
For the past several years, enterprise AI has been on a remarkable journey. We graduated from simple, rule-based chatbots to sophisticated, text-based conversational agents powered by Large Language Models. We then gave these agents a voice, allowing them to speak and listen. Each step was a significant leap forward, but they all shared a common, fundamental limitation: the AI was blind. It could understand what a customer was telling it, but it had no ability to understand what the customer was showing it.
This “sensory deprivation” has created a hard ceiling on the complexity of problems that AI can solve. The real world is not a text transcript; it’s a rich, visual, and auditory environment. For an enterprise, the most challenging and costly customer support issues are often visual in nature, a broken part, an error message on a screen, a confusing assembly step.
Now, we are at the precipice of the next great architectural shift. We are moving beyond single-sense AI and into the era of multimodal AI agents. This is about building AI agents with multimodal models that can perceive and reason about the world through multiple “senses”, sight, sound, and text, simultaneously.
For enterprises, this isn’t just an incremental upgrade; it’s a quantum leap that promises to solve a new class of previously “un-automatable” problems.
Table of contents
What is the Strategic Imperative for Multimodal AI in the Enterprise?
Adopting a multimodal strategy is not about chasing the latest trend; it’s a strategic move to unlock a new tier of efficiency, customer experience, and operational intelligence. The business case for multimodal AI agents 2025 is built on solving high-value, complex problems that are simply out of reach for a blind, voice-only AI.
How Can Multimodal AI Drastically Reduce Resolution Time?
Think about the typical technical support call. A customer spends the first ten minutes trying, and often failing, to verbally describe a complex visual problem. The agent struggles to understand, asking a series of clarifying questions before they can even begin to troubleshoot.
A multimodal agent shatters this inefficiency. The customer can simply show the problem to the AI on a video call. The AI can instantly recognize the product, read the error code, and provide the correct solution in seconds. This can have a massive impact on key metrics.
A report by McKinsey on the future of the contact center found that AI can help resolve customer issues up to 30% faster. Multimodal capabilities will only accelerate this trend.
How Does It Create a “Zero-Friction” Customer Experience?
The most intuitive interface is no interface at all. A multimodal interaction is the closest we’ve come to a truly natural, human-like way of interacting with a machine. The user doesn’t need to learn a new system or navigate a complex menu. They simply point their camera and speak their problem in their own words. This “zero-friction” experience is a powerful driver of customer satisfaction and loyalty.
How Can It Unlock New Streams of Visual Data?
Every multimodal interaction is a source of rich, contextual data that was previously invisible to your business. You can analyze thousands of images and video streams from your support calls to identify common product defects, spot trends in shipping damage, or understand which part of your product’s assembly instructions is most confusing to customers. This visual data is a goldmine of insights for your product and engineering teams.
Also Read: Create a Voice Chat Bot That Talks Like a Human
What is the Architectural Blueprint for an Enterprise-Grade Multimodal Agent?
Building AI agents with multimodal models is a complex, backend-intensive engineering challenge. It requires the orchestration of multiple, high-speed data streams and a new class of AI “brain.” Think of it as building a digital brain with both an auditory and a visual cortex.
- The “Eyes” (The Vision Model): This is the AI’s visual cortex. It’s a computer vision model that can analyze a live video stream or a static image to perform tasks like object recognition, text extraction (OCR), or defect detection.
- The “Ears” & “Mouth” (The Voice I/O): This is the AI’s auditory system. It uses Speech-to-Text (STT) to listen and Text-to-Speech (TTS) to speak, forming the conversational backbone of the interaction.
- The “Brain” (The Multimodal LLM): This is the central processing unit. The true breakthrough is the development of native multimodal models like Google’s Gemini and OpenAI’s GPT-4o. These models can accept and reason about different types of data (e.g., an image and a text prompt) in a single, unified step.
- The “Nervous System” (The Real-Time Infrastructure): This is the most critical and challenging piece of the architecture. It’s the high-speed communication network that has to transport multiple, synchronized data streams (video from the camera, audio from the microphone) from the user to your backend with ultra-lo
- w latency. A specialized infrastructure platform like FreJun AI is essential here. We provide the ultra-low-latency, real-time “auditory nerve” for your voice stream, which is a key component of a responsive multimodal experience.
Also Read: How To Implement a Real-Time Audio Chat Bot with Full API Control?
What is the Developer’s Roadmap for Building a Multimodal Agent?
Bringing these digital senses together into a single, cohesive application is a methodical process. Here is a high-level roadmap to guide you through the build.
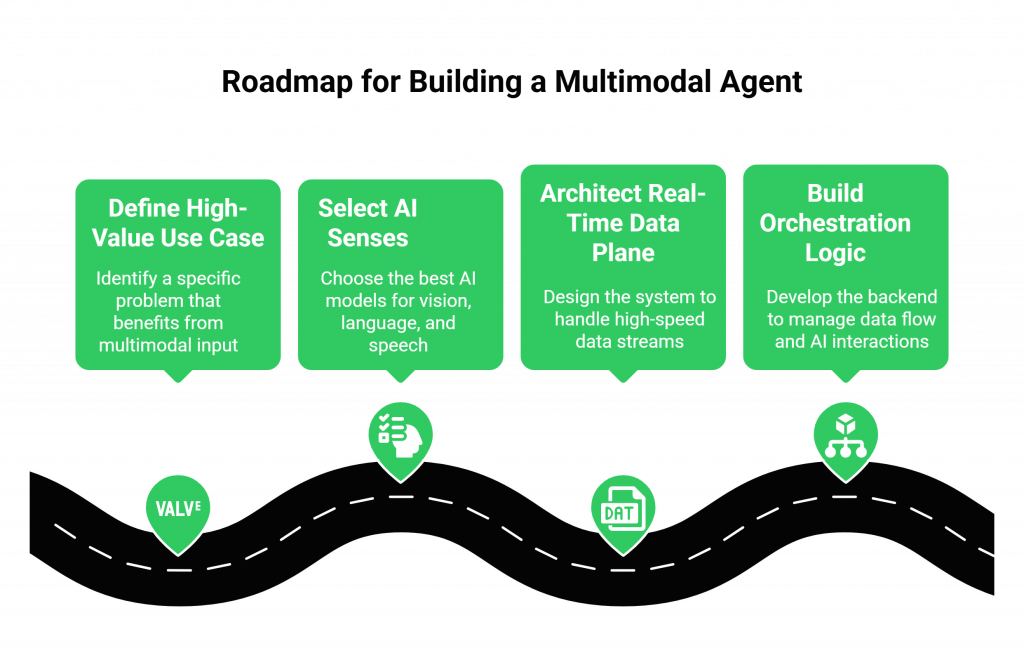
- How Do You Define the High-Value, Visual Use Case? Start with a very specific, high-value problem that is difficult to solve with words alone. Don’t try to build a general-purpose assistant. A great starting point is a task like “remote insurance claim assessment” or “interactive medical device troubleshooting.”
- How Do You Select Your “Best-of-Breed” AI Senses? This is where a model-agnostic approach is key. You’ll need to select the best computer vision model for your specific task, the most powerful multimodal LLM for the core reasoning, and the highest-quality STT and TTS models for the conversation.
- How Do You Architect the Real-Time Data Plane? This is the core engineering challenge. Your backend application needs to be able to ingest and synchronize multiple, high-speed data streams. The voice component of this is where FreJun AI shines. Our platform is specifically engineered to handle the real-time, bidirectional streaming of voice data required for a natural conversation, allowing your team to focus on the added complexity of the video stream.
- How Do You Build the Orchestration Logic? Your backend application, likely using an orchestration framework like LangChain, will act as the conductor. It will receive the audio and video streams, send the audio to your STT, and at a key moment (triggered by a user’s question), it will send a video frame along with the transcribed text to the multimodal LLM. The LLM’s text response is then sent to the TTS engine and streamed back to the user as audio via the voice infrastructure.
Ready to build the next generation of AI that can see and hear? Sign up for a FreJun AI to get started with the voice component.
Also Read: Build an AI Voice Chat Bot Without SDK Overload
What Does the Future of Multimodal AI Agents in 2025 Look Like?
The era of multimodal AI agents 2025 is not a far-off dream; these applications are moving from research labs into production deployments right now. The business world is taking notice, with the broader generative AI market projected to explode to over $1.3 trillion by 2032. Here are some of the enterprise use cases that will become mainstream.
- “See What I See” Remote Expertise: A junior field technician can be guided through a complex repair by an AI that can see their work through their phone’s camera and provide step-by-step, spoken instructions.
- Automated Visual Inspection and Verification: A logistics company can have an AI agent that looks at a photo of a delivered package to verify its condition and location, automatically resolving “package not received” disputes.
- Interactive and Immersive Onboarding: A new employee can be trained on a complex piece of proprietary software by an AI that can see their screen and hear their questions, providing a personalized, one-on-one tutoring experience at scale.
Conclusion
We are at a pivotal moment in the history of enterprise automation. The blind AI of past is evolving into a perceptive, aware partner that engages with world in rich, multisensory ways. Building AI agents with multimodal models is complex yet deeply rewarding. It means combining a powerful multimodal brain with top-tier sensory APIs hat connects everything in real time.
For enterprises, this unlocks a new class of high-value problems and enables customer experiences that are truly second to none.
Intrigued by the architectural challenges of building a multimodal AI? Schedule a demo with FreJun Teler to see how it can power your voice channel.
Also Read: How Automated Phone Calls Work: From IVR to AI-Powered Conversations
Frequently Asked Questions (FAQs)
Multimodal AI agents are a type of artificial intelligence that can process and understand information from multiple types of data, or “modalities” at the same time. This includes text, images, video, and voice, allowing for a much richer and more contextual understanding of the world.
A regular voicebot is single-modal; it can only process audio and text. A multimodal agent can, for example, see an object in a video stream while simultaneously listening to a user’s question about that object, and use both pieces of information to form its answer.
A native multimodal LLM, like OpenAI’s GPT-4o or Google’s Gemini, is a model that was designed from the ground up to accept inputs from multiple modalities in a single, unified way, rather than having separate models for each sense bolted together.
The biggest challenges are managing the real-time data streams with low latency, ensuring the synchronization of the audio and video feeds, and architecting a system that is secure, compliant, and can scale to handle enterprise-level traffic.
LangChain is a popular open-source framework that helps developers build applications with Large Language Models. It provides a standardized structure for “chaining” together calls to different LLMs, APIs, and data sources, which is essential for orchestrating complex multimodal workflows.
Security is a critical design consideration. The entire data pipeline, from the user’s device to your backend, must be encrypted. If you are building with a self-hosted open-source model, you can ensure that the sensitive visual and audio data never leaves your private network.
Yes. There are several powerful open-source multimodal models, with LLaVA (Large Language and Vision Assistant) being one of the most popular. This is a great option for businesses that require a self-hosted solution for maximum data privacy.
Yes. While some multimodal models are beginning to have native audio input/output, for the highest quality, lowest latency, and most control over the voice experience, using specialized, best-in-class STT and TTS models is still the recommended architecture for a production-grade enterprise system.