazon Transcribe for accurate and fast transcription.
- Text-to-Speech (TTS) APIs: ElevenLabs, Google Cloud Text-to-Speech, or Azure TTS for generating human-like, natural-sounding voice responses.
- Frontend (for Web-Based Bots): React or Next.js for building any associated web interfaces, such as a dashboard for monitoring conversations or a chat UI for hybrid text-voice bots.
FreJun vs. Building From Scratch: A Head-to-Head Comparison
Choosing the right foundation for your AI bot voice integration is a critical decision. Here’s how using a specialized platform like FreJun compares to building your voice infrastructure from the ground up.
| Feature | Building From Scratch (DIY Approach) | Using FreJun’s Voice Transport Layer |
| Primary Focus | Managing telephony, SIP trunks, latency, and raw audio protocols. | Building and perfecting your AI’s conversational logic. |
| Time to Market | Months or longer. High development overhead for infrastructure. | Days or weeks. Launch sophisticated voice agents quickly. |
| Latency | A constant battle. Requires deep optimization across the entire stack. | Engineered for low latency. Entire stack is optimized for speed. |
| Scalability | Difficult and expensive. Requires significant investment in infrastructure. | Built on resilient, geographically distributed infrastructure for high availability. |
| Reliability | Prone to single points of failure. Uptime is a constant concern. | Enterprise-grade reliability with guaranteed uptime. |
| Developer Experience | Working with low-level, generic telephony APIs. | Developer-first SDKs and a model-agnostic API designed for AI integration. |
| Support | You are on your own. | Dedicated integration support from pre-planning to post-launch optimization. |
Also Read: CRM Calling vs. Traditional Calling: Which Delivers Better ROI?
Best Practices for a Seamless Conversational Experience
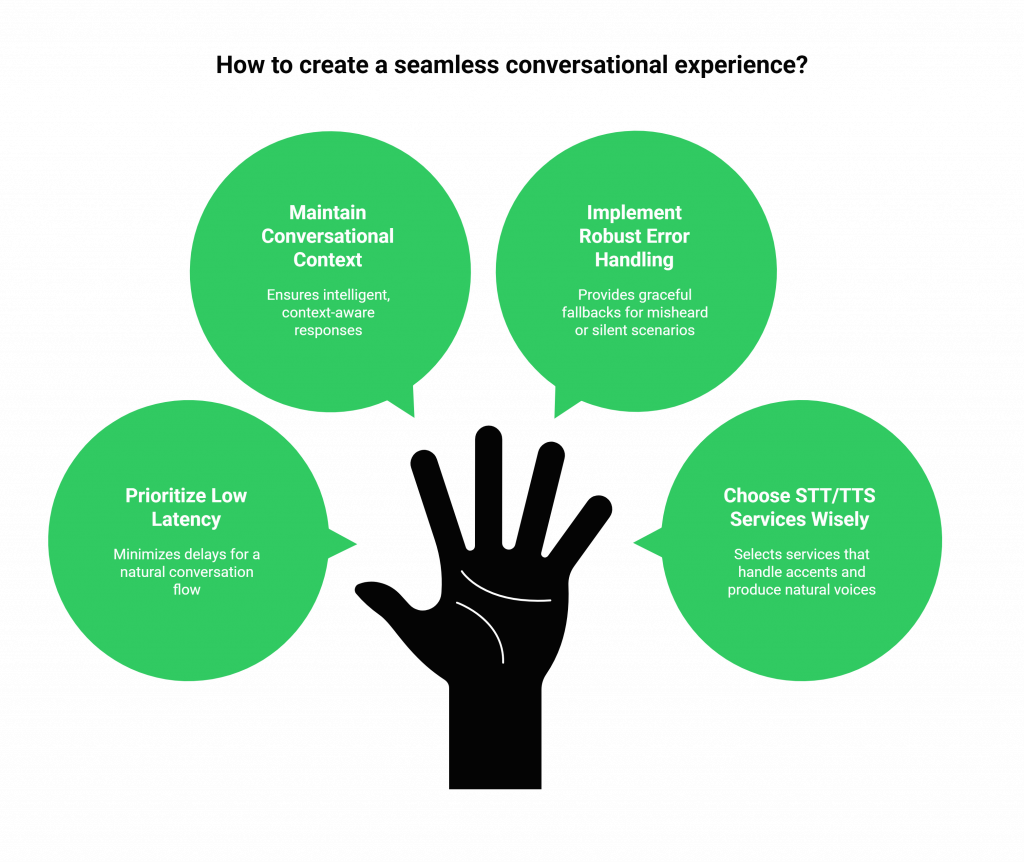
A technically functional voice bot is not enough. The goal is to create an experience that feels natural and fluid. Here are some best practices to follow:
- Prioritize Low Latency Above All: The human ear is incredibly sensitive to delays in conversation. Your entire architecture must be optimized to minimize the time between the user finishing their sentence and your bot beginning its response. This is a core benefit of using a platform like FreJun, which is engineered specifically for speed.
- Maintain Full Conversational Context: Your backend application should act as the single source of truth for the conversation’s state. By using FreJun as a reliable transport layer, your backend can independently track the dialogue, allowing for more intelligent, context-aware responses from your LLM.
- Implement Robust Error Handling: What happens if the STT service mishears something? Or if the user doesn’t say anything? Your application needs graceful fallbacks for these scenarios, such as asking the user to repeat themselves or offering a different prompt.
- Choose Your STT/TTS Services Wisely: The quality of your STT and TTS providers will directly impact the user experience. Test different services to find the ones that best handle your target accents and produce the most natural-sounding voice for your brand. Because FreJun is model-agnostic, you have the freedom to choose and switch providers as needed.
Key Challenges in Voice Integration and How to Overcome Them
Every AI bot voice integration project will face challenges. Being aware of them is the first step to solving them.
Challenge: Background Noise and Accents
Solution: Choose a high-quality, AI-powered STT service trained on diverse datasets. Additionally, your application logic can include prompts that ask for clarification if the transcription confidence score is low.
Challenge: Ensuring Low Latency
Solution: This is primarily an infrastructure challenge. Instead of trying to solve it yourself, leverage a platform like FreJun that has already engineered its entire stack for real-time media streaming and minimal delay. This is the single most effective way to solve the latency problem.
Challenge: Maintaining Data Privacy and Compliance
Solution: Ensure every component in your stack is compliant with relevant regulations (like GDPR). Work with a voice provider like FreJun that builds security and data protection into every layer of its platform and has clear protocols for handling sensitive data.
Challenge: Managing Conversational Flow
Solution: Use conversation design tools to map out interactions. Your backend logic should be responsible for state management, ensuring the bot remembers the context of the conversation from one turn to the next.
Final Thoughts: The Strategic Value of Robust Voice Infrastructure
Ultimately, the goal of AI bot voice integration is not just to make your AI talk. It’s to deploy a sophisticated, reliable, and scalable voice agent that can handle critical business functions, from 24/7 customer support to proactive outbound sales.
Trying to build the underlying voice infrastructure yourself is a strategic misstep. It pulls your most valuable engineering talent away from your core product, the AI itself, and forces them to become amateur telecom engineers. The path to a successful, production-grade voice agent is not to rebuild the plumbing, but to choose the best pipes.
FreJun provides that robust, enterprise-grade plumbing. Our platform is designed to handle all the complexities of real-time voice, offering a reliable and low-latency transport layer that lets your AI shine. With developer-first SDKs and dedicated integration support, we empower you to launch powerful voice agents in a fraction of the time, giving you a critical advantage in a competitive market. Don’t let infrastructure be your bottleneck; let it be your foundation for success.
Further Reading: Stream Voice to a Chatbot Speech Recognition Engine via API
Frequently Asked Questions (FAQs)
A voice transport layer, like FreJun, specializes in one thing: managing the real-time, low-latency streaming of audio for phone calls. We handle the complex telephony infrastructure. This is different from an all-in-one platform that might bundle STT, TTS, and a proprietary LLM.
No. FreJun is a “Bring Your Own AI” platform. We provide the critical infrastructure to connect your phone calls to your chosen services. Our customers bring their own STT, LLM, and TTS providers, giving them full control over their AI logic, cost, and performance.
Low latency is achieved through optimization at every step of the process. This starts with a voice platform like FreJun, which is built on geographically distributed infrastructure engineered for real-time media streaming. It also involves choosing fast, responsive STT, LLM, and TTS API providers and ensuring your backend orchestration code is highly efficient.
Before writing any code, the first step should always be conversation design. Use a tool like Voiceflow to map out the user’s journey, define the bot’s purpose, write sample dialogue, and plan for various user inputs and potential errors.
This is primarily a function of the Speech-to-Text (STT) service you choose. Leading providers use advanced AI models trained on vast and diverse datasets to improve accuracy with various accents and filter out background noise. Your application can also be designed to ask for clarification if the STT service returns a transcription with a low confidence score.