
Building Edge-Native Voice Agents is reshaping how AI systems communicate – closer, faster, and smarter. As latency becomes the deciding factor for real-time intelligence, combining AgentKit, Teler, and the Realtime API offers a unified framework to bring human-like voice interactions directly to the edge.
This isn’t just another AI integration – it’s about engineering precision, infrastructure resilience, and intelligent routing at scale. Whether you’re a founder, product manager, or engineering lead, this guide breaks down every component of how to architect responsive, reliable, and globally distributed voice systems built for the future of Edge-Native AI.
What Are Edge-Native Voice Agents and Why Are They the Next Step in AI Automation?
A new generation of conversational systems is emerging – Edge-Native Voice Agents.
These systems handle speech in real time, process intelligence at the network edge, and respond naturally without depending on long cloud round-trips.
In a typical call or conversation, even a 400 ms delay feels unnatural. Traditional cloud-based assistants often exceed that because every word must travel thousands of kilometers before processing. Edge-native design fixes this problem.
An Edge-Native Voice Agent keeps the following principles in mind:
- Computation near the user: Speech capture, initial processing, and partial inference run close to the caller.
- Streaming data flow: Audio is processed as it arrives rather than in full blocks.
- Context continuity: Conversation state is maintained locally and updated asynchronously to the cloud.
- Model agnosticism: The system can connect with any LLM, STT, or TTS engine.
These agents are not limited to virtual assistants. They can power customer-support lines, recruitment calls, appointment schedulers, or lead-qualification bots-all operating with near-human latency.
Why Build Voice AI at the Edge Instead of the Cloud?
Moving computation to the edge is not a stylistic choice-it is a latency and reliability requirement.
Performance comparison
| Metric | Cloud-Hosted Voice Agent | Edge-Native Voice Agent |
| Average round-trip delay | 600 – 900 ms | 150 – 250 ms |
| Speech continuity | Noticeable pauses | Seamless flow |
| Compliance handling | Centralized data | Region-specific data zones |
| Fault tolerance | Single-region failure risk | Multi-POP routing |
Technical reasons to move to the edge
- Reduced network hops – lower jitter and packet loss.
- Localized compute – STT and TTS engines operate inside the same region as the caller.
- Adaptive scaling – containers or micro-VMs can spin up at nearby edge nodes.
- Privacy by design – sensitive speech never leaves its jurisdiction.
Consequently, companies adopting edge computing for voice AI notice both improved user satisfaction and simpler compliance with telecom regulations.
What Technologies Power an Edge-Native Voice Agent?
Every modern voice system combines five technical components that work together through a real-time streaming layer. In a study of commercial ASR services, streaming recognition, typical for live voice agents, showed appreciably lower accuracy than non-streaming models, reinforcing the need for optimized voice pipelines.
| Layer | Role | Example Technologies |
| STT (Speech-to-Text) | Converts live audio into text tokens. | OpenAI Whisper, Deepgram, Google STT |
| LLM / Logic Core | Understands user intent and decides the next action. | OpenAI GPT-4o, Anthropic Claude, Mistral |
| RAG (Retrieval Layer) | Supplies updated or domain-specific knowledge. | Pinecone, Weaviate, FAISS |
| Tool / Action Layer | Executes external operations or API calls. | MCP-registered tools, internal APIs |
| TTS (Text-to-Speech) | Streams audio back to the caller. | ElevenLabs, Azure Neural Voices |
| Realtime Transport | Sends and receives media frames in milliseconds. | WebRTC, WebSocket, SIP over RTP |
These layers communicate continuously rather than sequentially. That streaming behavior differentiates low-latency AI agents from scripted IVRs.
Discover how multimodal AI agents combine vision, text, and voice to deliver context-aware automation across edge and cloud systems.
How Does AgentKit Simplify Building and Orchestrating Voice Agents?
AgentKit as the Control Plane
Developers often struggle to maintain dialog state, tool invocation, and error handling across asynchronous streams. AgentKit functions as the control plane for these tasks. It wraps LLM logic, memory, and function-calling into an easily composable framework.
Core abilities include:
- Session management: Tracks every active call or conversation as a discrete context.
- Multi-agent coordination: Runs several specialized agents (for booking, billing, or support) under a single orchestration.
- Tool abstraction: Registers APIs as callable functions that the LLM can invoke safely.
- Edge readiness: Deploys lightweight orchestrators next to regional Realtime API nodes for minimal delay.
How AgentKit uses MCP servers
AgentKit integrates with Model Context Protocol (MCP) servers, which act as bridges between agents and external systems.
An MCP server exposes structured “tools” or “resources.” When the agent requires external context-such as a CRM lookup or inventory query-it sends a standardized MCP request. The server handles authentication, executes the action, and returns normalized data.
This consistent interface removes the need for multiple custom connectors. For example:
{
“action”: “check_order_status”,
“parameters”: { “order_id”: “A124” },
“context_id”: “session-3021”
}
The MCP server executes the task and returns:
{
“result”: “Delivered on 30 Oct 2025”,
“source”: “orders-db”
}
Because the protocol is schema-driven, developers can test and scale integrations without editing LLM prompts or logic.
How Does the Realtime API Enable True Conversational AI?
The Realtime API is the bloodstream of an edge-native system. It transports audio samples, transcriptions, and responses as continuous data streams rather than discrete requests.
Why real-time streaming matters
- Bidirectional flow: The API simultaneously sends microphone audio to the backend and receives synthesized voice responses.
- Incremental delivery: Both STT and TTS operate on partial frames; users hear words while the sentence is still generating.
- Backpressure control: The stream adjusts automatically to network speed, ensuring consistent playback quality.
Core design concepts
| Concept | Description |
| Frame size | Typically 20–40 ms PCM chunks; smaller frames = lower latency. |
| Transport layer | WebSocket or WebRTC data channels with TLS encryption. |
| Session tokens | Short-lived JWTs verifying call ownership. |
| Heartbeat | Keeps connection alive; triggers reconnection on loss. |
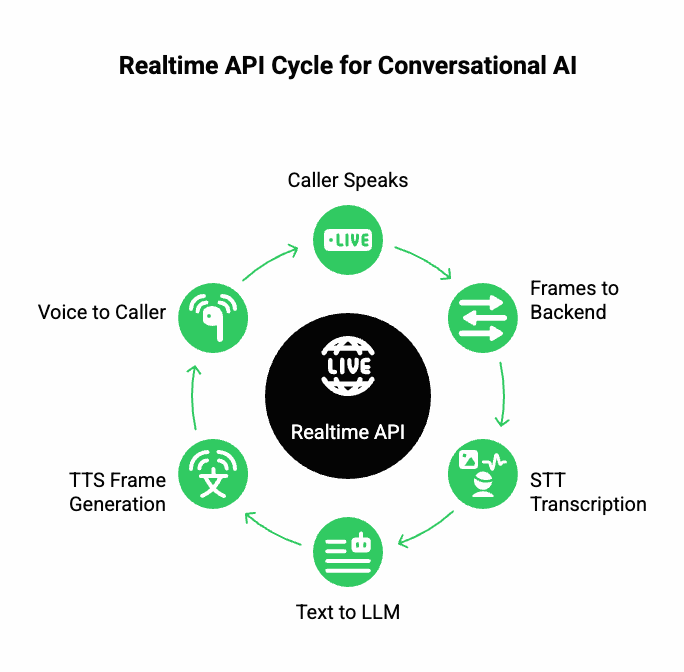
Example timeline (one turn of speech):
- Caller speaks – microphone frames stream to the edge node.
- Frames are sent via the Realtime API to the AgentKit backend.
- STT engine transcribes chunks and emits partial text.
- AgentKit forwards partial text to the LLM; the model emits partial tokens.
- Each token triggers a TTS frame that streams back to the caller.
Total perceived pause: ≈ 180 ms-low enough to feel conversational.
How Do You Combine AgentKit and the Realtime API Step by Step?
The architecture can be implemented incrementally. The workflow below assumes you have any STT, LLM, and TTS providers of choice.
Step 1 – Establish a Realtime Stream
- Create a secure WebSocket endpoint in your backend.
- Register it with the Realtime API for bidirectional media streaming.
- Authenticate using a JWT bound to the session ID.
Step 2 – Capture and Forward Audio
- Browser, mobile, or telephony edge captures PCM audio.
- Audio frames (20 ms each) are base64-encoded and pushed to the stream.
{ “type”: “audio_chunk”, “sequence”: 45, “data”: “<base64>” }
Step 3 – Invoke STT and Emit Partial Text
- Each received chunk triggers partial transcription.
- Emit incremental transcript events:
{ “type”: “partial_text”, “text”: “I need to book” }
Step 4 – Send Transcript to AgentKit
- AgentKit’s orchestrator receives the text, determines intent, and decides whether to call an MCP tool or RAG retriever.
- The response stream begins immediately.
Step 5 – Stream LLM Response and Synthesize Audio
- The LLM outputs token-level deltas:
{ “type”: “token”, “value”: “a meeting” }
- Tokens feed the TTS engine in streaming mode, producing PCM frames that are returned through the Realtime API:
{ “type”: “tts_frame”, “sequence”: 60, “audio”: “<base64>” }
Step 6 – Playback to Caller
- The receiving client buffers < 120 ms of audio before playback.
- Barge-in detection allows users to interrupt and restart mid-speech.
This streaming loop continues until either side ends the call.
How Does RAG and Tool Calling Enhance Voice Intelligence?
A voice agent that only repeats model training data is limited. Adding retrieval-augmented generation (RAG) and tool calling transforms it into an operational assistant.
RAG integration
- Ingest relevant documents into a vector database.
- Embed user queries from STT output into vectors.
- Retrieve top-k results within ~50 ms.
- Append retrieved snippets to the LLM prompt for context.
Because retrieval runs near the edge node, latency overhead stays minimal.
Tool calling with MCP
Agents can perform real actions such as creating tickets or checking payments.
Through MCP servers, each tool is registered with clear input/output schemas.
Example flow for a shipment lookup:
- User says: “Where’s my order A124?”
- STT – AgentKit intent: check_order_status.
- AgentKit – MCP call: GET /api/orders/A124.
- MCP server – responds: Delivered on 30 Oct 2025.
- LLM formats a reply – TTS – spoken response.
With this approach, every voice interaction can trigger a verified backend action, while developers retain strict control over accessible tools.
How Do You Optimize for Low Latency and Natural Voice Flow?
Smooth conversation depends on technical fine-tuning at several layers.
Audio Pipeline Optimizations
- Edge nodes first: Place the STT and TTS engines in the same data region as the caller.
- Chunk size control: 20 ms frames offer the best trade-off between bandwidth and responsiveness.
- Parallel processing: Run TTS synthesis concurrently with LLM generation.
Connection Optimizations
- Persistent sessions: Keep WebSocket open for entire dialogue.
- Heartbeat interval ≤ 5 s: Detect disconnects quickly.
- TLS 1.3 with session resumption: Avoid extra handshakes.
Conversational UX Tuning
- Send short acknowledgments (“Sure,” “Got it”) while longer responses generate.
- Allow barge-in so users can speak mid-output.
- Pre-buffer 100 ms of TTS to eliminate clipping.
Together, these steps keep total round-trip under 250 ms, which research shows humans perceive as immediate.
How Does Teler Fit into the Edge-Native Voice Architecture?
We explored how AgentKit orchestrates voice logic and how the Realtime API manages live, low-latency media streams.
But none of this can operate efficiently without a carrier-grade edge infrastructure that connects the public telephone network, IP calls, and real-time AI computation.
That’s where FreJun Teler comes in.
Teler is an edge-native telephony and realtime voice platform purpose-built for integrating AI agents into live calls.
It sits between the communication layer (SIP, RTP, WebRTC) and the intelligence layer (AgentKit + Realtime API), ensuring every millisecond of data flow is optimized.
What makes Teler different
| Capability | Traditional CPaaS | Teler Edge-Native Platform |
| Media routing | Centralized | Geo-distributed (POP-based) |
| AI streaming | Added via webhooks | Native low-latency Realtime API |
| Scalability | Region-level clusters | Edge micro POP autoscaling |
| Integration model | REST callbacks | Persistent WebSocket sessions |
| Voice continuity | Dependent on internet path | Maintained locally at edge node |
Teler’s distributed Points of Presence (POPs) ensure that the voice stream never leaves its region unnecessarily, cutting round-trip times and avoiding packet congestion.
How Does Teler Enable Edge-Native AI Voice Agents?
Teler acts as the execution layer for voice AI at the edge. Its POPs maintain bidirectional audio routing, connect to the AgentKit orchestration, and maintain persistent Realtime API sessions.
Core architecture overview
Each live call through Teler involves four active channels operating in parallel:
| Channel | Direction | Function |
| SIP/RTP | PSTN – Teler Edge | Handles raw audio transport |
| Realtime API | Teler – AgentKit | Streams audio & metadata |
| MCP | AgentKit – Backend APIs | Executes external operations |
| Control WebSocket | Orchestrator – Monitoring | Observes and scales flows |
Workflow summary:
- Incoming call → Teler routes it to the nearest POP.
- POP encodes the audio and opens a Realtime API session.
- Audio streams to AgentKit, where STT and logic layers process speech.
- Responses (via LLM → TTS) are streamed back through Teler to the caller.
- Metrics and health checks are reported asynchronously.
This event-driven model allows the same Teler deployment to serve tens of thousands of concurrent conversations globally.
How Does Teler Optimize for Ultra-Low Latency?
Edge-level routing
Each POP is equipped with:
- Local STT and TTS nodes (can run Whisper or ElevenLabs engines).
- Realtime API microservice that maintains session persistence.
- UDP audio relays for WebRTC and SIP channels.
Routing logic automatically chooses the POP closest to the caller based on IP geolocation and BGP latency tests.
For instance, a caller in Bengaluru connects to the Chennai POP, not a distant Frankfurt one-saving up to 180 ms in latency.
Adaptive jitter and packet correction
Teler employs forward error correction (FEC) and jitter buffers tuned dynamically to network behavior.
This ensures stable playback even under variable bandwidth, a common issue in mobile or VoIP environments.
Local inference handoff
When paired with AgentKit’s edge-deployed orchestrator, inference requests can run directly at the POP, bypassing cloud hops entirely.
This configuration enables sub-200 ms conversational turnaround-essential for human-like dialogues.
How Does Teler’s Realtime API Integration Work in Practice?
Teler exposes an open Realtime API interface compatible with streaming LLMs and TTS services.
Session flow example
| Step | Operation | Duration |
| 1 | Teler receives inbound RTP audio | 20 ms |
| 2 | Audio frames sent via WebSocket to Realtime API | 30 ms |
| 3 | STT → LLM → TTS response chain | 120 ms |
| 4 | Audio returned to POP and played | 60 ms |
| Total latency | 230 ms end-to-end |
Data structure sample
Incoming and outgoing messages follow a consistent JSON schema:
{
“session_id”: “call-10292”,
“type”: “audio_frame”,
“direction”: “inbound”,
“timestamp”: “2025-10-31T10:22:12.202Z”,
“data”: “<base64 PCM>”,
“metadata”: { “sample_rate”: 16000 }
}
{
“session_id”: “call-10292”,
“type”: “audio_frame”,
“direction”: “outbound”,
“timestamp”: “2025-10-31T10:22:12.354Z”,
“data”: “<base64 PCM>”,
“metadata”: { “tts_engine”: “elevenlabs”, “voice”: “sarah” }
}
Error recovery
Teler maintains retry and resume strategies for each stream:
- Frame retries on packet loss < 2%.
- Stream resume tokens allow reconnecting without restarting the call.
- Health pings every 3 seconds ensure the Realtime API session stays active.
How Can Developers Deploy Edge-Native Voice Agents on Teler?
Let’s outline a deployment checklist for teams building production-grade low-latency AI agents on Teler.
Setup
- Provision Teler account and obtain API credentials.
- Create a Realtime API keypair for your AgentKit orchestrator.
- Configure edge POPs – choose primary (e.g., Mumbai) and fallback (e.g., Singapore).
Integration
- Register your AgentKit endpoint with Teler’s Realtime API.
- Define call routing rules – DID, SIP trunk, or WebRTC origin.
- Configure webhook for status and error reporting.
- Enable MCP bridge for tool invocation from LLM responses.
Testing
- Use teler-cli simulate-call to test audio round-trips.
- Benchmark latency across regions with teler-ping.
- Verify edge-to-agent RTT < 250 ms before scaling.
Scaling
- Auto-scale via Kubernetes HPA using stream metrics.
- Configure edge caching for TTS models frequently reused.
- Deploy lightweight inference containers alongside POPs for domain-specific logic.
This approach ensures consistent performance as your call volume grows.
How Does Teler Handle Global Scaling and Failover?
Enterprises with distributed operations need reliability as much as speed.
Teler uses a geo-aware scaling mechanism with intelligent DNS routing and multi-POP health monitoring.
Elastic architecture
- Stateless POPs: Each POP processes calls independently; no cross-dependency.
- Central control plane: Manages provisioning, scaling, and metrics.
- Global logging bus: Aggregates telemetry in near real time for visibility.
Together, these elements allow enterprises to maintain a global edge-native voice AI with predictable latency everywhere.
How Does Teler Compare to Traditional Voice Platforms?
| Feature | Legacy CPaaS | FreJun Teler |
| Latency (RTT) | 600–900 ms | 180–250 ms |
| AI integration | Via REST callbacks | Native Realtime stream |
| Edge POPs | Limited | Global coverage |
| Tooling | Webhook-based | AgentKit + MCP |
| Barge-in support | Not available | Real-time |
| Reconnection | Full session restart | Stream resume tokens |
| Security | Shared region | Regional isolation with per-session tokens |
While CPaaS platforms were built for programmable telephony, Teler was built for AI-native voice workloads – where conversational fluidity, streaming inference, and latency consistency are non-negotiable.
How to Monitor and Optimize Edge-Native Voice Agents on Teler
Performance monitoring is crucial to sustain production-level reliability.
Key metrics to track
| Metric | Ideal Threshold | Purpose |
| Round-trip latency | < 250 ms | Ensures a real-time feel |
| Packet loss | < 1% | Voice stability |
| Session uptime | > 99.9% | Service reliability |
| STT confidence | > 0.92 | Transcription quality |
| TTS synthesis delay | < 120 ms | Smooth playback |
Observability features
- Real-time dashboards visualize active sessions, per-region latency, and jitter.
- Structured logs capture per-call Realtime API events.
- Webhook alerts trigger if POP health drops.
- Audio diagnostics allow playback of degraded segments for analysis.
With these insights, teams can identify edge hotspots and dynamically rebalance call distribution.
How Do You Ensure Security and Compliance at the Edge?
Teler’s edge computing for voice AI architecture embeds security at each layer.
- Regional data zoning: Audio data remains in-region unless explicitly exported.
- Short-lived tokens: Session-level JWTs expire automatically after the call ends.
- TLS 1.3 encryption: All signaling and media channels are encrypted end-to-end.
- Policy controls: Restrict LLM access to specific MCP tools only.
- Audit trail: Each Realtime API event is timestamped and signed for verification.
This makes Teler compliant with GDPR, HIPAA, and telecom-grade security frameworks, while still supporting low-latency operations.
What’s Next for Edge-Native Voice AI?
As OpenAI AgentKit, FreJun Teler, and Realtime API frameworks continue maturing, we’ll see:
- Local model caching at POPs for instant response.
- LLM streaming over QUIC, further reducing latency.
- Cross-agent memory is shared securely between regional deployments.
- Federated fine-tuning to improve accuracy while preserving privacy.
In short, the future of voice AI at the edge is real-time, region-aware, and action-capable-ready to operate as fast as humans speak.
Final Thoughts: Building the Foundation for Edge-Native Intelligence
Edge-Native Voice Agents have moved from concept to capability. With AgentKit orchestrating logic, the Realtime API ensuring live, bidirectional audio flow, and Teler handling intelligent edge routing, teams can now build production-ready voice systems that respond in milliseconds.
Each layer of intelligence, communication, and infrastructure has been optimized to work in sync, enabling natural, human-like interactions at scale.
This architecture redefines how real-time AI conversations are delivered-faster, localized, and context-aware.
Ready to experience true Edge-Native Voice AI in action?
Schedule a live demo to see how Teler’s Realtime API and AgentKit can power your next-generation AI voice workflows.
Book a FreJun Teler Demo
FAQs –
- What are Edge-Native Voice Agents?
Voice systems that operate at the network edge for ultra-low latency, processing speech and responses in real time. - Why is edge computing important for voice AI?
It minimizes latency, reduces bandwidth dependency, and improves reliability for interactive, real-time AI conversations. - Can I use any LLM with Teler and AgentKit?
Yes. Teler and AgentKit are model-agnostic and support seamless integration with OpenAI, Anthropic, or custom LLMs. - How does Teler reduce call latency?
By routing voice packets through distributed edge nodes for faster, localized processing and real-time audio synchronization. - Does Teler support bidirectional media streaming?
Yes. It enables full-duplex, low-latency streaming for both inbound and outbound call audio simultaneously. - What tools are required to deploy an edge-native agent?
You’ll need an LLM, TTS, STT, AgentKit orchestration, and Teler for real-time telephony integration. - Is this setup suitable for enterprise-scale deployments?
Absolutely. The stack supports high concurrency, global scalability, and enterprise-grade security protocols. - Can voice context persist across calls?
Yes. Through Realtime API session management and backend memory layers, context continuity is fully supported. - How does Teler differ from typical telephony providers?
Unlike basic calling APIs, Teler provides AI-optimized routing, real-time streaming, and programmable voice infrastructure. - What’s the best way to test an edge-native voice agent?
Deploy a prototype using Teler’s sandbox environment with AgentKit and your preferred LLM to benchmark latency and flow.