
For backend developers, the world of APIs is a familiar and powerful playground. You can orchestrate complex workflows, connect disparate systems, and manage data with precision and skill. Now, a new challenge and opportunity has emerged: building a Conversational AI Voice Bot.
Table of contents
- What is a Conversational AI Voice Bot? An Architectural View
- The Hidden Hurdle: Backend APIs Don’t Natively Speak “Telephony”
- FreJun: The Voice Infrastructure Layer for Your Backend
- How to Build a Telephony-Ready Voice Bot with Backend APIs
- Best Practices for Your Backend Voice Architecture
- Final Thoughts: Focus on Your APIs, Not the Phone Lines
- Frequently Asked Questions (FAQ)
The core components, Speech-to-Text (STT), Large Language Models (LLMs), and Text-to-Speech (TTS) are all accessible via powerful backend APIs from providers like Google, OpenAI, and ElevenLabs. It seems, at first glance, like a straightforward integration task.

You set up your backend framework in Python or Node.js, wire up the APIs, and create a sophisticated conversational agent that can listen, think, and speak. However, then you hit a fundamental, non-obvious wall: how do you connect this brilliant bot to a real phone number? Consequently, you quickly discover that the world of telephony is a minefield of archaic protocols, real-time streaming challenges, and infrastructure hurdles that your backend APIs were never designed to solve.
What is a Conversational AI Voice Bot? An Architectural View
From a backend perspective, a Conversational AI Voice Bot is a system orchestrated by a series of API calls. The architecture follows a logical pipeline designed to simulate a natural, spoken dialogue:
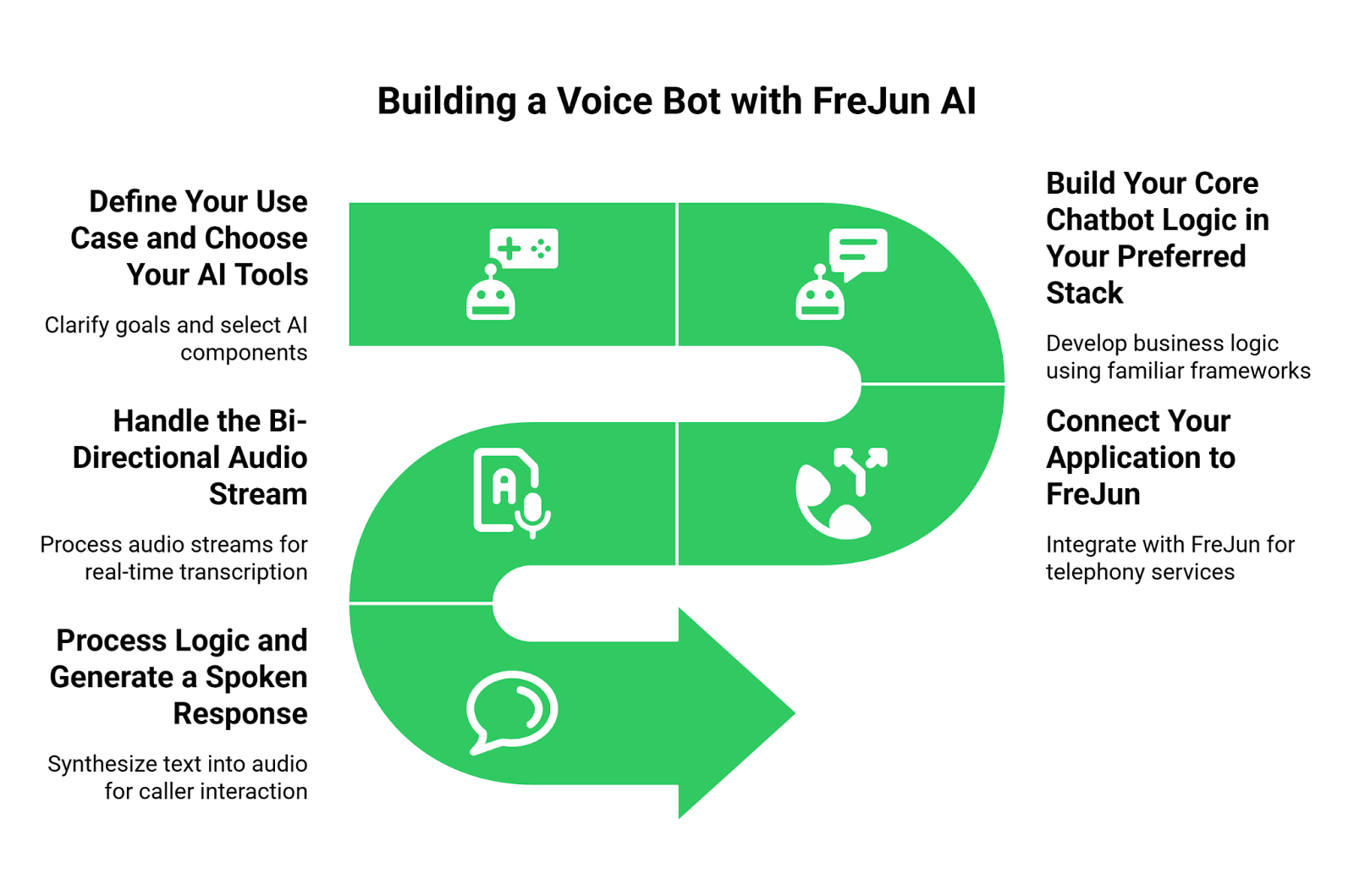
- Real-Time Audio Input: The system captures a user’s spoken words.
- Speech-to-Text (STT) API Call: The raw audio is streamed to an STT service (e.g., Google Cloud Speech API), which transcribes it into text.
- LLM/NLP API Call: The transcribed text is sent to a language model (e.g., OpenAI’s GPT-4o), which processes the user’s intent, manages conversational context, and generates a text-based response.
- Business Logic Integration: The backend can trigger other internal or external APIs for instance, to look up customer data in a database or execute a task.
- Text-to-Speech (TTS) API Call: The final text response is sent to a TTS service, which synthesizes it into lifelike audio.
- Audio Output: The synthesized audio is played back to the user.
This entire flow is managed by your backend, using persistent WebSocket or streaming HTTP connections to ensure the low-latency, bi-directional communication needed for a fluid conversation.
The Hidden Hurdle: Backend APIs Don’t Natively Speak “Telephony”
The architecture described above works perfectly if your “client” is a web browser or a mobile app that can capture microphone audio and stream it to your backend. However, the problem is, a customer calling on a phone is not a web client. Instead, they are on the Public Switched Telephone Network (PSTN), a global system with its own arcane rules.
Your backend, no matter how well-architected, has no native ability to interface with the PSTN. To enable your Conversational AI Voice Bot to answer a phone call, you would need to build an entirely new, highly specialized infrastructure layer to handle:
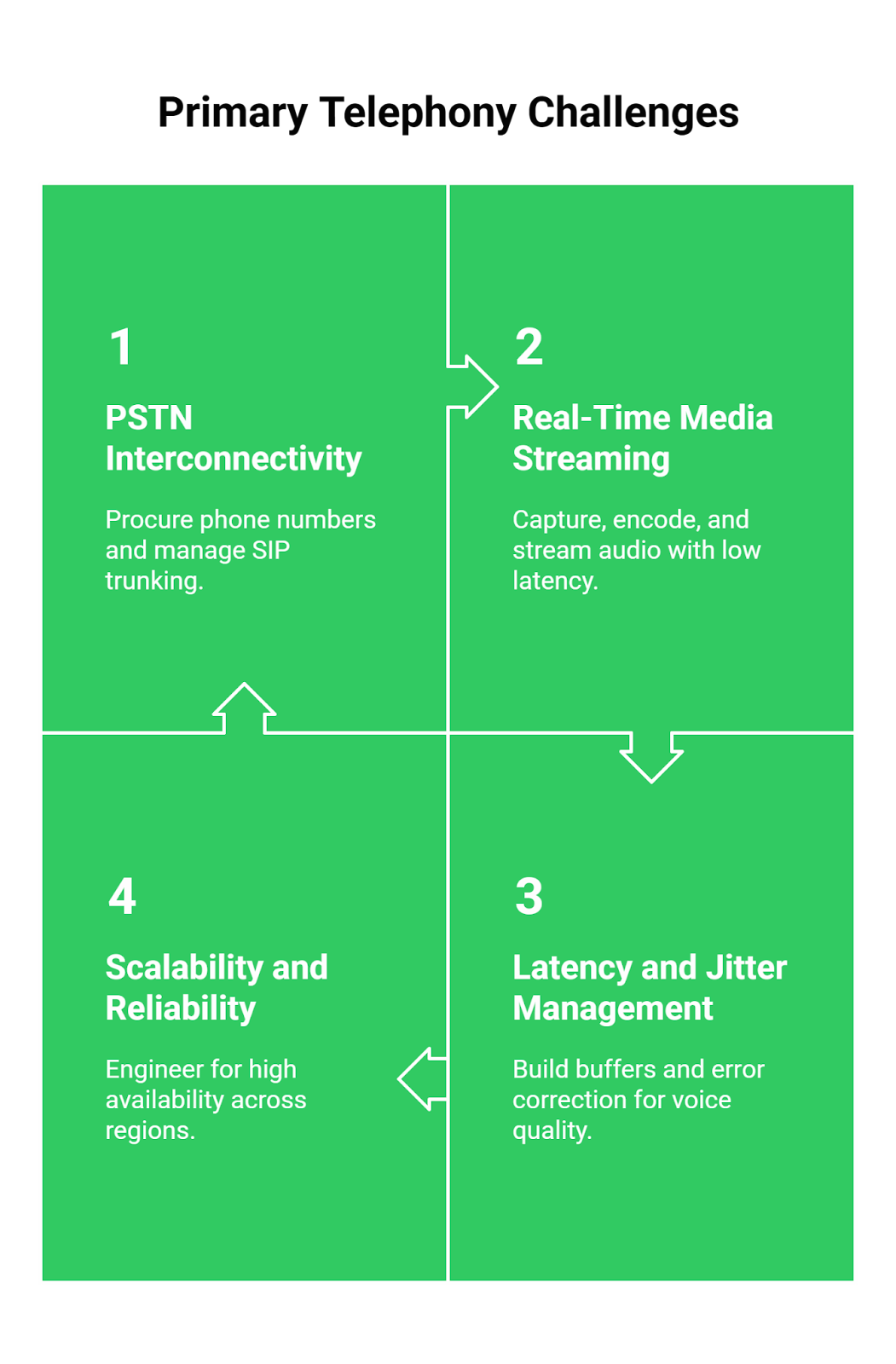
- Telephony Protocols: Managing complex Protocols to connect to telecom carriers.
- Number Provisioning: Acquiring and configuring phone numbers, a process fraught with regulatory hurdles.
- Real-Time Media Handling: Capturing raw audio from a live call (which is different from a clean web stream) and managing it with minimal latency.
- Concurrent Call Management: Building a system that can reliably handle thousands of simultaneous phone calls, each with its own state.
- Network Jitter and Packet Loss: Phone networks are less predictable than the public internet. You need to build systems to handle these imperfections to avoid garbled audio.
This is the hidden hurdle. Backend developers who set out to build a voice bot find themselves forced to become telecom engineers, a massive diversion of time, resources, and focus.
FreJun: The Voice Infrastructure Layer for Your Backend
This is precisely the problem FreJun was built to solve. We are not another AI API provider. Instead, we are the specialized voice infrastructure platform that handles the entire telephony layer, consequently acting as the crucial bridge between the phone network and your backend.
FreJun provides a simple, powerful API that makes a live phone call look just like another data stream to your application. We abstract away all the complexity of telephony, allowing you to focus on what you do best: orchestrating backend APIs to build an intelligent and effective Conversational AI Voice Bot.
Our platform is model-agnostic, giving you the freedom to mix and match the best-in-class STT, LLM, and TTS APIs for your specific needs. We simply provide the reliable, low-latency, and scalable transport layer that makes your existing backend logic work over a real phone call.
The Two Paths to Building a Voice Bot: A Head-to-Head Comparison
| Aspect | The Full-Stack DIY Approach | The FreJun + Backend API Approach |
| Infrastructure Focus | Building and maintaining voice servers, and PSTN interconnects. | Integrating a single, simple voice API into your existing backend. |
| Developer’s Role | Becomes a hybrid backend developer and telecom engineer. | Remains focused on backend logic, API orchestration, and AI quality. |
| Time to Market | Months, or even years, to build a stable, scalable system. | Days or weeks to deploy a production-ready telephony voice bot. |
| Scalability | Extremely difficult and costly to scale and ensure high availability. | Built on a globally distributed, enterprise-grade platform that scales on demand. |
| Maintenance | Continuous, complex maintenance of telephony hardware and software. | Zero telephony maintenance. FreJun handles all infrastructure and uptime. |
| Core Challenge | Solving low-level telephony and networking problems. | Optimizing the performance and intelligence of your Conversational AI Voice Bot. |
Pro Tip: Design a Stateless Backend
For maximum scalability, design your backend logic to be stateless. Furthermore, FreJun can pass a unique session identifier with each call. Therefore, your backend can use this ID to retrieve the conversation history from a distributed cache or database (like Redis or DynamoDB). Consequently, this allows you to handle a massive number of concurrent calls, as any available server instance can process the next turn in a conversation without needing local memory of the session.
How to Build a Telephony-Ready Voice Bot with Backend APIs
This guide outlines the modern architecture for building a voice bot that can handle real phone calls, using FreJun as the infrastructure layer.
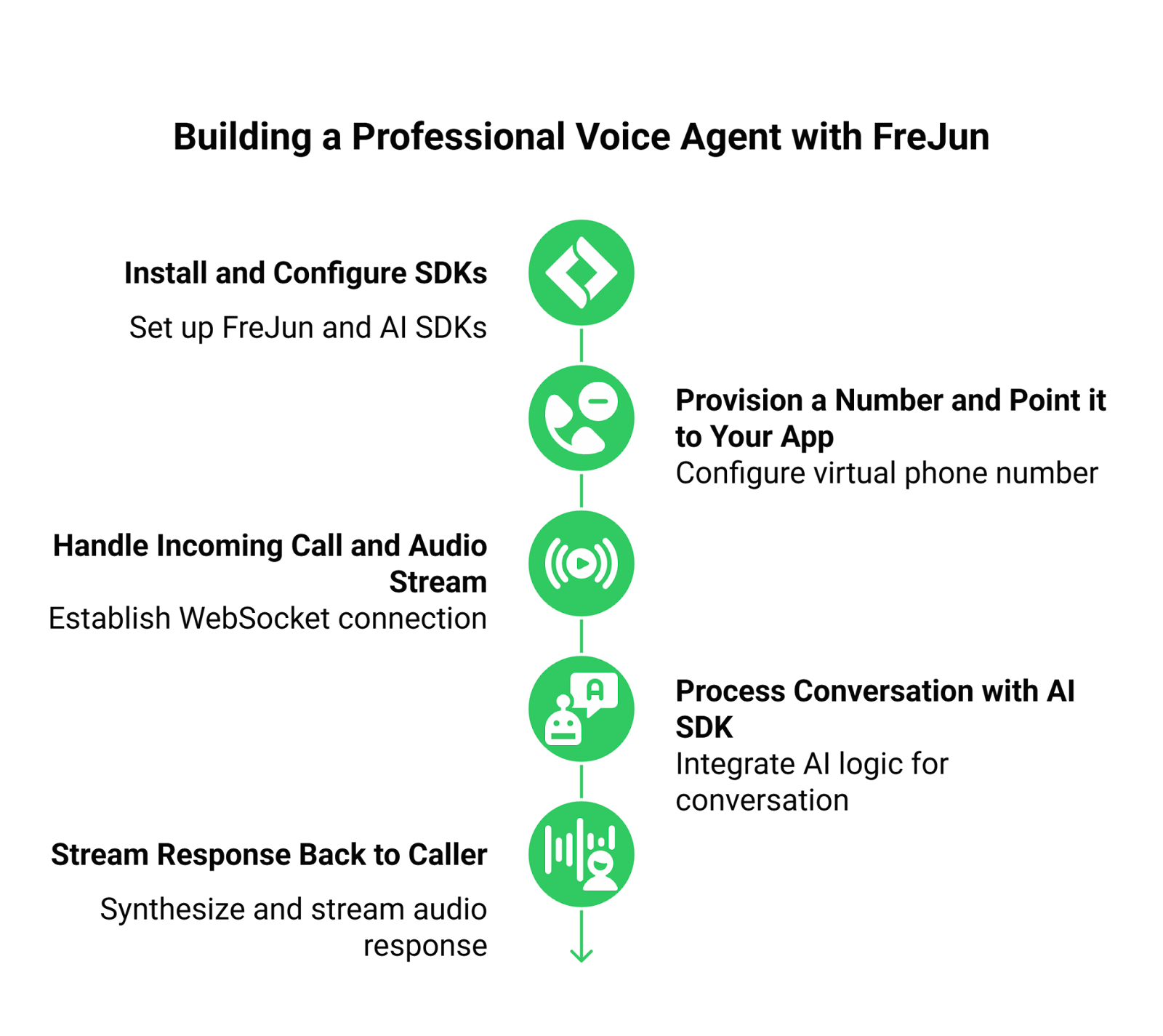
Step 1: Set Up Your Backend Framework
Choose your preferred backend language and framework, such as Python with FastAPI or Node.js with Express. This will be the central hub for orchestrating all your API calls.
Step 2: Choose Your AI API Stack
Select the APIs that best fit your needs for the core components of your Conversational AI Voice Bot:
- STT API: Google Cloud Speech, AssemblyAI, Deepgram
- LLM/NLP API: OpenAI, Anthropic, Google Gemini
- TTS API: ElevenLabs, Amazon Polly, OpenAI
Step 3: Integrate the FreJun API for Telephony
Instead of building a telephony stack, you integrate FreJun. Provision a phone number through our dashboard and configure its webhook to point to an endpoint on your backend. Our API will handle all call control and audio streaming.
Step 4: Create the Inbound Audio Processing Flow
When a customer calls your FreJun number, our platform establishes a WebSocket connection to your backend and begins streaming the caller’s audio. Your backend code will:
- Receive the raw audio stream from FreJun.
- Pipe this stream directly to your chosen STT provider’s API.
- Receive the real-time text transcription.
Step 5: Orchestrate the AI Response
Once you have the text, your core backend logic takes over:
- Send the text to your LLM API to generate an intelligent response.
- Optionally, make calls to other business logic APIs (e.g., check an order status).
- Send the final text response to your TTS API to be synthesized into audio.
Step 6: Stream the Audio Response Back to the Caller
As your TTS API returns the synthesized audio, you stream it directly back to the FreJun API. Our platform plays it to the caller over the phone with ultra-low latency, creating a seamless conversational experience.
Key Takeaway
Building a modern Conversational AI Voice Bot is an exercise in API orchestration. While developers are adept at integrating APIs for AI services, they are often blocked by the challenge of connecting their backend to the telephone network. FreJun provides the missing API a simple, powerful voice infrastructure layer that abstracts away all the complexities of telephony. This allows developers to stay focused on their backend code and launch a production-grade, telephony-enabled voice bot in a fraction of the time.
Best Practices for Your Backend Voice Architecture

- Ensure Data Privacy: Voice data is highly sensitive. Use encrypted, authenticated sessions for all API calls and ensure your data handling practices comply with all relevant regulations. FreJun is built with security by design.
- Design for Failure: What happens if one of your API calls fails? Implement robust error-handling and graceful fallbacks in your backend logic. For example, if your bot can’t answer, it could offer to transfer the call to a human agent.
- Monitor Everything: Implement real-time logging and monitoring for every step of your API pipeline. This will allow you to quickly diagnose issues, track performance, and understand user behavior.
- Manage Context and Memory: Use a database or a fast in-memory cache to store conversational context for each session. This allows your bot to have more intelligent, multi-turn conversations.
Final Thoughts: Focus on Your APIs, Not the Phone Lines
The opportunity to innovate with voice is immense. The new wave of powerful AI APIs has placed the ability to build a sophisticated Conversational AI Voice Bot within reach of every backend developer. However, the path to success is not about trying to solve every problem yourself.
The smartest strategy is to focus your efforts where you add the most value: designing the conversational logic and orchestrating the backend APIs that power your bot’s intelligence. Let a specialized platform handle the low-level, high-complexity problem of voice infrastructure.
By partnering with FreJun, you are choosing to build on a foundation of enterprise-grade reliability, scalability, and security. You free your team from the distraction of telephony and empower them to build better, smarter, and more effective voice experiences, faster.
Further Reading – Remote Team Communication Using Softphones with Regional Number Support in Indonesia
Frequently Asked Questions (FAQ)
No. FreJun is a model-agnostic voice infrastructure platform. We provide the API that connects your backend to the phone network, giving you the freedom to use any STT, LLM, or TTS APIs you choose.
You can use any backend language that can handle a standard WebSocket connection or make an HTTP request. We provide developer-friendly SDKs for popular languages like Python and Node.js to make integration even faster.
Our entire platform is engineered from the ground up for low-latency media streaming. We operate a globally distributed infrastructure optimized to minimize the round-trip delay between the caller, your backend APIs, and back to the caller, ensuring a natural conversational flow.
Yes. Our API supports initiating outbound calls programmatically. This allows you to use your Conversational AI Voice Bot for proactive use cases like appointment reminders, lead qualification, or automated feedback collection.
FreJun’s infrastructure is built to handle high volumes of concurrent calls. By architecting your backend to be stateless, you can scale your application servers horizontally, and our platform will distribute the call traffic accordingly. This creates a highly scalable and resilient system.