
As a backend developer, you are an expert orchestrator. Your domain is the world of APIs, microservices, and data flows. You can seamlessly connect a dozen different services to create powerful, scalable applications. Now, you’ve been tasked with a new and exciting challenge: connecting your backend to an AI Bot Voice Engine to create a real-time conversational experience.
Table of contents
- What is an AI Bot Voice Engine? An Architectural Breakdown
- The Hidden Roadblock: Your Backend Can’t Answer the Phone
- FreJun: The Voice Infrastructure API for Your Backend
- Connecting to a Voice Engine: The DIY Approach vs. The FreJun API
- How to Connect Your Backend to a Telephony Voice Engine: A 5-Step Guide
- Best Practices for a Resilient Backend Connection
- Final Thoughts: Focus on Your Logic, Not the Line
- Frequently Asked Questions (FAQ)
At first, the task seems well within your wheelhouse. The core components, Speech-to-Text (STT), a Large Language Model (LLM), and Text-to-Speech (TTS), are all available via well-documented APIs. The job is to write the “backend glue” that orchestrates this pipeline. But many developers who embark on this journey quickly hit a frustrating and formidable wall. They discover that while their backend is brilliant at talking to other APIs, it has no native ability to talk to the most important voice channel of all: the telephone.
What is an AI Bot Voice Engine? An Architectural Breakdown
An AI Bot Voice Engine is a composite system, a collection of services that work together to simulate a natural, spoken conversation. It is not a single product but a pipeline of specialized technologies, typically orchestrated by a central backend application. The key components are:

- Speech-to-Text (STT): This is the “ears” of the engine. An STT service like Google Speech API or AWS Transcribe takes a raw audio stream and converts it into machine-readable text.
- AI/NLP/LLM: This is the “brain.” A language model like OpenAI’s GPT-4 analyzes the transcribed text to understand user intent, manage conversational context, and generate a relevant response.
- Text-to-Speech (TTS): This is the “mouth.” A TTS service such as one from ElevenLabs or Azure synthesizes the AI’s text response back into a lifelike audio stream.
- Backend Glue: This is the part you build. It’s the application logic that manages the flow of data between these services, handles authentication, maintains session state, and integrates with other business systems.
When these components are connected with low latency, they form a powerful engine for conversational AI.
The Hidden Roadblock: Your Backend Can’t Answer the Phone
The architecture described above works perfectly for a voice bot that lives inside a web browser or a mobile app. In those scenarios, the client-side application can capture microphone audio and stream it to your backend. The problem arises when the business needs this intelligent bot to be accessible via a standard phone number for customer support, sales, or any other enterprise use case.
This is the hidden roadblock. Your backend, no matter how well-architected, has no native way to connect to the Public Switched Telephone Network (PSTN). The global phone system is a completely different universe, with its own complex protocols and infrastructure requirements.
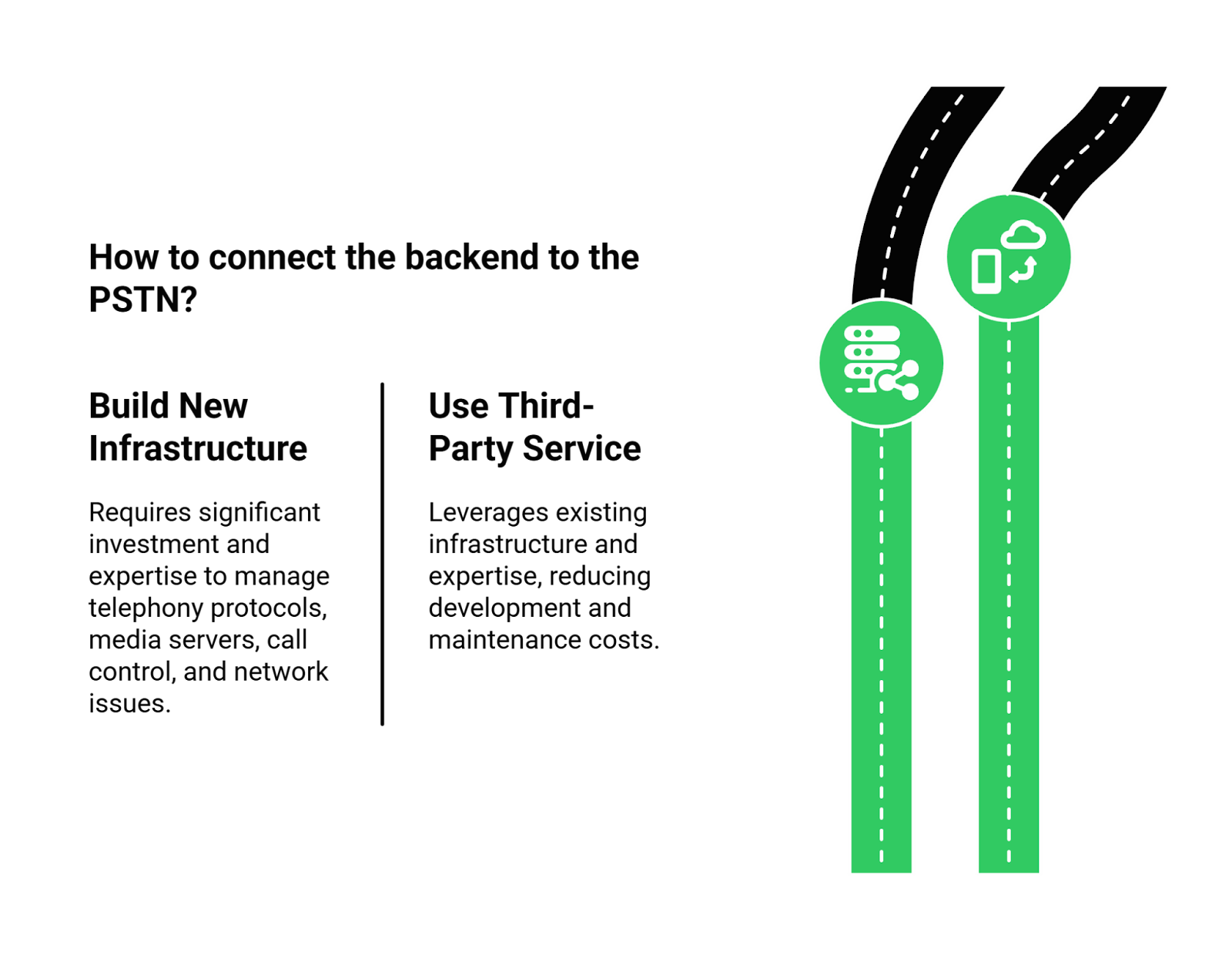
To connect your backend to a phone line, you would need to build an entirely new, highly specialized infrastructure stack from scratch to handle:
- Telephony Protocols: Managing SIP trunks and carrier relationships.
- Real-Time Media Servers: Building and maintaining dedicated servers to handle raw audio streams from thousands of concurrent calls.
- Call Control Signaling: Programmatically managing the entire lifecycle of every phone call, from ringing and answered to on-hold and terminated.
- Network Jitter and Packet Loss: Engineering solutions to mitigate the network imperfections that are common on phone lines and can ruin audio quality.
Your backend integration project has suddenly morphed into a grueling telecom engineering challenge, pulling you away from your core expertise.
FreJun: The Voice Infrastructure API for Your Backend
This is the exact problem FreJun was built to solve. We are not another AI API. We are the specialized voice infrastructure platform that provides the simple, powerful API you need to connect your backend to a telephony-based AI Bot Voice Engine
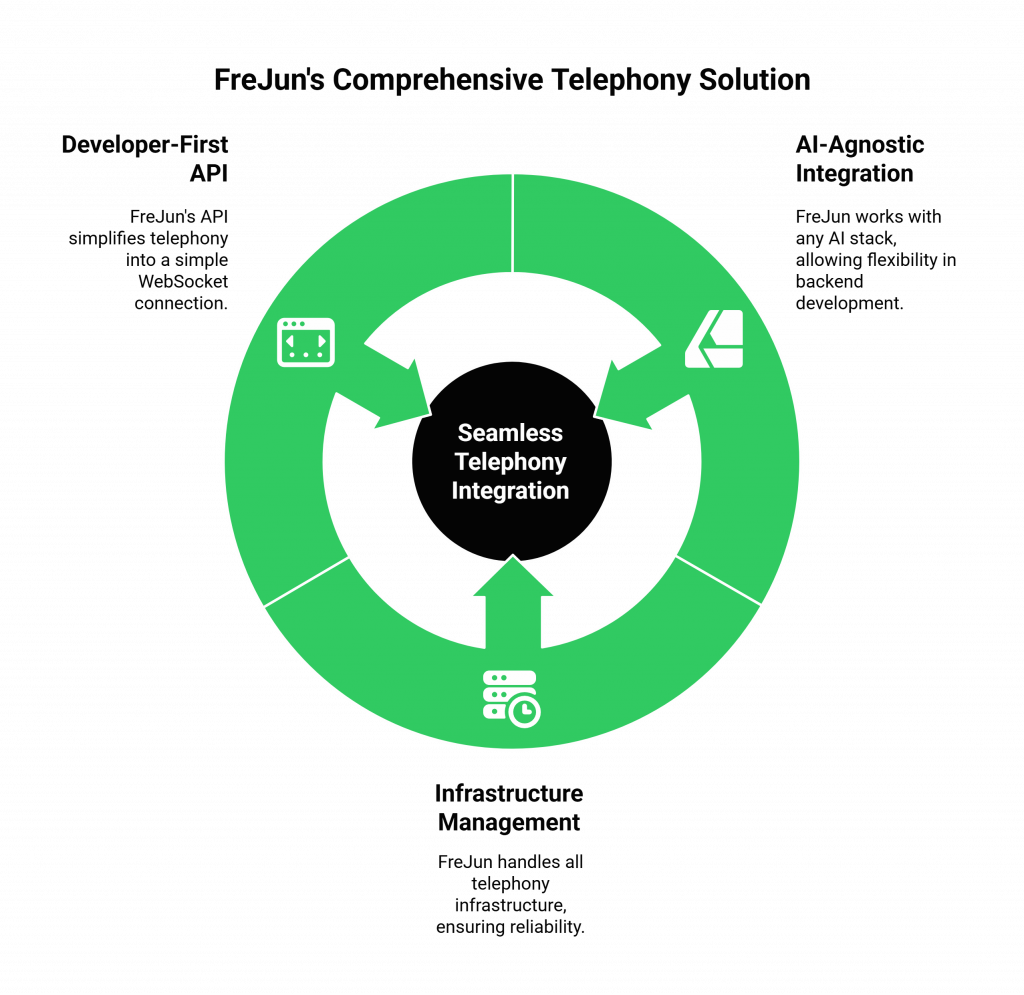
FreJun handles the entire complex, messy, and mission-critical telephony layer, so you can focus on what you do best: writing brilliant backend code.
- We are AI-Agnostic: You bring your own AI stack. FreJun integrates seamlessly with any backend built on any combination of STT, LLM, and TTS APIs.
- We Manage the Infrastructure: We handle the phone numbers, the SIP trunks, the global media servers, and the low-latency audio streaming.
- We Speak Your Language: We provide a developer-first API that makes a live phone call look like just another WebSocket connection to your application.
FreJun provides the missing link to the clean, reliable, and scalable API that connects your backend to the real world.
Pro Tip: Modularize Your Backend Architecture
For maximum flexibility and scalability, design your backend with a modular architecture. Create separate, loosely coupled services for voice transport, AI/NLP processing, and business logic. This allows you to swap out or upgrade any single component (for example, changing your LLM provider) without having to re-architect the entire system. FreJun provides the perfect modular entry point for all your telephony needs.
Connecting to a Voice Engine: The DIY Approach vs. The FreJun API
| Aspect | The DIY Telephony Approach | The FreJun API Approach |
| Infrastructure Focus | Build and maintain voice servers, SIP trunks, and PSTN interconnects. | Integrate a single voice API into your existing backend. |
| Developer’s Role | Becomes a hybrid backend developer and telecom engineer. | Remains focused on backend logic, API orchestration, and AI quality. |
| Time to Deployment | Months, or even years, to build a stable, scalable telephony solution. | Weeks. Get your telephony-enabled bot live in a fraction of the time. |
| Scalability | Extremely difficult and costly to scale for high call concurrency. | Built on an enterprise-grade platform that scales on demand. |
| Maintenance | Continuous, 24/7 maintenance of complex telecom infrastructure. | Zero telephony maintenance. FreJun guarantees uptime and reliability. |
| Core Challenge of the Connection | Solving low-level telephony and networking problems. | Optimizing the performance and intelligence of your AI Bot Voice Engine. |
How to Connect Your Backend to a Telephony Voice Engine: A 5-Step Guide
This guide outlines the modern, scalable process for connecting your backend to a voice engine that can handle real phone calls.

Step 1: Architect Your Backend for Orchestration
First, build your core backend application. Using your preferred framework (like FastAPI, Express.js, or AWS Lambda), write the code that will orchestrate the API calls to your chosen STT, LLM, and TTS services. Design this application to be stateless, managing all conversational context in an external, persistent data store like Redis or DynamoDB.
Step 2: Choose Your AI API Stack
You have complete freedom to choose the best-in-class APIs for each part of your AI Bot Voice Engine. FreJun is model-agnostic and will work with any provider.
- STT APIs: Google Speech-to-Text, AWS Transcribe, OpenAI Whisper
- LLM/NLP APIs: OpenAI GPT-4o, Azure OpenAI, Anthropic Claude
- TTS APIs: ElevenLabs, Amazon Polly, Google TTS
Step 3: Connect to FreJun’s Voice Infrastructure API
This is the step that makes your bot accessible over the phone.
- Sign up for FreJun and instantly provision a virtual phone number.
- Use FreJun’s server-side SDK in your backend code to handle incoming WebSocket connections from our platform.
- In the FreJun dashboard, configure your new number’s webhook to point to the public URL of your deployed backend service.
Step 4: Orchestrate the Real-Time Data Flow
When a customer dials your FreJun number, your backend will spring into action.
- FreJun establishes a WebSocket connection and streams the live audio to your backend.
- Your code pipes this audio stream to your STT API and receives a real-time transcription.
- The transcribed text is passed to your LLM API to generate an intelligent response.
- The AI’s text response is sent to your TTS API to be synthesized into audio.
- Your backend streams the synthesized audio back to the FreJun API, which plays it to the caller.
Step 5: Deploy and Scale Your Backend
Package your backend application in a Docker container and deploy it to a scalable cloud platform like Amazon ECS or Google Cloud Run. This allows you to automatically scale the number of server instances based on call volume, ensuring your service is both resilient and cost-effective.
Key Takeaway
Connecting your backend to an AI Bot Voice Engine for telephony is a two-part challenge. The first part, orchestrating the AI APIs, is a familiar task for any skilled backend developer. The second, much harder part is building the voice infrastructure to connect that backend to the phone network. FreJun provides a simple, powerful API that completely solves this second problem, allowing you to focus on your core competency while still delivering an enterprise-grade, scalable voice solution.
Best Practices for a Resilient Backend Connection

- Optimize for Latency: A natural conversation requires speed. Use persistent, event-driven connections like WebSockets, keep audio buffer sizes small, and choose AI providers that offer low-latency streaming responses.
- Implement Graceful Fallbacks: Your backend should be designed to handle failures from any of the external APIs it relies on. If your LLM API is down, your bot should be able to say so and offer to transfer the call to a human agent.
- Ensure Security and Compliance: Use encrypted connections for all API calls, manage your credentials securely using a secret manager, and ensure your data handling practices for logs and transcripts comply with regulations like GDPR.
- Use Comprehensive Monitoring: Implement robust logging and monitoring for your backend application and the performance of the AI APIs you are using. This is essential for debugging issues and optimizing your AI Bot Voice Engine in production.
Final Thoughts: Focus on Your Logic, Not the Line
The power of modern backend development is the ability to create incredible applications by composing specialized, best-in-class APIs. An AI Bot Voice Engine is a perfect example of this. But to succeed, you must choose your building blocks wisely.
While AI providers give you the “brain,” you still need a platform to provide the “body” the ability to listen and speak over the world’s most ubiquitous communication network. By attempting to build this yourself, you are choosing to solve a complex, undifferentiated problem that distracts from your primary goal.
The strategic path forward is to focus your energy on your core competency: building a brilliant backend that orchestrates the best AI services available. Let a specialized platform like FreJun handle the complexities of connecting your creation to the world.
Further Reading – Add Voice Chatbot Online to Your SaaS Product
Frequently Asked Questions (FAQ)
No. FreJun is a model-agnostic voice infrastructure platform. We provide the API that connects your backend to the phone network, giving you the freedom to choose and integrate any AI services you prefer.
You can use any backend language or framework that can handle a standard WebSocket connection. Asynchronous frameworks like FastAPI (Python), Express.js (Node.js), and their equivalents in other languages are particularly well-suited for the real-time, I/O-bound nature of this application.
Platforms like Twilio Studio offer a more structured, low-code environment for building IVR-like flows. FreJun is designed for developers who want maximum control and flexibility. We provide the raw, low-latency, bi-directional audio stream that is essential for building a truly custom, real-time AI Bot Voice Engine with modern, streaming AI models.
Yes. FreJun’s API provides full, programmatic control over the call lifecycle, including initiating outbound calls. This allows you to deploy your voice bot for proactive use cases like automated appointment reminders or lead qualification campaigns.
This architecture is highly scalable. FreJun’s infrastructure is built to handle massive call concurrency. By designing your backend to be stateless, you can use standard cloud auto-scaling to add or remove server instances based on traffic, ensuring your service is both resilient and cost-effective.