
For developers, building a production-grade voice AI is about more than just models. It’s about flow, latency, and the orchestration of multiple specialized tools. Deepgram.com and Pipecat.ai represent two distinct approaches: Deepgram delivers best-in-class transcription, while Pipecat offers a framework for real-time interactive dialogue.
Picking the wrong tool early on can lead to wasted effort or brittle architecture. Understanding their differences is the first step to building an AI agent that truly works in the real world.
Table of contents
- What is Deepgram.com? An Expert Overview
- What is Pipecat.ai? An Expert Overview
- The Missing Piece: Why Voice Infrastructure Matters More
- Deepgram.com Vs Pipecat.ai: A Head-to-Head Comparison
- Comparison Table: Deepgram.com vs. Pipecat.ai vs. FreJun AI
- How to Build a Production-Grade Voice Agent with FreJun AI
- Final Thoughts: Build Your AI, Not Your Plumbing
- Frequently Asked Questions
The Core Dilemma: Choosing the Right AI Voice Platform
Building a sophisticated AI voice agent in 2025 presents a critical challenge right from the start: selecting the correct technology stack. As developers and product leaders aim to create seamless, human-like conversational experiences, they often find themselves at a crossroads, evaluating platforms that seem similar but solve fundamentally different problems. This confusion frequently leads to a debate between two prominent names: Deepgram.com Vs Pipecat.ai.
On one side, you have platforms focused on deciphering human speech with incredible accuracy. On the other, you have frameworks designed to facilitate real-time, interactive dialogue. Choosing the wrong one can lead to project delays, scalability issues, and a disjointed user experience.
The core of the issue is not just about picking a tool, but about understanding the architectural layers required to build a truly powerful voice agent. Many developers invest heavily in speech recognition or conversational logic, only to realize they’ve neglected the most critical and complex component: the underlying voice transport infrastructure.
What is Deepgram.com? An Expert Overview
Deepgram.com has established itself as a leader in the AI speech recognition space. Its primary function is to provide highly accurate and fast automatic speech-to-text (ASR) services. Think of Deepgram as the “ears” of your AI application. It is engineered to listen to audio streams, whether from a phone call, a meeting, or a media file, and convert spoken words into structured, machine-readable text.
The platform excels in enterprise environments where precision and scalability are paramount. It supports real-time transcription with very low latency, making it suitable for applications that require immediate text output from live audio.
Core Features and Strengths of Deepgram.com
- High-Accuracy ASR: Deepgram is renowned for its transcription accuracy, offering models tailored for specific industries (e.g., finance, healthcare) and languages.
- Real-Time Transcription: It is optimized to process audio streams live, which is essential for applications like real-time customer support analytics.
- Advanced Speech Analytics: Beyond basic transcription, Deepgram provides features like speaker identification (diarization), sentiment analysis, and the detection of specific keywords.
- Enterprise Scalability: With robust developer APIs, it is designed to handle high volumes of audio processing for large-scale deployments in contact centers and analytics platforms.
Deepgram is the ideal choice when the primary goal of your project is to understand what is being said. Its use cases revolve around transforming speech into data for analysis, compliance, or operational intelligence.
Also Read: Synthflow.ai Vs Retellai.com: Which AI Voice Platform Is Best for your Next AI Voice Project
What is Pipecat.ai? An Expert Overview

Pipecat.ai approaches the AI voice challenge from a different angle. It is not focused on what was said, but on enabling a real-time conversation. Pipecat.ai provides the infrastructure for developers to build interactive AI agents that can engage in live, low-latency dialogue. It is the framework that allows an AI to “speak” and “interact” back, often incorporating both voice and video.
Think of Pipecat.ai as the “nervous system” for a conversational AI. It manages the flow of data between the user, your AI logic (like a Large Language Model or LLM), and the output channels, ensuring the conversation feels fluid and natural.
Core Features and Strengths of Pipecat.ai
- Real-Time Conversational AI: The platform is purpose-built for creating interactive voice and video streaming agents.
- Low-Latency Dialogue: Its architecture is heavily optimized to minimize delays, which is crucial for creating engaging and immersive AI-powered experiences.
- Developer-First Framework: Pipecat.ai offers APIs and tools specifically for building live, multimodal (voice and video) AI conversations.
- Focus on Interactivity: It is best suited for projects where the primary goal is to create an engaging, back-and-forth interaction, such as AI avatars, gaming characters, or virtual assistants.
In the Deepgram.com Vs Pipecat.ai debate, Pipecat.ai is the clear winner if your project requires your AI to participate in a live, dynamic conversation.
The Missing Piece: Why Voice Infrastructure Matters More
While the Deepgram.com Vs Pipecat.ai comparison is useful, it highlights a common blind spot for developers. Both platforms solve a piece of the puzzle—Deepgram handles the “listening,” and Pipecat facilitates the “interacting.” However, neither addresses the complex, foundational layer of voice transport and telephony. How do you get the audio from a phone call to your AI application in the first place, reliably and with low latency?
This is where FreJun AI comes in. FreJun is not an STT or a conversational framework; it is the robust voice infrastructure that connects your AI to the global telephone network. We handle the complex plumbing so you can focus on building your AI logic.
FreJun provides a real-time, low-latency API that captures audio from any inbound or outbound call and streams it to your application. Your application then processes this audio with your chosen STT service (like Deepgram), manages the dialogue with your AI model, generates a response with your TTS service, and pipes the response audio back through FreJun’s API for seamless delivery to the user.
By abstracting away the complexities of voice infrastructure, FreJun allows you to bring your own AI stack (STT, LLM, TTS) while ensuring the conversation is built on a foundation of speed and clarity.
Also Read: Play.ai Vs Assemblyai.com: Which AI Voice Platform Is Best for Developers in 2025
Deepgram.com Vs Pipecat.ai: A Head-to-Head Comparison
To make an informed decision, it’s crucial to understand where each platform fits. The choice between Deepgram.com Vs Pipecat.ai ultimately depends on your project’s primary objective: speech understanding versus real-time interaction.
- Choose Deepgram.com if: Your core need is to convert spoken audio into accurate text for analysis. This is common in use cases like call center monitoring, meeting transcription, and voice command recognition. The focus is on the input—what the user said.
- Choose Pipecat.ai if: Your core need is to build an interactive agent that can hold a live conversation. This is ideal for AI avatars, virtual customer assistants, and interactive entertainment. The focus is on the interactive output, the conversational loop.
Comparison Table: Deepgram.com vs. Pipecat.ai vs. FreJun AI
| Feature | Deepgram.com | Pipecat.ai | FreJun AI |
| Primary Function | Automatic Speech Recognition (ASR) / Speech-to-Text | Real-Time Conversational AI Framework | Voice Transport & Telephony Infrastructure |
| Core Focus | Understanding speech (input) | Enabling real-time interaction (output) | Reliably streaming voice to/from any AI |
| Best For | Transcription, analytics, call monitoring | AI avatars, gaming NPCs, live assistants | Production-grade voice agents for any use case |
| Handles Telephony? | No | No | Yes, natively |
| Latency Focus | Low-latency transcription | Low-latency dialogue loop | Low-latency media streaming for the entire call |
| AI Model Agnostic? | N/A (Is an AI model) | Integrates with various LLMs | Yes, bring your own STT, LLM, and TTS |
| Role in the Stack | The “Ears” (STT Service) | The “Nervous System” (Interaction Framework) | The “Plumbing” (Voice Infrastructure) |
Also Read: Play.ai Vs Assemblyai.com: Which AI Voice Platform Is Best for Developers in 2025
How to Build a Production-Grade Voice Agent with FreJun AI
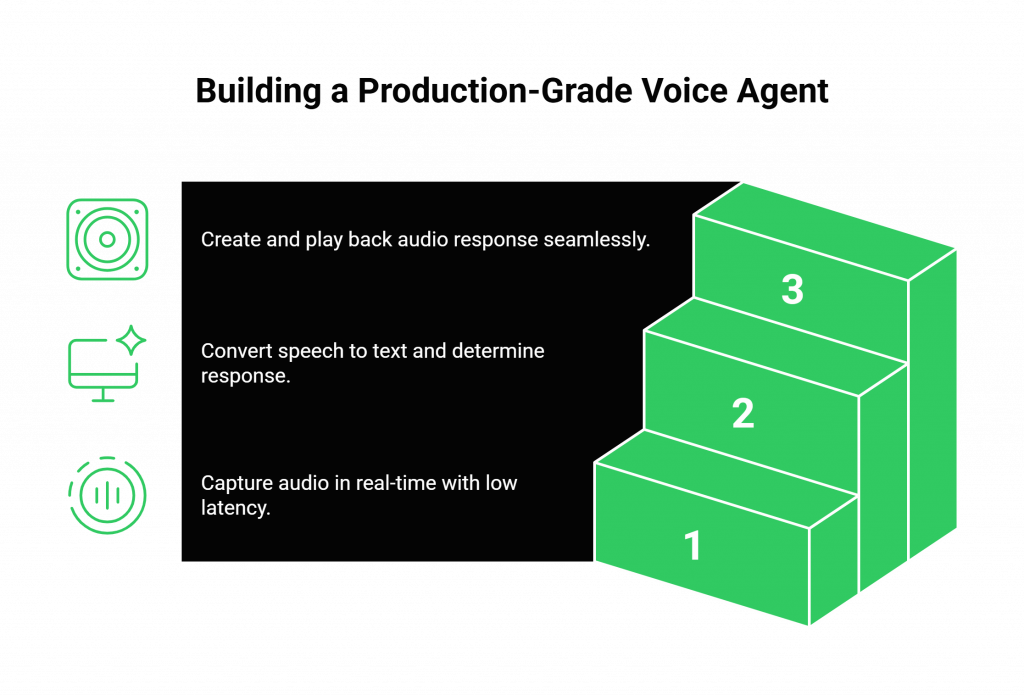
Instead of getting locked into a single vendor’s ecosystem, FreJun empowers you to build a best-in-class voice agent using the components of your choice. Here’s how you can architect a powerful solution.
Step 1: Stream Voice Input with FreJun
Your journey begins when a call is initiated, either inbound to your business or outbound from your application. FreJun’s API captures this audio in real-time with extremely low latency. Our geographically distributed infrastructure ensures a clear, stable connection, so every word is captured without delay. This raw audio stream is forwarded directly to your backend service.
Step 2: Process with Your Chosen AI Stack
Once the audio stream arrives at your backend, you maintain full control. You can pipe this audio to any STT service you prefer—Deepgram is an excellent choice for high-accuracy transcription. After converting the speech to text, you pass it to your chosen Large Language Model (LLM) or context management solution to determine the appropriate response. FreJun acts as a reliable transport layer, giving your application complete authority over the dialogue state.
Step 3: Generate and Stream Voice Response via FreJun
After your AI logic generates a text response, you send it to your preferred Text-to-Speech (TTS) service to create the response audio. You then simply pipe this generated audio back into the FreJun API. Our platform handles the low-latency playback to the user on the call, completing the conversational loop seamlessly and eliminating the awkward pauses that plague lesser systems.
This model-agnostic approach provides ultimate flexibility and future-proofs your application. As better STT, LLM, or TTS models emerge, you can swap them in without rebuilding your core voice infrastructure.
Final Thoughts: Build Your AI, Not Your Plumbing
Choosing the right components for your AI voice project is critical, and understanding the nuances between platforms like Deepgram.com and Pipecat.ai is an important step. Deepgram offers world-class speech understanding, while Pipecat provides a framework for real-time interaction.
However, the most strategic decision you can make is to abstract away the underlying complexity of voice communication. Building and maintaining resilient, low-latency, and globally distributed voice infrastructure is a monumental task that distracts from your core objective: creating a smart and effective AI agent.
FreJun AI handles this for you. Our developer-first platform is engineered for the sole purpose of turning any text-based AI into a powerful voice agent, backed by enterprise-grade security, reliability, and dedicated support. By leveraging FreJun, you can launch a sophisticated voice solution in days, not months. The discussion of Deepgram.com Vs Pipecat.ai becomes a simple component choice, not a foundational architecture dilemma.
Let us manage the voice layer. You focus on bringing your AI to life.
Start Your Journey with FreJun AI!
Also Read: Virtual PBX Phone Systems Implementation Guide for Enterprises in Indonesia
Frequently Asked Questions
Yes, developers can potentially use both in a hybrid application. For instance, you could use Deepgram for its superior transcription accuracy to understand user intent and then use a framework like Pipecat to manage the interactive response. However, you still need a telephony layer like FreJun to connect the call to these services.
No. FreJun is a voice transport layer. We specialize in providing the real-time media streaming infrastructure. This model-agnostic approach gives you the freedom to choose the best STT, TTS, and LLM providers for your specific needs, ensuring you are never locked into a single vendor’s AI ecosystem.
Yes. FreJun provides the raw audio stream from the phone call. You will need an STT service like Deepgram to convert that audio into text so your AI model can process it. FreJun is the “plumbing” that reliably delivers the audio to your chosen STT service.
Building production-grade voice infrastructure involves managing complex telephony integrations, ensuring low latency across global networks, handling packet loss, and maintaining high availability. This is a highly specialized and resource-intensive effort. FreJun provides this as a managed service, allowing you to go to market faster and focus your engineering resources on your core AI product.
Our entire technology stack, from our API to our geographically distributed infrastructure, is optimized to minimize latency at every step: capturing user speech, streaming it to your AI, and streaming the AI’s audio response back to the user. This focus on speed and clarity eliminates the unnatural delays that break conversational flow.