
Building real-time voice agents is no longer about stitching speech and text together. Modern voice systems expect natural turn-taking, fast responses, and stable conversations that work over real phone calls. That shift has pushed teams to move beyond basic request-response models toward bidirectional streaming architectures.
In this blog, we explain how to build streaming voice agents using Gemini Live for real-time AI reasoning and Teler for reliable voice infrastructure. We walk through the system design, streaming flow, latency considerations, and production tradeoffs.
The goal is simple: help founders, product managers, and engineering leads ship voice agents that actually work in real-world conversations.
What Are Bidirectional Streaming Voice Agents, And Why Do They Matter Now?
Bidirectional streaming voice agents are systems that can listen and respond at the same time. Unlike older voice bots that wait for the user to finish speaking before responding, these agents work continuously. Audio flows in, intelligence is applied in real time, and audio flows back out without long pauses.
Research shows extremely short reply times, under roughly 250 ms, increase perceived rapport in conversation, which helps explain why sub-second voice responses feel far more natural to callers.
Earlier voice systems worked in clear steps. First, the user spoke. Then the system processed the audio. Only after that did the system generate a response. As a result, conversations felt slow and mechanical.
Bidirectional streaming removes this wait time. Instead of processing speech in full chunks, the system works on small pieces of audio as they arrive. This allows understanding and response generation to happen in parallel.
Why this matters now becomes clear when you look at user expectations and technical progress.
Key reasons bidirectional streaming has become critical:
- People expect AI phone conversations to feel close to human timing
- Modern speech systems can produce partial results in real time
- Large language models can now stream responses instead of waiting
- Businesses want faster issue resolution without adding agents
Because of these changes, voice agents that do not support bidirectional streaming often feel outdated and frustrating.
What Core Components Are Required To Build A Modern Voice Agent?
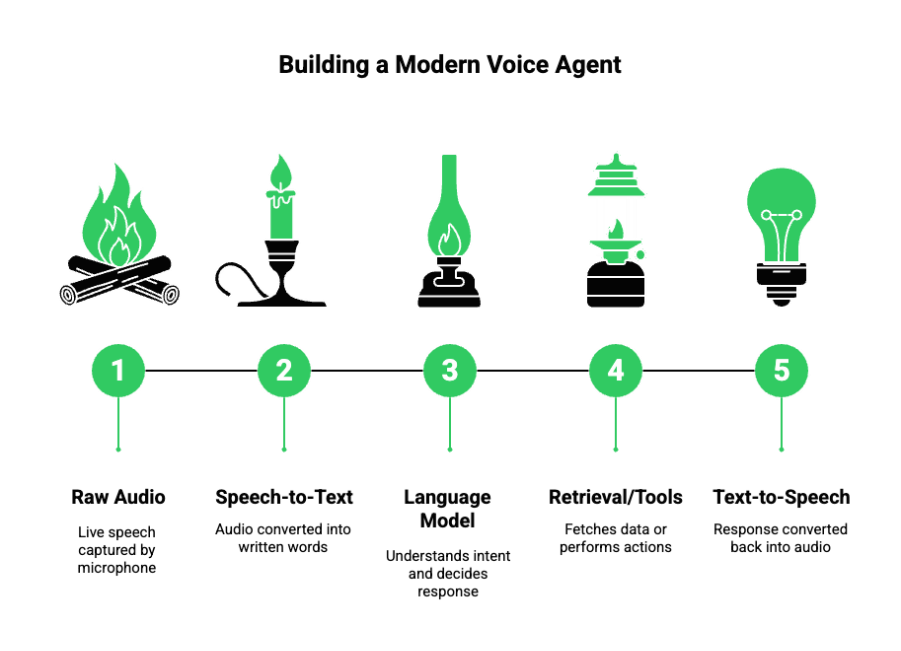
To understand how voice agents work, it is important to stop thinking in terms of a single model. A production voice agent is a system made up of multiple specialized parts working together.
At a basic level, every modern voice agent includes:
- Audio input to capture live speech
- Speech to text to convert audio into words
- A language model to understand intent and decide what to say
- Optional retrieval or tools to fetch data or perform actions
- Text to speech to convert responses back into audio
- Audio output to play the response to the caller
However, simply connecting these components is not enough. The real challenge lies in how data flows between them.
At a high level, every modern voice agent consists of:
| Component | Responsibility |
| Audio Input | Capture live human speech |
| Speech-To-Text (STT) | Convert audio to text incrementally |
| Language Model (LLM) | Understand intent and decide responses |
| Tool Calling | Trigger external actions or APIs |
| Retrieval (RAG) | Ground responses in company data |
| Text-To-Speech (TTS) | Convert responses back to audio |
| Audio Output | Play speech back to the user |
Important system characteristics include:
- All components must support streaming, not batch processing
- Partial results must be passed forward without waiting
- Context must be preserved across conversation turns
- Errors and interruptions must be handled gracefully
Because of this, a voice agent should be viewed as a streaming loop rather than a step by step pipeline. This shift in thinking sets the stage for real time conversations.
How Does Bidirectional Streaming Change Voice Agent Architecture?
Traditional voice architectures treat each step as blocking. One stage finishes before the next one begins. This design is simple, but it creates silence and delay.
Bidirectional streaming introduces a very different structure. All parts of the system operate at the same time.
From an architectural point of view, this means:
- Audio is processed in small frames instead of full recordings
- Speech to text emits partial words and phrases
- The language model receives a growing stream of input
- Text to speech begins playback before the response is complete
Because of this, the architecture becomes event driven instead of linear.
This approach enables several important behaviors:
- The agent can start responding while the user is still speaking
- Users can interrupt the agent naturally
- Long responses feel faster because speech starts early
- The system can react to changes in intent mid conversation
At the same time, this design adds complexity. Engineers must manage overlapping audio, cancel responses when needed, and decide when it is the agent’s turn to speak. Despite this, the benefits far outweigh the added effort for real world use cases.
What Is Gemini Live, And Why Is It Suited For Real Time Voice Agents?
Gemini Live is designed for scenarios where interaction happens continuously rather than in single requests. Instead of sending one prompt and waiting for a full response, developers open a live session that stays active.
Within this live session:
- Inputs can be sent as they become available
- Responses are streamed back in parts
- Function or tool calls can happen mid-response
- Conversation context remains available across turns
This design aligns very well with voice systems, where timing and continuity matter more than perfect sentences.
Google’s guidance recommends long-lived WebSocket or WebRTC sessions and client SDKs (Firebase AI Logic) to keep latency low and context persistent during voice sessions.
For voice agents, Gemini Live offers several advantages:
- Responses can begin as soon as the model has enough information
- The model can react to partial user input
- Long answers do not block the conversation
- Tool calls can be made before the user finishes speaking
Because of this, Gemini Live works as a continuous reasoning engine rather than a question answer service. This makes it especially suitable for phone based AI agents.
How Do Streaming Speech To Text And Streaming LLMs Work Together?
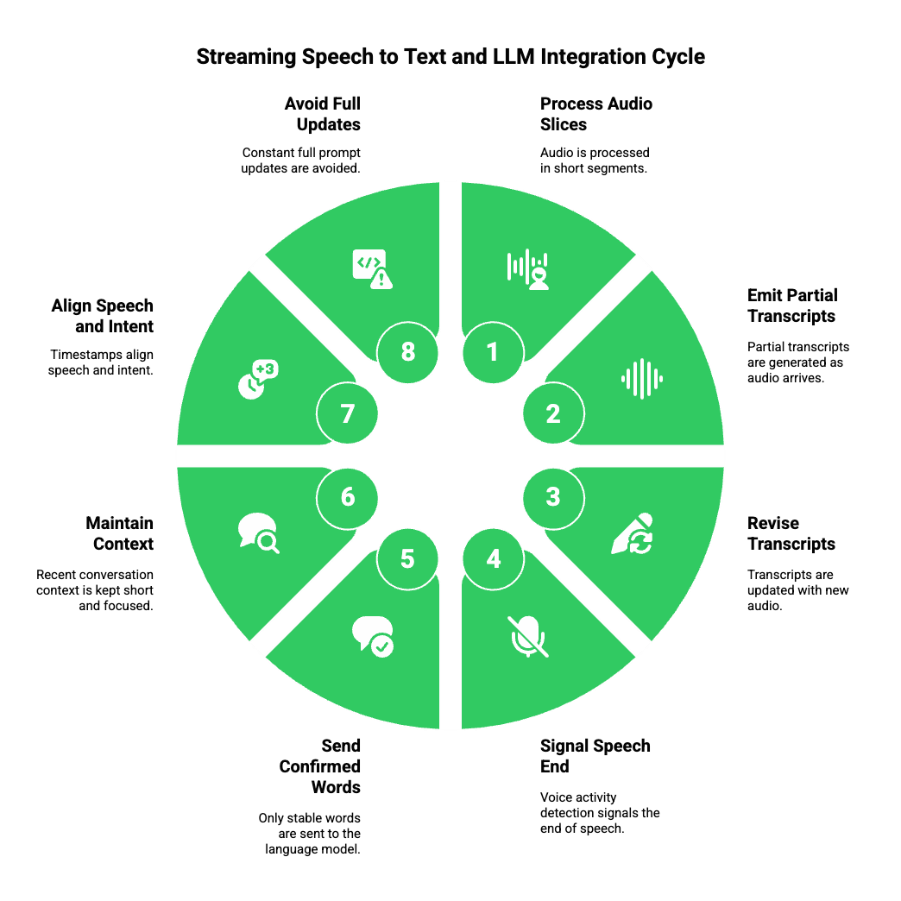
One of the most important connections in a voice agent is between speech recognition and the language model. In a streaming setup, this connection must be carefully managed.
Modern speech to text systems process audio in short slices. Instead of waiting for silence, they constantly update their best guess of what the user is saying.
These systems typically:
- Emit partial transcripts as audio arrives
- Revise earlier words when new audio clarifies meaning
- Signal when speech likely ends using voice activity detection
The language model does not wait for a full sentence. Instead, it receives stable parts of the transcript as soon as they are available.
Good integration practices include:
- Sending only confirmed words to the model
- Keeping recent conversation context short and focused
- Using timestamps to align speech and intent
- Avoiding constant full prompt updates
This approach allows the model to start reasoning early without being overwhelmed by noise.
How Does Streaming Output Turn Into Natural Speech?
Once the language model begins producing output, the conversation shifts from understanding to response delivery. The way text is converted back into speech has a major impact on how natural the agent feels.
Traditional text to speech systems need the full response before speaking. This creates noticeable delays, especially for long answers.
Traditional vs Streaming TTS
| Traditional TTS | Streaming TTS |
| Requires full text | Accepts partial input |
| Starts late | Starts early |
| No interruption | Interruptible |
| Higher perceived latency | Lower perceived latency |
Streaming text to speech works differently:
- The system accepts small pieces of text
- Audio is generated in short segments
- Playback starts as soon as the first audio is ready
- Speech continues as new audio arrives
This design leads to several benefits:
- Reduced silence after the user stops speaking
- More natural pacing for long responses
- The ability to stop speaking if the user interrupts
To achieve this, the system must manage buffering, playback timing, and cancellation carefully. When done well, the result feels far closer to a real conversation.
How Do Tool Calling And Purpose Fit Into Live Voice Conversations?
Most useful voice agents do more than talk. They take action. This might include booking meetings, fetching account data, or looking up information.
In a streaming setup, tool calling becomes part of the conversation flow rather than a separate step.
With streaming language models:
- Intent can be detected before a sentence is finished
- A tool can be triggered as soon as enough information is available
- Results can be injected back into the response in real time
For example, while a user explains a request, the system can already prepare the needed data. By the time the user finishes speaking, the response is almost ready.
This tight integration between conversation and action is one of the key advantages of streaming voice agents.
Where Does Teler Fit In A Gemini Live Voice Agent Architecture?
Up to this point, we have focused on intelligence. We discussed speech recognition, language models, streaming responses, and tool calling. However, none of that works in the real world unless audio can reliably move between humans and machines.
This is where voice infrastructure becomes critical.
Large language models like Gemini Live handle reasoning and conversation well. However, they do not manage phone calls. They do not connect to the public telephone network. They also do not handle call setup, audio codecs, or network reliability.
This gap is where FreJun Teler fits.
Teler sits between phone networks and your AI stack. It is responsible for moving live audio in and out of calls while keeping latency low and reliability high.
In a bidirectional streaming voice agent, Teler handles:
- Connecting inbound and outbound calls over PSTN, SIP, or VoIP
- Streaming real time audio to your backend systems
- Receiving synthesized audio and playing it back to callers
- Managing call state such as answer, hang up, and failures
Because of this separation, your team can focus on building intelligence, while Teler handles voice transport at scale.
How Does A Bidirectional Voice Stream Flow End To End With Teler And Gemini Live?
Now that all major components are defined, it is useful to walk through the full system in order. This helps founders and engineering leads visualize how data flows in production.
A typical bidirectional streaming voice flow works as follows.
First, an inbound or outbound phone call reaches your system through Teler. At this point, the call is live, but no intelligence is involved yet.
Next, Teler begins streaming raw audio frames from the call to your backend. This audio is sent continuously, not as a recorded file.
Then, the audio stream is forwarded to a streaming speech to text service. Partial transcripts are produced as the user speaks.
As soon as stable text appears, it is sent to Gemini Live through a live session. The model begins processing input before the user finishes speaking.
At the same time:
- Gemini streams response tokens as they are generated
- Tool calls may be triggered mid-conversation
- Response text is sent to a streaming text-to-speech engine
Finally, synthesized audio is streamed back to Teler, which plays it to the caller in real time.
This loop repeats continuously for the duration of the call.
Because each step operates in parallel, the system avoids long pauses and feels responsive.
How Does Teler Enable Low Latency And Reliability In This Flow?
Bidirectional streaming is only useful if it performs well under real conditions. Phone calls are sensitive to delay, jitter, and packet loss. Even small issues can break the experience.
Teler is designed to handle these challenges at the voice layer.
Key technical responsibilities handled by Teler include:
- Audio codec negotiation and conversion when needed
- Jitter buffering to smooth network variation
- Stable media streaming over long running calls
- Call routing across regions for lower round trip time
As a result, your AI systems receive clean, continuous audio streams instead of having to deal with telephony edge cases.
Another advantage is isolation. If an AI service slows down or restarts, Teler continues managing the call itself. This separation improves overall reliability.
How Do You Coordinate Streaming STT, LLM, And TTS With Teler?
Once Teler is in place, the next challenge is coordination. All streaming components must stay in sync to avoid talking over the user or responding too late.
A well designed system follows a few core principles.
On the input side:
- Audio is chunked into small frames before speech recognition
- Only stable transcript segments are forwarded to Gemini Live
- Voice activity detection helps decide when to pause responses
On the output side:
- LLM tokens are passed to text to speech incrementally
- Audio playback begins as soon as possible
- Responses are cancelled immediately if the user interrupts
Between these steps, Teler acts as the consistent transport layer. It does not interpret content, but it ensures audio flows smoothly in both directions.
This coordination allows the voice agent to behave predictably, even when users speak quickly, interrupt, or change intent.
How Do Tool Calling And RAG Work In A Full Voice Pipeline?
In production environments, voice agents usually need access to data and systems. This is handled through tool calling and retrieval.
With Gemini Live, tool calls often happen while the model is still generating a response. This fits well with streaming conversations.
A common pattern looks like this:
- User begins a request
- Gemini Live detects intent early
- A tool or database query is triggered
- Results are returned to the model
- The spoken response includes up to date data
When retrieval is required, the system can:
- Search a knowledge base
- Fetch only relevant documents
- Inject results into the live session
- Keep responses grounded and accurate
Because audio continues to stream during this process, the user does not experience a hard pause. Instead, the agent responds smoothly once the data is ready.
How Do You Manage Latency Across The Entire Voice System?
Latency is the most common reason voice agents feel unnatural. Therefore, it must be addressed across every layer.
Important latency sources include:
- Network distance between the caller and voice infrastructure
- Audio buffering and encoding
- Speech recognition processing time
- LLM reasoning and token generation
- Speech synthesis delay
Teler helps reduce latency at the network and transport layer. However, application level design also matters.
Best practices include:
- Keeping audio frames small
- Limiting context size passed to the LLM
- Preferring streaming models over batch APIs
- Preloading frequently used prompts and data
When these techniques are combined, total end to end latency stays within a range that feels natural to human callers.
Sign Up with FreJun Teler Now!
How Does Teler Compare To Call Centric Voice Platforms For AI?
Many existing voice platforms were designed for call automation, not AI driven streaming conversations. As a result, they often struggle when used with modern LLMs.
Call centric platforms usually:
- Treat calls as scripted flows
- Expect fixed prompts and responses
- Rely on blocking speech recognition
- Make real time interruption difficult
Teler takes a different approach. It acts as a flexible voice infrastructure layer that does not assume how intelligence works.
This allows teams to:
- Plug in any LLM, not just one vendor
- Swap STT or TTS providers without changing call logic
- Build custom orchestration instead of rigid flows
- Scale streaming conversations without redesigning telephony
For teams building AI first voice agents, this flexibility matters more than pre built call features.
What Should Founders And Engineering Leaders Consider Before Launch?
Before going live, teams should evaluate readiness across several dimensions.
From a technical perspective:
- Ensure all streaming services are production-stable
- Monitor latency at each stage of the pipeline
- Log and trace conversations safely for debugging
From a security perspective:
- Encrypt audio and transcripts in transit
- Control access to AI APIs and voice endpoints
- Handle sensitive data carefully during tool calls
From an operational perspective:
- Set clear fallback behavior if AI services fail
- Monitor active calls and error rates
- Plan cost controls for high call volumes
Addressing these areas early avoids painful surprises after launch.
What Does It Take To Launch A Bidirectional Voice Agent With Teler?
Building bidirectional streaming voice agents is no longer experimental. The technology is ready, and the building blocks are available.
By combining:
- Streaming speech recognition
- Gemini Live for real time intelligence
- Streaming text to speech
- And Teler as the voice infrastructure layer
Teams can move from prototypes to production systems that handle real customer conversations.
The key is designing the system as a streaming loop from day one. When voice, intelligence, and infrastructure are aligned, AI phone agents can finally sound responsive, useful, and reliable.
If you are building voice agents that must work on real phone lines at scale, voice infrastructure is not optional. It is the foundation.
Final Takeaway
Building bidirectional streaming voice agents requires more than choosing a strong language model. It demands a system that can handle real-time audio, manage conversational context, and respond without noticeable delay. Gemini Live provides the streaming intelligence layer, enabling token-level responses and tool execution during conversations.
Teler completes the system by handling live calls, media streaming, and voice delivery across telephony networks. Together, they allow teams to build voice agents that sound natural, respond quickly, and scale reliably. If you are planning to deploy AI agents for inbound or outbound calling, Teler helps you avoid infrastructure complexity and focus on product logic.
Schedule a demo to see how Teler enables production-ready voice agents.
FAQs –
1. What is a bidirectional streaming voice agent?
It is a voice system that listens and responds at the same time using live audio and streaming AI outputs.
2. Why is streaming important for voice conversations?
Streaming reduces wait time, improves interruption handling, and makes conversations sound natural instead of robotic.
3. Can I use any LLM with Teler?
Yes. Teler works with any LLM since it only manages real-time voice transport and call infrastructure.
4. How does Gemini Live differ from standard LLM APIs?
Gemini Live supports continuous streaming input and output instead of waiting for full request completion.
5. Do voice agents require real-time speech-to-text?
Yes. Partial transcriptions are critical for early responses and smooth conversational flow.
6. How is latency handled in production voice agents?
Latency is reduced through streaming audio, early transcripts, token-level responses, and efficient transport layers.
7. Is telephony integration necessary for voice agents?
Yes, if your agent handles real phone calls, telephony infrastructure is required for reliability and scale.
8. Can voice agents interrupt themselves when users speak?
Yes. Proper streaming pipelines allow barge-in detection and dynamic response control.
9. Are voice agents secure for enterprise use?
They can be, when built with encryption, access controls, and industry security standards.
10. How fast can a voice agent be built using Teler?
Most teams can integrate Teler and deploy a working voice agent in days, not months.
Meta Description (150 Characters)
SEO Slug (35 Characters)