
The ability to create a Real-Time Voice Bot that streams audio to sophisticated AI engines is one of the most exciting frontiers in modern software development. The goal is to build an application that can listen, think, and speak in a fluid, low-latency conversation that feels remarkably human. The architectural pattern is becoming well-established: a real-time pipeline that connects a user’s microphone to a Speech-to-Text (STT) engine, a Large Language Model (LLM) for logic, and a Text-to-Speech (TTS) engine for the response.
Countless tutorials and open-source projects provide a compelling Voice Bot Example of this in action. They show you how to wire up these APIs, and with a bit of code, you can have a brilliant AI conversing with you through your computer. But a critical, often glossed-over, chasm exists between these examples and a production-ready business solution. The moment you try to move your bot from the browser to the telephone, the entire architecture breaks down.
Table of contents
- What is a Real-Time Voice Bot? An Architectural Blueprint
- The Hidden Roadblock: Why Most Voice Bot Examples Are Incomplete
- FreJun: The Infrastructure API for Your AI Engines
- DIY Telephony vs. The FreJun Platform: A Strategic Comparison
- A Complete Voice Bot Example: The Modern Architecture
- Best Practices for a Flawless Real-Time Streaming Experience
- Final Thoughts: Build the Brain, Not the Body
- Frequently Asked Questions (FAQ)
What is a Real-Time Voice Bot? An Architectural Blueprint
Before we explore the challenge, let’s define the system we’re building. A Real-Time Voice Bot is a system orchestrated by a backend application to manage a live, spoken dialogue. The core, high-speed pipeline looks like this:
- Audio Capture & Streaming: The user speaks, and their voice is captured and streamed, chunk by chunk, over a persistent connection like a WebSocket.
- Live Transcription (ASR): The audio is fed to an STT engine (like AWS Transcribe or Google STT), which provides a live text transcription.
- AI Logic & Response Generation (LLM): The transcribed text is sent to a language model (like OpenAI’s GPT-4 or Gemini), which analyzes intent, accesses conversational context, and generates a response.
- Streaming Synthesis (TTS): The AI’s text response is fed to a TTS engine (like Amazon Polly or ElevenLabs), which synthesizes the audio and streams it back to the user.
This entire loop must operate with sub-second latency to feel natural and conversational.
The Hidden Roadblock: Why Most Voice Bot Examples Are Incomplete
The typical Voice Bot Example you find online is designed for a web browser. It uses the Web Audio API to capture microphone input and a client-side WebSocket to stream it to a backend. This is a perfect setup for a demo.
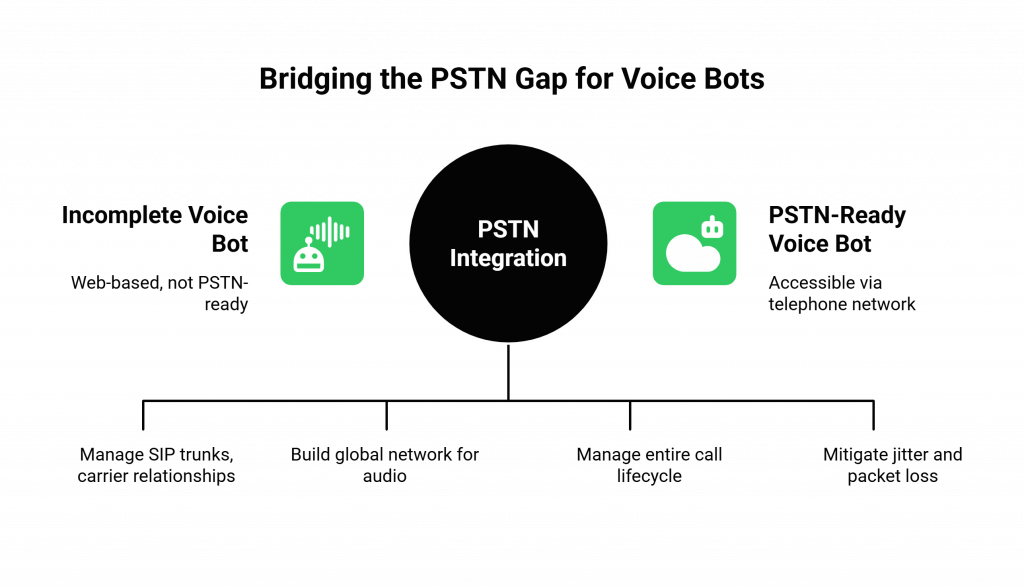
The problem is that this setup is completely useless for the telephone network.
The Public Switched Telephone Network (PSTN) is a completely different universe. To make your bot answer a phone call, you must solve a host of complex, low-level infrastructure problems that have nothing to do with AI:
- Telephony Protocols: You need to manage SIP (Session Initiation Protocol) trunks and carrier relationships to connect to the global phone network.
- Real-Time Media Servers: You have to build, deploy, and maintain a global network of specialized servers capable of handling raw audio streams from thousands of concurrent calls.
- Call Control Signaling: You are now responsible for the entire call lifecycle, ringing, connecting, holding, and terminating, for every single session.
- Network Resilience: Phone networks are prone to jitter and packet loss, which can garble audio. You must build systems to mitigate these issues.
This is the hidden roadblock. Your brilliant AI, backed by a perfectly orchestrated backend, is trapped. It cannot be reached by the millions of customers who rely on the telephone for important, time-sensitive interactions. The elegant Voice Bot Example that worked on your laptop is not a viable business solution.
FreJun: The Infrastructure API for Your AI Engines
This is the exact problem FreJun was built to solve. We are not another AI engine. We are the specialized voice infrastructure platform that provides the missing link, allowing you to stream audio from a real phone call directly to your existing AI backend.
FreJun handles the entire complex, messy, and mission-critical telephony layer. We provide a simple, developer-first API that makes a live phone call look just like another WebSocket connection to your application.
- We are AI-Agnostic: You bring your own AI stack. FreJun integrates seamlessly with any backend built on any combination of STT, LLM, and TTS APIs.
- We Manage the Voice Infrastructure: We handle the phone numbers, the SIP trunks, the global media servers, and the low-latency audio streaming.
- We Guarantee Reliability and Scale: Our enterprise-grade, globally distributed platform is built for high availability and massive concurrency.
With FreJun, you can take your existing Voice Bot Example and turn it into a production-ready, omnichannel solution without writing a single line of telephony code.
DIY Telephony vs. The FreJun Platform: A Strategic Comparison
| Feature | The DIY Telephony Approach | The FreJun Platform Approach |
| Infrastructure | You build, manage, and scale your own voice servers, SIP trunks, and network protocols. | Fully managed. FreJun handles all telephony, streaming, and server infrastructure. |
| Scalability | Extremely difficult and costly to build a globally distributed, high-concurrency system. | Built-in. Our platform elastically scales to handle any number of concurrent calls on demand. |
| Latency Management | You are responsible for intelligent routing and minimizing latency across all geographic regions. | Managed by FreJun. Our global infrastructure ensures sub-second response times worldwide. |
| Development Time | Months, or even years, to build a stable, production-ready system. | Weeks. Launch your globally scalable voice bot in a fraction of the time. |
| Developer Focus | Divided 50/50 between building the AI and wrestling with low-level network engineering. | 100% focused on building the best possible conversational AI experience. |
| Maintenance & Cost | Massive capital expenditure and ongoing operational costs for servers, bandwidth, and a specialized DevOps team. | Predictable, usage-based pricing with no upfront capital expenditure and zero infrastructure maintenance. |
Key Takeaway
A production-ready Voice Bot Example is a two-part challenge: the AI Core (your backend logic and AI services) and the Voice Infrastructure (the telephony and streaming layer). The vast majority of online examples only address the first part. The most effective and efficient strategy is to focus your expertise on building the best possible AI Core and partner with a specialized platform like FreJun to handle the immense complexity of the Voice Infrastructure.
A Complete Voice Bot Example: The Modern Architecture
This guide outlines the modern, scalable architecture for a voice bot that can handle real phone calls by streaming to AI engines.
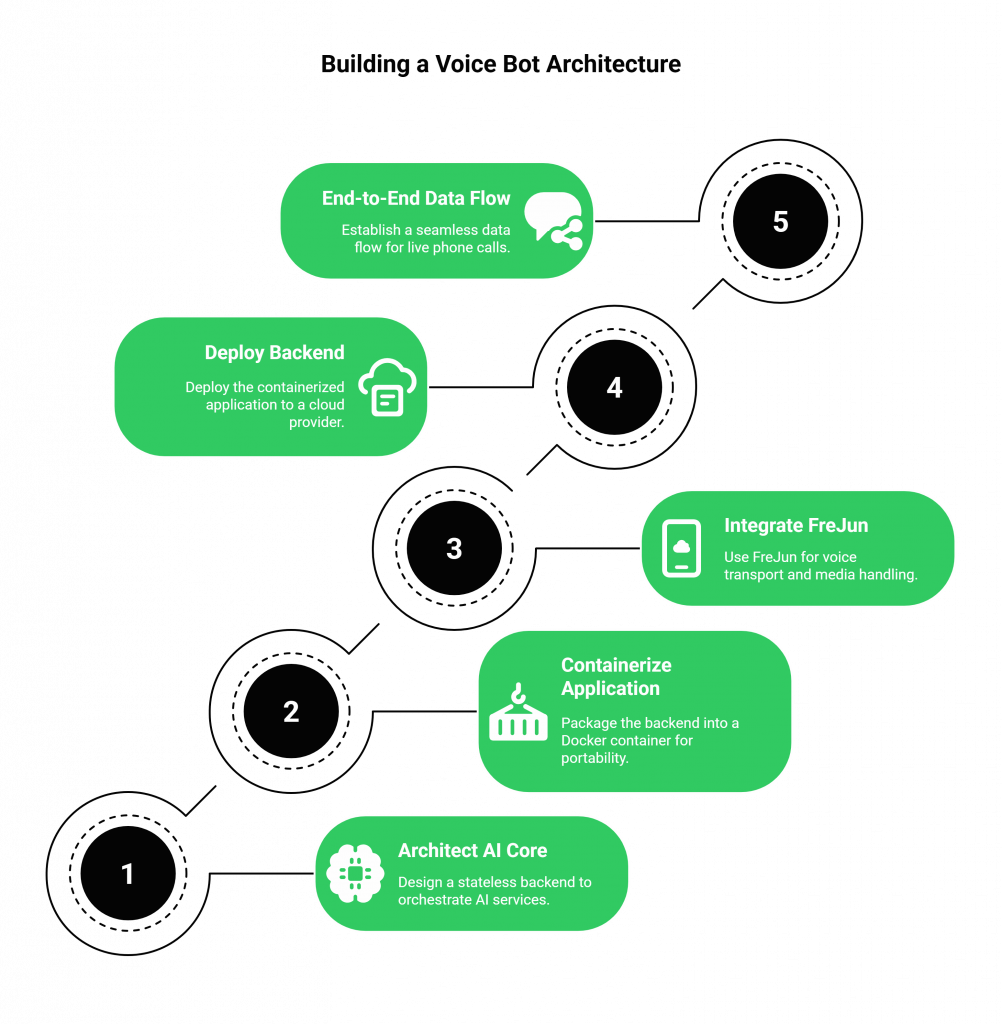
Step 1: Architect a Stateless AI Core
First, build the “brain” of your voice bot. Using your preferred backend framework (like FastAPI in Python or Express.js in Node.js), write the code that orchestrates the API calls to your chosen STT, LLM, and TTS services. A critical best practice is to design this application to be stateless, managing all conversational context in an external, persistent data store like Redis or DynamoDB.
Step 2: Containerize Your Application
Package your stateless backend service into a Docker container. This makes your application portable, simplifies dependency management, and makes it easy to deploy and scale across any cloud environment using tools like Amazon ECS or a Kubernetes cluster.
Step 3: Integrate FreJun for the Voice Transport Layer
This step replaces the need to build your own media server stack.
- Sign up for FreJun and get your API credentials.
- Provision a phone number through our dashboard.
- Use our server-side SDK in your backend to create an endpoint that can receive a bi-directional audio stream from our platform via a WebSocket.
Step 4: Deploy Your Backend and Connect the Pieces
Deploy your containerized application to a cloud provider like AWS or Google Cloud. Configure your FreJun number’s webhook to point to the public URL of this deployed service. Now, your architecture is complete.
Step 5: The End-to-End Data Flow
With this setup, the workflow for a live phone call is simple and elegant:
- A call comes into your FreJun number.
- FreJun establishes a WebSocket connection and streams the live audio to one of your running container instances.
- Your backend receives the audio and streams it to your STT API.
- The transcribed text is passed to your LLM API.
- The AI’s text response is sent to your TTS API.
- Your backend streams the synthesized audio response back to FreJun, which plays it to the caller.
This is the complete Voice Bot Example that most tutorials leave out.
Best Practices for a Flawless Real-Time Streaming Experience
- Minimize Buffering: For both incoming and outgoing audio, use small chunk sizes to keep the conversation as close to real-time as possible.
- Support Barge-In: A key feature of natural conversation is the ability to interrupt. FreJun’s bi-directional stream allows your backend to detect incoming user speech even while playing a response, so you can design logic to handle these interruptions gracefully.
- Implement Turn Detection: Use Voice Activity Detection (VAD) to start and stop processing based on when a user is actually speaking. This improves responsiveness and makes the conversation feel more natural.
- Handle Errors Gracefully: Design your backend to be resilient to failures from any of the external AI APIs it calls. Implement retries or a clear fallback path, such as transferring the call to a human agent.
Final Thoughts: Build the Brain, Not the Body
The power of a Real-Time Voice Bot lies in its intelligence, the quality of its conversation, the accuracy of its information, and the efficiency of its workflows. This is where your development team creates unique value. The underlying infrastructure, while essential, is a complex, undifferentiated commodity.
Attempting to build this infrastructure yourself is a strategic misstep. It drains resources, delays your roadmap, and forces your team to become experts in a field that is not core to your business.
The smart path to deployment is to leverage a specialized platform that has already solved the problem of voice at scale. By partnering with FreJun, you can focus your energy on what you do best: building a brilliant AI brain. Let us handle the complexities of giving it a body that can answer the call.
Further Reading – Voice Chatbot Online: How to Stream Real-Time Audio
Frequently Asked Questions (FAQ)
No. FreJun is a model-agnostic voice infrastructure platform. We provide the essential API that connects your backend to the phone network, giving you the freedom to choose and integrate any AI engines you prefer.
Asynchronous frameworks like FastAPI (Python) and Express.js (Node.js) are particularly well-suited for the real-time, I/O-bound nature of a streaming voice application because they can efficiently handle many concurrent WebSocket connections.
Your backend uses a unique session ID, provided by FreJun for each call, to store and retrieve the entire conversation history from an external database or cache (like Redis). This allows any of your server instances to handle any turn of a conversation with full context.
Yes. FreJun’s API provides full, programmatic control over the call lifecycle, including initiating outbound calls. This allows you to deploy your voice bot for proactive use cases like automated appointment reminders or lead qualification campaigns.
This architecture is highly scalable. FreJun’s infrastructure is built to handle massive call concurrency. By designing your backend to be stateless, you can use standard cloud auto-scaling to add or remove server instances based on traffic, ensuring your service is both resilient and cost-effective.