
Developers building conversational AI in 2025 know that voice is more than a feature, it is the entire user experience. ElevenLabs.io and Deepgram.com often emerge as top choices, but they solve different challenges. ElevenLabs brings unmatched realism to synthetic voices, while Deepgram ensures lightning-fast, accurate transcription. They are not rivals, but complementary pillars of a conversational stack.
Yet, both rely on something easily overlooked: a rock-solid voice transport layer. That’s where FreJun comes in, making these powerful APIs production-ready.
Table of contents
- The Two Sides of the Conversational Coin
- The Real Bottleneck in Voice AI: Beyond the APIs
- ElevenLabs.io: The Gold Standard for Voice Generation (TTS)
- Deepgram.com: The Engine for Speech Recognition (ASR)
- Head-to-Head: Elevenlabs.io Vs Deepgram.com Breakdown
- The Missing Piece: The Voice Transport Layer
- DIY Stack vs. FreJun AI: A Strategic Comparison
- How to Build the Ultimate Voice Agent Stack in 2025?
- Final Thoughts: Build Your AI, Not Your Telephony Stack
- Frequently Asked Questions
The Two Sides of the Conversational Coin
For developers building conversational AI in 2025, the toolkit has become incredibly specialised and powerful. The goal is no longer just to make an AI talk, but to create seamless, real-time, human-like interactions. This has led to a critical evaluation of the core components of the voice stack, often crystallising in the Elevenlabs.io Vs Deepgram.com debate.
On one side stands ElevenLabs, the undisputed leader in ultra-realistic Text-to-Speech (TTS) and expressive voice generation. On the other is Deepgram, a dominant force in high-speed, high-accuracy Automated Speech Recognition (ASR). Developers often find themselves comparing these two platforms, but the analysis reveals a crucial truth: they are not direct competitors. They are two essential, complementary sides of the same conversational coin.
This guide will dissect the unique strengths of each platform to help you understand where they fit in a modern developer’s stack. More importantly, it will expose the foundational layer that both platforms require to function effectively in a real-world telephony environment, the voice transport layer.
Also Read: How to Build a Voice Bot Using Gemma 1.1 for Customer Support?
The Real Bottleneck in Voice AI: Beyond the APIs
A common mistake for development teams is to focus solely on the “brain” (the LLM), the “mouth” (TTS), and the “ears” (ASR) of their AI agent. They select best-in-class APIs from providers like ElevenLabs and Deepgram, stitch them together, and expect a fluid conversation.
The reality is that the most significant challenge lies in the “nervous system”—the real-time, bidirectional audio stream that connects the user to the AI over a phone line. Building this layer yourself is a recipe for failure, plagued by issues that have nothing to do with the quality of your AI models:
- Compound Latency: A user speaks. The audio travels over the phone network, hits your server, gets sent to Deepgram’s API for transcription, the text goes to your LLM, the response text goes to ElevenLabs’ API for synthesis, and the generated audio finally travels back over the network to the user. Even with sub-300ms transcription and 75ms synthesis, the cumulative network and processing delays create awkward, conversation-killing pauses.
- Degraded Audio Quality: Real-world phone calls are not pristine studio recordings. Jitter, packet loss, and background noise can corrupt the audio stream before it ever reaches your ASR, leading to inaccurate transcriptions and nonsensical AI responses.
- Infrastructure Management Hell: Instead of refining conversational logic, your engineers are dragged into the world of telephony. They are forced to manage complex SIP trunks, debug carrier issues, and build redundant systems just to ensure basic call connectivity, wasting valuable time and resources.
A brilliant AI is useless if it can’t communicate clearly and instantly. This is why a dedicated, low-latency voice transport layer is not a luxury; it’s a necessity.
ElevenLabs.io: The Gold Standard for Voice Generation (TTS)
ElevenLabs has earned its reputation by focusing on one thing: creating the most lifelike and emotionally resonant synthetic voices on the market. It is the definitive choice for developers who need to generate high-quality audio output.
Key Strengths and Features
- Unmatched Voice Realism: The platform excels at generating ultra-realistic speech with expressive, emotional delivery. Its technology is perfect for applications where the quality of the voice is a core part of the user experience.
- Advanced Creative Control: Developers have access to a rich set of tools, including a vast voice library, state-of-the-art voice cloning, and expressive tags to control emotion and pacing.
- Low-Latency Synthesis: With models like Flash, ElevenLabs can generate audio in approximately 75ms, making it suitable for real-time conversational applications.
- Comprehensive Developer Toolkit: Backed by significant funding, the company provides robust APIs and SDKs for building everything from conversational agents to AI-powered media dubbing and audiobook narration.
Ideal Use Cases
ElevenLabs is the go-to platform when your primary focus is on high-quality voice generation. This includes:
- Creating branded voice experiences for AI assistants.
- Narrating audiobooks and other storytelling applications.
- Enhancing media with realistic, multi-lingual dubbing.
- Any application where emotional nuance and vocal quality are critical.
Also Read: Virtual Number Setup for B2B Communication with WhatsApp Business in Thailand
Deepgram.com: The Engine for Speech Recognition (ASR)
Deepgram has carved out its leadership position by focusing on the other side of the conversation: understanding human speech with incredible speed and accuracy. It is the premier choice for developers who need to turn spoken words into usable data.
Key Strengths and Features
- Exceptional Speed and Accuracy: Deepgram is engineered for real-time use cases, offering both streaming and batch transcription with sub-300ms latency and high accuracy.
- Enterprise-Grade and Cost-Effective: The platform is HIPAA compliant and significantly more affordable than competitors, making it a scalable choice for businesses. The Aura-2 model, for example, is around 40% less expensive than ElevenLabs Flash.
- Powerful Developer APIs: It provides a rich feature set, including speaker diarization (telling who spoke when), word-level timestamps, sentiment analysis, and profanity filtering.
- Flexible Deployment: Developers have the option to use Deepgram’s cloud or deploy it on-premises, offering greater control over data and infrastructure.
Ideal Use Cases
Deepgram is the superior choice when your primary need is fast and accurate speech recognition. This includes:
- Real-time transcription for call centers and virtual meetings.
- Building voice-controlled applications and workflows.
- Performing speech analytics to gain insights from call data.
- Any application that relies on processing voice data at scale.
Head-to-Head: Elevenlabs.io Vs Deepgram.com Breakdown
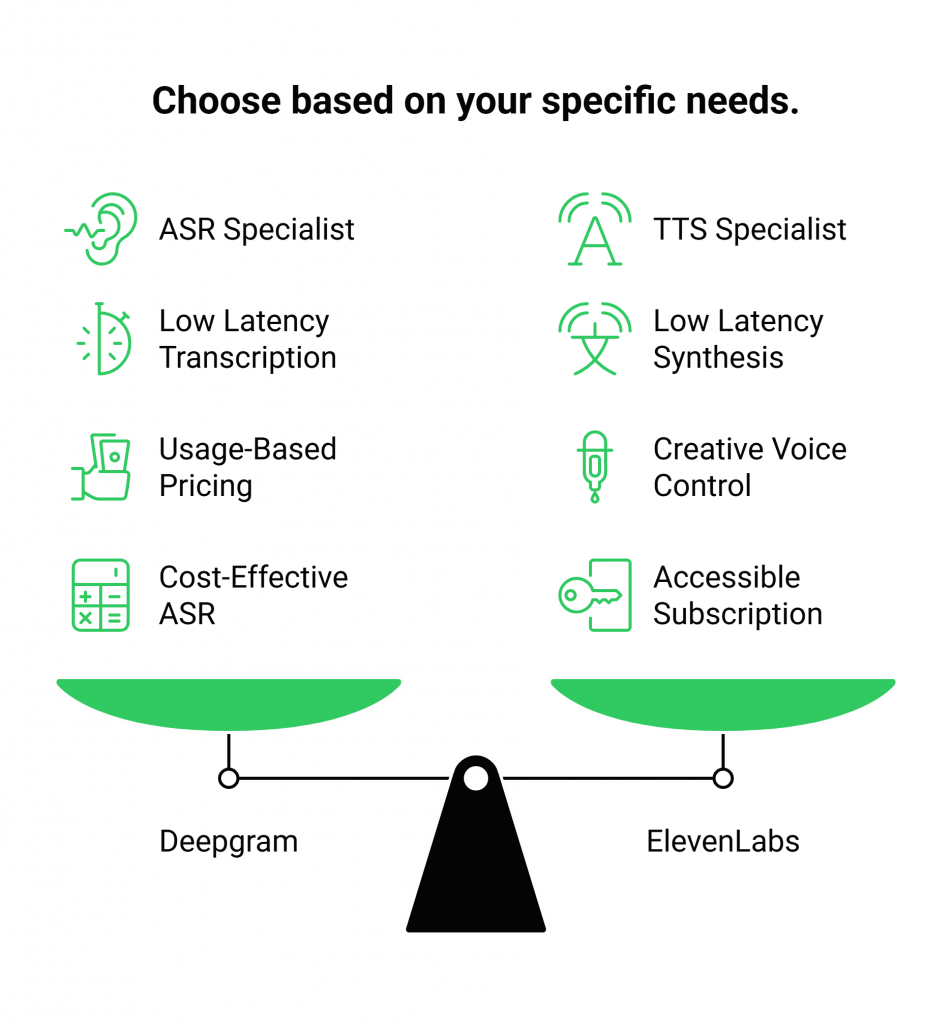
This comparison highlights that the two platforms are specialists in different, complementary domains.
Core Functionality: ASR vs. TTS
Winner: Not Applicable
This is the central point of the Elevenlabs.io Vs Deepgram.com analysis. Deepgram is an ASR platform; its job is to listen. ElevenLabs is primarily a TTS platform; its job is to speak. They are not competitors; they are partners in a conversation.
Performance and Speed
Winner: Both are excellent in their domain.
Deepgram delivers industry-leading sub-300ms latency for transcription. ElevenLabs offers its own low-latency synthesis with its Flash model. Both are engineered for the real-time demands of conversational AI.
Developer Experience
Winner: Both are developer-first.
Both platforms provide robust, well-documented APIs and SDKs designed for easy integration. Deepgram offers clear, usage-based pricing and flexible deployment options. ElevenLabs provides powerful tools for creative voice control and a simple subscription model.
Cost-Effectiveness
Winner: It depends on the use case.
Deepgram’s ASR is highly cost-effective, with per-minute rates that are significantly lower than many competitors. ElevenLabs’ subscription model is accessible for getting started. The best choice depends entirely on whether your application is transcription-heavy or synthesis-heavy.
Also Read: Gemma 2 Voice Bot Tutorial: Automating Calls
The Missing Piece: The Voice Transport Layer
You have chosen the best-in-class “ears” (Deepgram) and the best-in-class “mouth” (ElevenLabs). Now, how do you reliably connect them to a user over a phone call in real-time?
This is the infrastructure gap that FreJun AI was built to solve.
FreJun is a developer-first voice transport layer. We handle all the complex, mission-critical voice infrastructure, allowing your best-in-class AI components to work together seamlessly.
- How FreJun Orchestrates the Conversation: Our API captures a crystal-clear, low-latency audio stream from any phone call. This stream is sent to your application, which can then forward it to Deepgram for transcription. Your app takes the transcribed text, sends it to your LLM for a response, and then sends that response text to ElevenLabs for synthesis. The generated audio is piped back to the FreJun API, which plays it to the user instantly, completing the conversational loop with minimal delay.
We provide the bulletproof “plumbing” that turns a collection of powerful APIs into a fluid, functional voice agent.
DIY Stack vs. FreJun AI: A Strategic Comparison
Building your voice infrastructure is a strategic error that drains resources and delays your go-to-market. Here’s how a DIY approach compares to building on the FreJun AI transport layer.
| Feature / Aspect | The DIY Stack (Deepgram + ElevenLabs + Telephony API) | The FreJun AI Transport Layer |
| Infrastructure Management | You must integrate and manage separate APIs for telephony, ASR, and TTS. Complex and fragile. | Unified API for all voice transport. We provide the seamless connection between the phone network and your AI stack. |
| Latency and Performance | Latency is unpredictable and compounds across each service. Prone to network jitter and packet loss. | Engineered end-to-end for minimal transport latency. Our global infrastructure ensures a clear, real-time audio stream. |
| Scalability and Reliability | You are responsible for building, scaling, and maintaining a redundant telephony system. High operational overhead. | Built on a resilient, geographically distributed infrastructure designed for 99.99% uptime and enterprise-scale traffic. |
| Developer Focus | Engineers waste time troubleshooting call connectivity instead of improving the AI’s conversational intelligence. | Developers focus 100% on their core application logic. We handle all the complexities of voice communication. |
| Support | Siloed support from multiple vendors who cannot see your entire technology stack. | Dedicated integration support from voice infrastructure experts who help ensure your end-to-end solution works perfectly. |
Also Read: Remote Team Communication Using Softphones for Business Success in Switzerland
How to Build the Ultimate Voice Agent Stack in 2025?
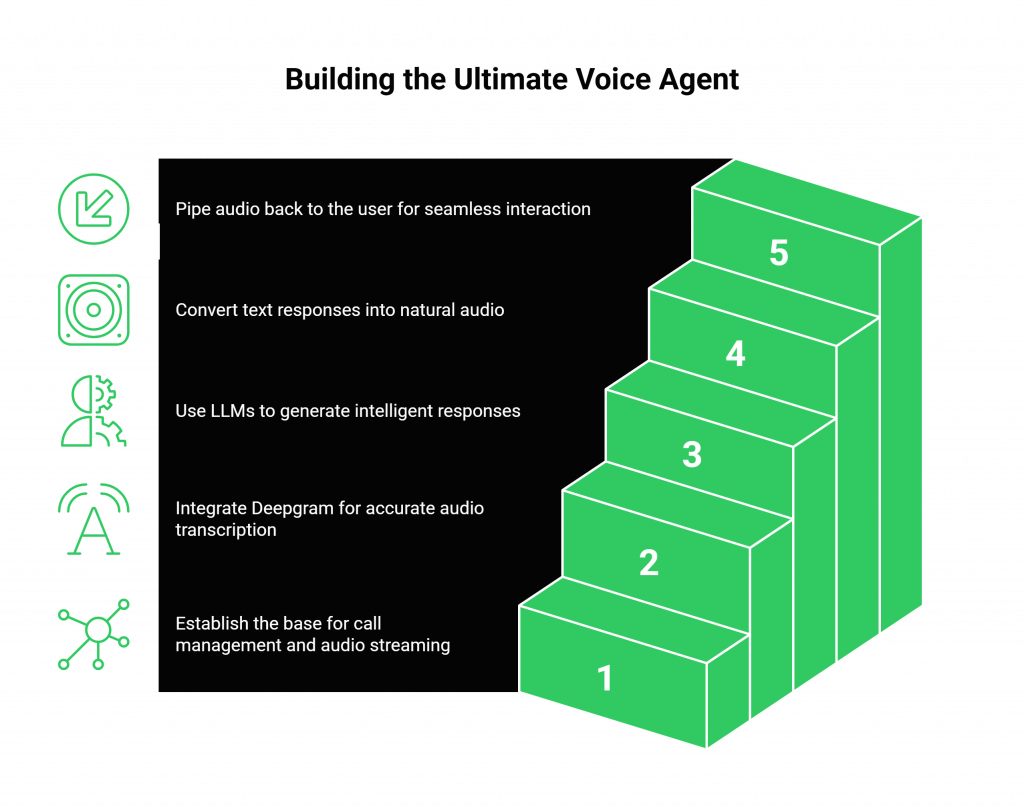
By embracing a modular, best-of-breed approach, you can build a voice agent that is superior to any single all-in-one solution.
- Step 1: The Foundation (Transport Layer). Start with FreJun AI. Use our simple APIs and SDKs to handle all inbound and outbound call management and real-time audio streaming.
- Step 2: The Ears (ASR Layer). Integrate Deepgram. Pipe the live audio stream from FreJun to Deepgram’s API for fast, accurate transcription.
- Step 3: The Brain (Logic Layer). Use the transcribed text from Deepgram as the input for your chosen Large Language Model (e.g., GPT-4, Claude 3) to generate an intelligent response.
- Step 4: The Mouth (TTS Layer). Take the text response from your LLM and send it to ElevenLabs’ API to generate a natural, expressive audio response.
- Step 5: Complete the Loop. Pipe the audio generated by ElevenLabs back to the FreJun API to be played instantly to the user over the call.
This layered stack ensures you are using the absolute best tool for each critical function of a conversational AI.
Final Thoughts: Build Your AI, Not Your Telephony Stack
The question for developers in 2025 is not Elevenlabs.io Vs Deepgram.com. The real question is how to combine the power of these specialised tools into a single, cohesive, and reliable application. The answer is to build on a foundation that abstracts away the complexity of real-time communication.
Don’t let your innovative AI project be derailed by the archaic challenges of telephony. Let FreJun handle the complex voice infrastructure. Focus your talent and your resources on what truly differentiates your product: the intelligence and personality of your AI agent.
With our robust API and dedicated support, you can connect your world-class AI to the world, confidently and at scale.
Start Your Journey with FreJun AI!
Also Read: How to Build a Voice Bot Using Gemma 3 for Customer Support?
Frequently Asked Questions
No, they are complementary specialists. Deepgram specialises in Automated Speech Recognition (ASR or STT), which is turning speech into text. ElevenLabs specialises in Text-to-Speech (TTS), which is turning text into speech. A complete voice agent needs both.
No, and this is a core part of our value. We are a model-agnostic transport layer. This gives you the freedom to choose best-in-class providers like Deepgram for ASR and ElevenLabs for TTS, ensuring you never have to compromise on quality.
Some platforms offer both, but they rarely excel at both. By using specialised providers, you get the highest quality and performance for each part of the conversational loop. The Elevenlabs.io Vs Deepgram.com comparison shows how different their core strengths are.
While it involves three APIs, the architecture is far more robust and scalable. FreJun’s developer-first SDKs simplify the most complex part, the real-time audio transport. This makes integrating the ASR and TTS APIs a much more straightforward task for your application logic.