
Every developer building a voice agent runs into the same fork in the road: prioritize low-latency speech recognition for real-time conversations, or prioritize rich audio intelligence for insights and analytics. That’s the Deepgram.com vs Assemblyai.com decision in a nutshell. But whichever you pick, both expect clean audio streams to work with.
Managing telephony, codec conversions, and global, low-latency streaming? That’s a different engineering battle altogether, and it’s where most projects stumble without the right infrastructure.
Table of contents
- The Developer’s Crossroads: Speed vs. Intelligence in AI Voice
- What is Deepgram.com? The Champion of Real-Time Transcription
- What is Assemblyai.com? The Powerhouse of Audio Intelligence
- The Missing Link: Why Your STT Platform Needs a Voice Infrastructure Layer
- Deepgram.com Vs Assemblyai.com: A Head-to-Head Comparison
- How to Build a Production-Grade Voice Agent with FreJun AI?
- Final Thoughts: Choose Your AI, But Build on a Solid Foundation
- Frequently Asked Questions
The Developer’s Crossroads: Speed vs. Intelligence in AI Voice
When building a modern AI voice agent, developers inevitably arrive at a critical decision point: choosing the right speech-to-text (STT) engine. This choice fundamentally shapes the agent’s capabilities and performance. The market is filled with excellent options, but the discussion frequently narrows down to a head-to-head evaluation of Deepgram.com Vs Assemblyai.com.
This comparison represents a classic trade-off: Do you prioritize the raw speed and scalability needed for real-time conversations, or the deep audio intelligence required to extract meaningful insights from them?
Making the wrong choice can lead to an application that is either too slow for natural dialogue or too shallow to provide real business value. However, the biggest mistake developers make is believing this is the only choice that matters.
They invest countless hours comparing API features and accuracy benchmarks, only to discover that both platforms are fundamentally limited by a problem they don’t solve: the complex, messy, and latency-sensitive challenge of real-time voice transport.
What is Deepgram.com? The Champion of Real-Time Transcription
Deepgram.com has positioned itself as the go-to solution for developers who require exceptional speed and accuracy in speech-to-text conversion. Built on end-to-end deep learning models, the platform is optimized for real-time, streaming transcription. In the context of a voice AI project, Deepgram acts as the agent’s hyper-responsive “ears,” capturing and converting spoken words into text with minimal delay.
This focus on low latency makes it an ideal choice for interactive applications where a seamless, back-and-forth conversational flow is non-negotiable. It is engineered from the ground up for enterprise-grade scalability, capable of handling the high-volume, concurrent audio streams typical of contact centers and live virtual events.
Core Strengths for Developers
- Ultra-Low Latency: Deepgram is architected for speed, making it perfect for live voice assistants and real-time call transcription where every millisecond counts.
- High Scalability: The platform is designed to support massive-scale deployments, providing reliable performance for applications with thousands of simultaneous users.
- Advanced Transcription Features: Its API offers more than just text output, providing functionalities like speaker diarization (identifying who is speaking), automatic punctuation, and keyword spotting.
- Developer-Friendly Tools: With a suite of SDKs and a clear API-first approach, Deepgram enables developers to integrate its powerful STT capabilities into their workflows efficiently.
When the project goal demands fast, accurate, and scalable transcription, Deepgram is a formidable contender.
Also Read: Pipecat.ai Vs Superbryn.com: Which AI Voice Platform Is Best for Developers in 2025
What is Assemblyai.com? The Powerhouse of Audio Intelligence
Assemblyai.com approaches the audio processing challenge from a different perspective. While it provides a highly accurate STT engine, its true value lies in the rich layer of audio intelligence it builds on top of the transcription. AssemblyAI is designed not just to tell you what was said, but to provide a deep understanding of the meaning, context, and sentiment behind the words.
This makes it a powerful tool for projects where the goal is to analyze audio data for insights. Think of AssemblyAI as the “brain” that processes the conversation, identifying key topics, summarizing content, and detecting important entities.
Core Strengths for Developers
- Rich Audio Intelligence: AssemblyAI’s API goes far beyond transcription, offering features like sentiment analysis, topic detection, content summarization, and entity recognition out of the box.
- Actionable Insights: It is ideal for analytics-driven projects, such as compliance monitoring, podcast analysis, and extracting business intelligence from customer calls.
- Comprehensive Post-Processing: The platform excels at taking raw audio and transforming it into structured, usable data that can power dashboards, trigger workflows, and inform business decisions.
- API-First for Modern Applications: Popular with startups and SaaS companies, its API makes it easy to embed sophisticated audio intelligence into any product.
For developers focused on extracting deep, actionable insights from audio content, AssemblyAI presents a compelling case in the Deepgram.com Vs Assemblyai.com evaluation.
The Missing Link: Why Your STT Platform Needs a Voice Infrastructure Layer
The comparison between Deepgram.com Vs Assemblyai.com is a valid and important one. However, both platforms are API-based AI services. They expect to receive a clean audio stream to process. They do not, and are not designed to, handle the complex and unforgiving world of real-time telephony.
This is the critical gap that FreJun AI fills. We are the foundational voice infrastructure layer that connects your application to the global telephone network. We handle the “plumbing”, the complex tasks of managing SIP trunks, ensuring low-latency media streaming, and maintaining a resilient, geographically distributed network, so you can focus on building your AI.
FreJun provides a model-agnostic API that captures audio from any inbound or outbound call and streams it to your backend. From there, you are free to send that audio to any STT engine you choose, whether it’s Deepgram for its speed or AssemblyAI for its intelligence.
After your AI logic and TTS engine generate a response, you simply pipe the audio back through our API for seamless playback to the user. We provide the essential connection that makes real-time conversational AI possible.
Also Read: Pipecat.ai Vs Assemblyai.com: Which AI Voice Platform Is Best for Developers in 2025
Deepgram.com Vs Assemblyai.com: A Head-to-Head Comparison
The choice between these two platforms depends entirely on your project’s primary objective. Are you building a live conversational agent that needs to respond instantly, or an analytics platform that needs to understand the nuances of a conversation after the fact?
To provide clarity, here is a direct comparison, with the crucial addition of the infrastructure layer that enables both.
Comparison Table: Deepgram.com vs. Assemblyai.com
| Feature | Deepgram.com | Assemblyai.com |
| Primary Function | Real-Time Speech-to-Text (STT) | Audio Intelligence & STT |
| Core Focus | Speed, scalability, and transcription accuracy | Insights, analytics, and data enrichment |
| Best For | Live assistants, contact centers, meetings | Media analysis, compliance, BI dashboards |
| Handles Telephony? | No | No |
| Key Differentiator | Ultra-low latency for streaming | Advanced AI features (summarization, etc.) |
| Role in the Stack | The “Ears” | The “Ears & Brain” |
Also Read: Superbryn.com Vs Assemblyai.com: Which AI Voice Platform Is Best for Developers in 2025
How to Build a Production-Grade Voice Agent with FreJun AI?
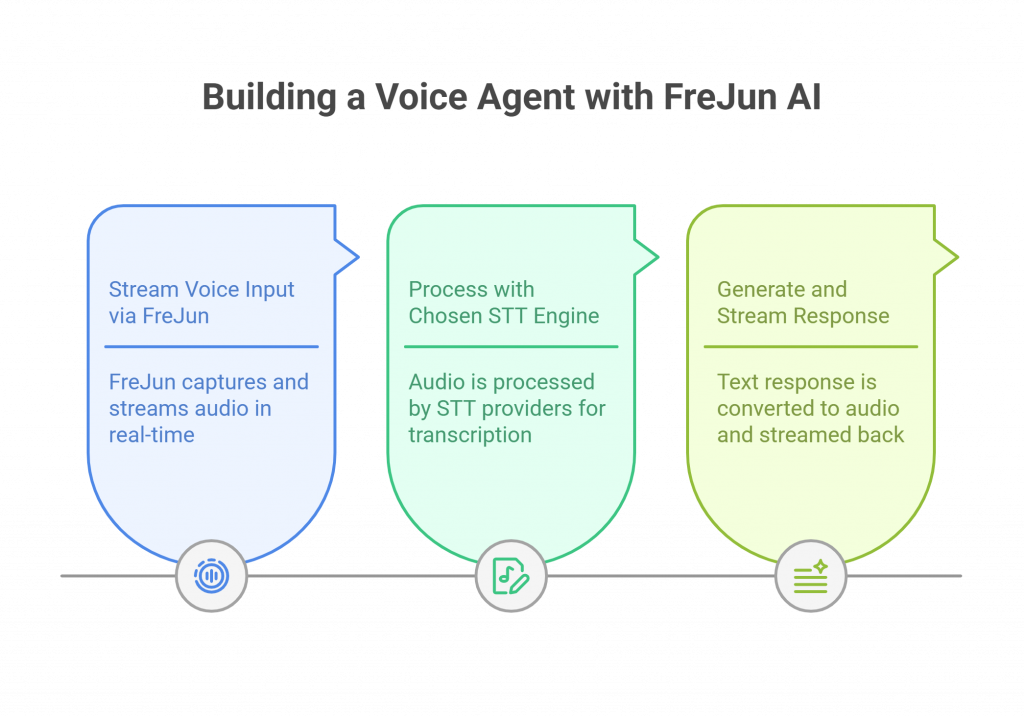
FreJun’s developer-first platform makes it simple to architect a powerful and flexible voice agent using the best components for your needs.
Step 1: Stream Voice Input via FreJun
When a call is connected through our platform, FreJun’s API captures the audio and begins streaming it in real-time to your specified backend endpoint. Our global infrastructure is engineered to deliver this stream with minimal latency and maximum clarity.
Step 2: Process with Your Chosen STT Engine
Your backend receives the audio stream and forwards it to your chosen STT provider.
- For a live agent: You would likely choose Deepgram.com to get a fast transcription, enabling a quick response.
- For post-call analysis: You could send the recorded audio to Assemblyai.com to generate a summary, track sentiment, and identify key topics.
FreJun gives you the flexibility to use either or even both for different parts of your workflow.
Step 3: Generate and Stream the Response
Once your AI logic has a text response, you use a Text-to-Speech (TTS) engine to convert it to audio. You then stream this audio back into the FreJun API. Then, we handle the low-latency playback to the user, completing the conversational loop seamlessly.
Final Thoughts: Choose Your AI, But Build on a Solid Foundation
In the rapidly advancing field of conversational AI, the quality of your components matters. Both Deepgram.com and Assemblyai.com offer best-in-class solutions that cater to different, though sometimes overlapping, needs. Your specific use case drives the choice: use Deepgram for real-time interactivity and AssemblyAI for deep analytical insight.
However, this choice alone does not determine your voice project’s success. The quality of the foundation beneath your AI stack does. Building and maintaining a resilient, low-latency, and globally scalable voice transport layer is a massive undertaking that distracts from your core mission.
FreJun AI solves this problem. We provide a robust, developer-first infrastructure that allows you to bring your own AI. We handle the complex plumbing of voice communication so you can focus on what you do best: building an intelligent, engaging, and valuable AI experience.
Start Your Journey with FreJun AI!
Also Read: Enterprise International Communication Methods for Calling Peru from the United States
Frequently Asked Questions
The primary difference is their focus. Deepgram is optimized for real-time speed and scalable transcription, making it ideal for live applications. AssemblyAI focuses on providing a suite of audio intelligence features (like summarization and sentiment analysis) on top of its transcription service.
Yes. With an infrastructure provider like FreJun, you could use Deepgram for the live transcription of a call to power a real-time agent, and then send the call recording to AssemblyAI for post-call analysis and summarization.
No. FreJun is a model-agnostic voice infrastructure platform. We provide the real-time audio stream, and you are free to integrate with any STT provider you choose.
STT platforms are API-based services; they are not telephone companies. They cannot manage call routing, SIP connections, or the real-time streaming challenges of the global telephone network. A dedicated infrastructure layer like FreJun is required to bridge this gap reliably and at scale.
There is no single winner. The best choice depends on your specific project needs. Deepgram wins for speed; AssemblyAI wins for insights.