
In modern software development, flexibility is the ultimate currency. The ability to choose the best tool for the job, regardless of programming language or framework, allows teams to innovate faster and build more powerful applications. This is why the dream of creating Voice Recognition Chatbots that work with any tech stack is so compelling.
Table of Contents
- Table of Contents
- What Are Voice Recognition Chatbots? A Quick Primer
- The Hidden Roadblock: Why Your Tech Stack Can’t Natively Talk on the Phone
- FreJun: The Universal Voice Layer for Any Application
- Your Tech Stack vs. Your Tech Stack + FreJun
- How to Build a Stack-Agnostic Voice Bot with FreJun (Step-by-Step)
- Step 1: Define Your Use Case and Choose Your AI Tools
- Step 2: Build Your Core Chatbot Logic in Your Preferred Stack
- Step 3: Connect Your Application to FreJun
- Step 4: Handle the Bi-Directional Audio Stream
- Step 5: Process Logic and Generate a Spoken Response
- Best Practices for Designing a Superior Voice Experience
- Final Thoughts: Focus on Your Logic, Not Your Lines
- Frequently Asked Questions (FAQ)
Now, whether your team lives and breathes Python, Node.js, Java, or .NET, the goal is the same: to build an intelligent, voice-driven agent without being locked into a proprietary ecosystem.
The good news is that the core AI components, Automatic Speech Recognition (ASR), Natural Language Processing (NLP), and Text-to-Speech (TTS) are more accessible and stack-agnostic than ever before. But a critical piece of the puzzle is almost always overlooked. While your backend can easily make an API call to an AI service, it has no native ability to manage a live, low-latency phone call. This is the hidden roadblock where most voice projects get stuck, burning time and resources on complex telephony infrastructure instead of perfecting their chatbot.
What Are Voice Recognition Chatbots? A Quick Primer
Before we tackle the infrastructure problem, let’s define what we’re building. Voice Recognition Chatbots are sophisticated systems that enable interactive, spoken conversations through a combination of key technologies.
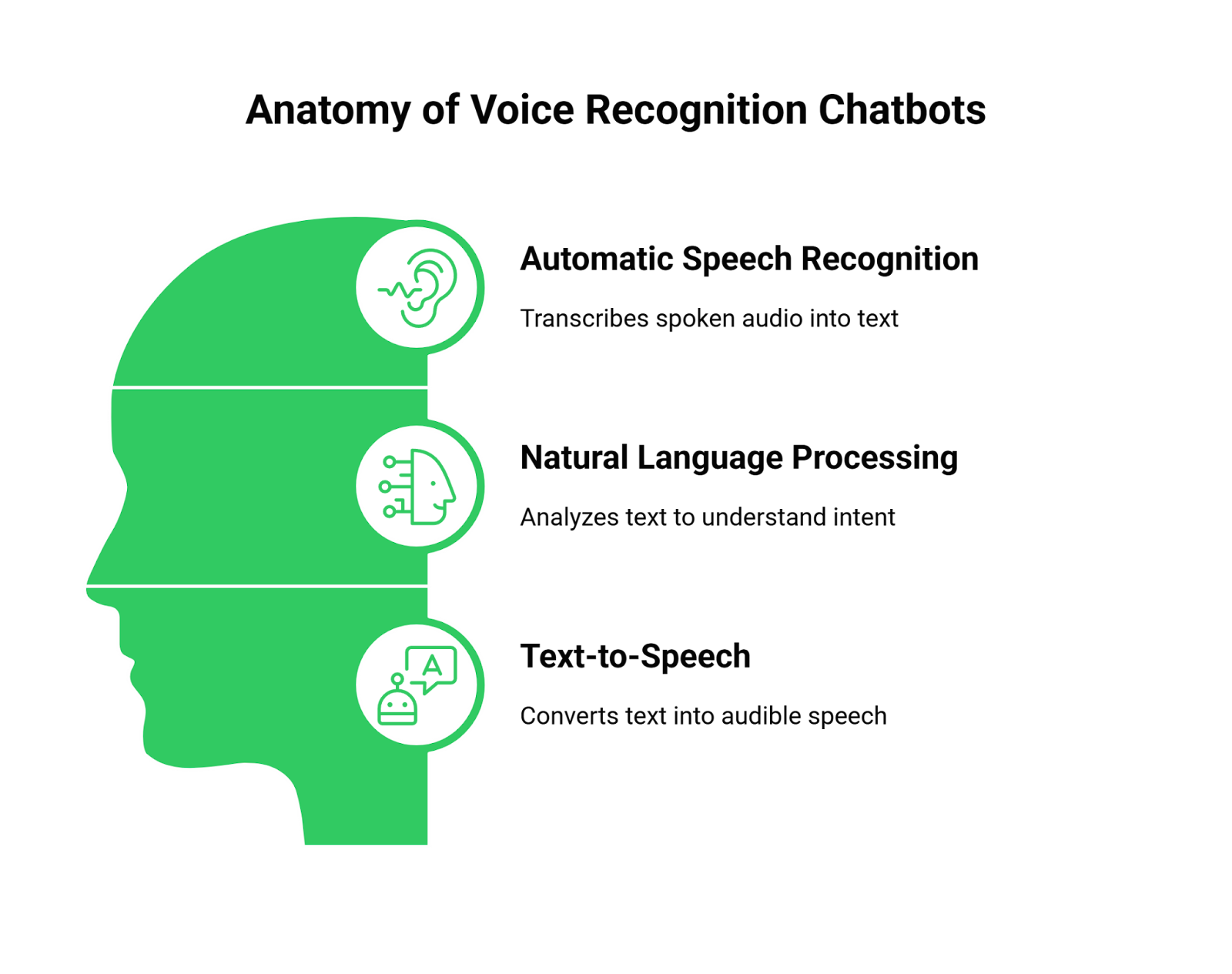
- Automatic Speech Recognition (ASR): This is the “ears” of the system. An ASR engine, like Google Speech-to-Text or AssemblyAI, captures spoken audio and transcribes it into text in real time.
- Natural Language Processing (NLP): This is the “brain.” An NLP model, often a Large Language Model (LLM) like GPT, analyzes the transcribed text to understand the user’s intent, manage conversational context, and generate a logical response.
- Text-to-Speech (TTS): This is the “voice.” A TTS service, such as one from ElevenLabs or Google, converts the NLP’s text response into natural-sounding, audible speech.
By integrating these components, developers can create hands-free, accessible, and highly engaging user experiences for customer support, sales outreach, and virtual assistants.
The Hidden Roadblock: Why Your Tech Stack Can’t Natively Talk on the Phone
Your development team has mastered your tech stack. You can build robust backends, connect to any REST or WebSocket API, and deploy services in any cloud environment. The problem is that the global telephone network (the PSTN) doesn’t speak HTTP.
To connect your brilliant chatbot logic to a live phone call, you need a specialized voice transport layer. Attempting to build this yourself, regardless of your tech stack, forces you to solve a universal set of telephony challenges:
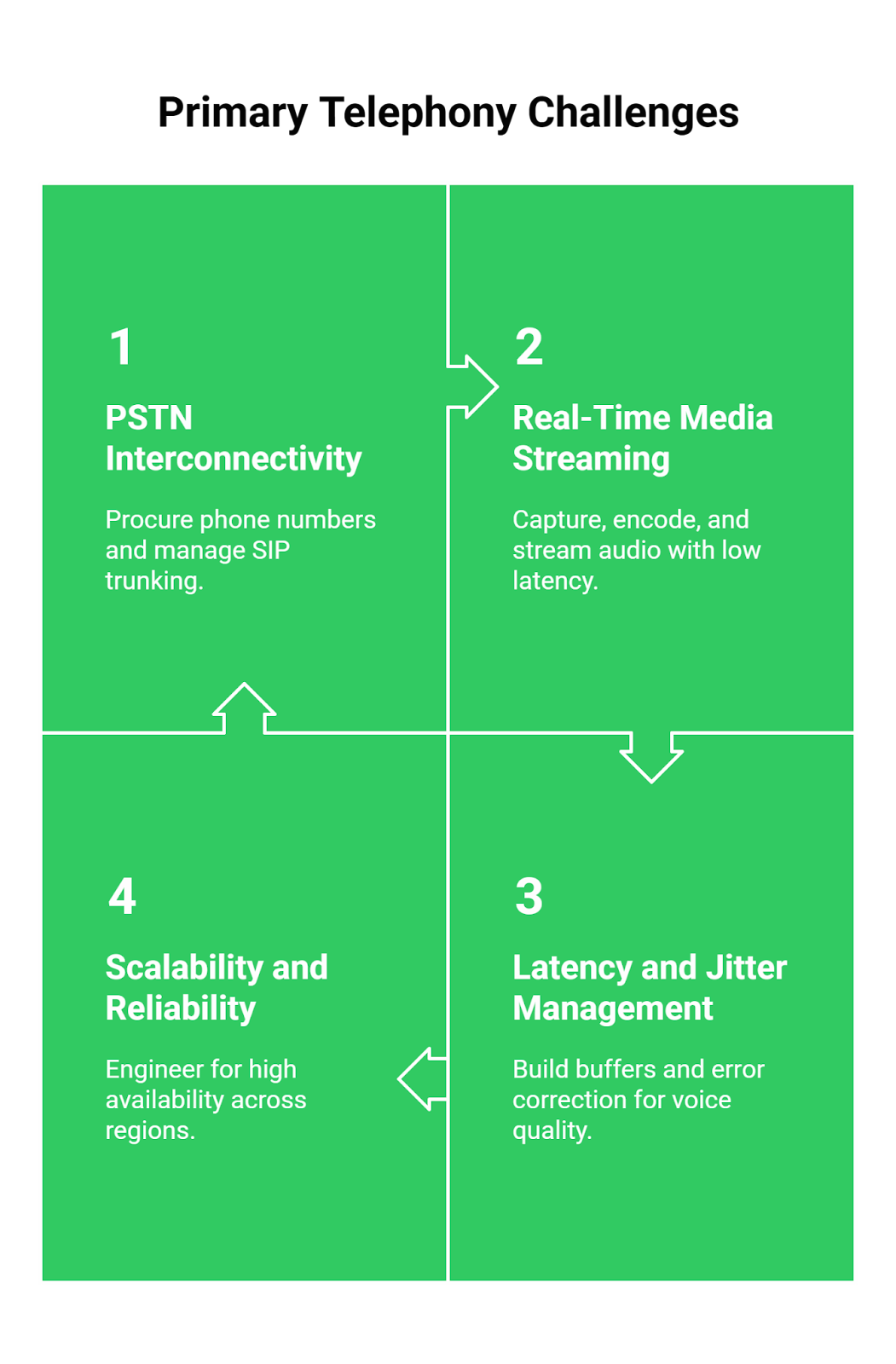
- PSTN Interconnectivity: You need to procure phone numbers and manage complex SIP (Session Initiation Protocol) trunking to connect to the traditional phone network. This is a specialized domain far removed from web development.
- Real-Time Media Streaming: You must capture, encode, and stream raw audio with sub-second latency. This requires building and maintaining persistent, bi-directional connections that can handle the unpredictability of phone networks.
- Latency and Jitter Management: Unlike a clean data request, voice is susceptible to network issues like packet loss and jitter, leading to garbled audio and awkward silences. Building buffers and error correction for this is a massive engineering effort.
- Scalability and Reliability: A solution that works for a single test call will fail under the load of hundreds or thousands of concurrent calls. Engineering for high availability across different geographic regions is a full-time job.
This is the universal truth: your tech stack is designed to process data, not to manage the messy, real-time, stateful world of voice communication. Developers who go down this path inevitably find themselves becoming telecom engineers, diverting focus from their primary goal of building powerful Voice Recognition Chatbots.
FreJun: The Universal Voice Layer for Any Application
This is where FreJun changes the game. We provide the missing piece: a robust, developer-first voice transport layer that handles all the telephony complexity, allowing you to connect your chatbot to a phone call as easily as you would connect to any other API.
FreJun is not another ASR or NLP provider. We are a model-agnostic platform built to do one thing exceptionally well: manage the complex voice infrastructure so you can focus on building your AI. Because our platform communicates via simple, well-documented APIs and SDKs, it works seamlessly with any tech stack.
- If you use Python: Our platform streams audio directly to your Flask or Django application.
- If you use Node.js: We connect to your Express server via WebSockets.
- If you use Java or .NET: Our standard API endpoints integrate cleanly into your existing architecture.
With FreJun, your application doesn’t need to know what a SIP trunk is. It only needs to be ready to receive an audio stream and send one back. We make the telephone network look like just another web service, effectively making any tech stack voice-capable.
Your Tech Stack vs. Your Tech Stack + FreJun
| Capability | Building with Your Tech Stack Alone | Building with Your Stack + FreJun |
| Telephony Integration | You are responsible for complex PSTN/SIP integration and number provisioning. | Fully managed by FreJun. Get a voice-ready number in minutes. |
| Real-Time Streaming | You must build and manage your own WebSocket or streaming media server. | Handled by FreJun’s low-latency, globally distributed infrastructure. |
| Scalability | Scaling from 10 to 10,000 concurrent calls requires massive re-architecture. | Built for enterprise scale from day one. |
| Development Focus | Split 50/50 between your chatbot logic and voice infrastructure problems. | 100% focused on building the best Voice Recognition Chatbots. |
| Speed to Market | Months or even years to build a production-ready system. | Launch a sophisticated voice agent in days or weeks. |
| Maintenance | Ongoing, complex maintenance of telecom hardware and software. | Zero infrastructure maintenance. FreJun handles all updates and uptime. |
Pro Tip: Decouple Your Components
The best architectural practice for building scalable Voice Recognition Chatbots is to keep components modular. Use FreJun for the voice transport layer, select a dedicated ASR service for transcription, and connect them to your business logic built in your preferred tech stack. This decoupled approach allows you to swap, upgrade, or change any single component, your ASR, NLP model, or even your entire backend framework, without having to rebuild the entire system.
How to Build a Stack-Agnostic Voice Bot with FreJun (Step-by-Step)
This guide outlines the practical process for creating powerful Voice Recognition Chatbots using FreJun, demonstrating how we bridge the gap between your code and a live phone call.
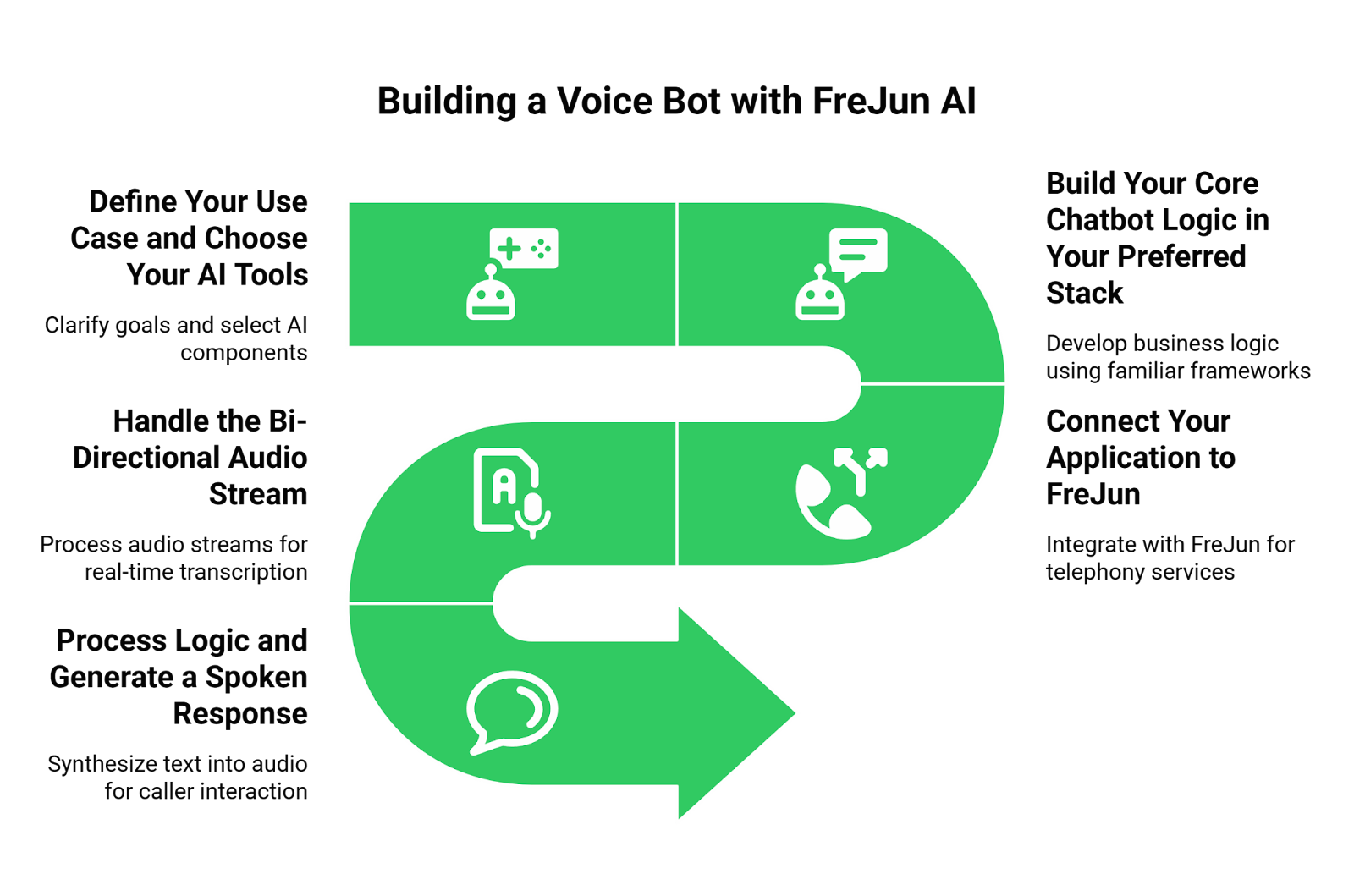
Step 1: Define Your Use Case and Choose Your AI Tools
First, clarify your goals. Are you building an inbound customer support agent or an outbound appointment reminder? Then, select your stack-agnostic AI components. Because FreJun is model-agnostic, you have complete freedom.
- ASR: Google Speech-to-Text, AssemblyAI RealtimeTranscriber
- NLP/LLM: OpenAI, Rasa, Google Dialogflow
- TTS: ElevenLabs, Amazon Polly, Google WaveNet
Step 2: Build Your Core Chatbot Logic in Your Preferred Stack
This is where you work in your comfort zone. Write your business logic using the language and framework you know best, whether it’s Python with FastAPI, Node.js with Express, or C# with ASP.NET. This application will be responsible for orchestrating the AI services.
Step 3: Connect Your Application to FreJun
Instead of wrestling with telephony protocols, you simply integrate with FreJun. In the FreJun dashboard, you provision a phone number and configure it to forward calls to your application’s endpoint. Our comprehensive SDKs make this integration trivial.
Step 4: Handle the Bi-Directional Audio Stream
When a person calls your FreJun number, our platform answers the call and immediately begins streaming the caller’s audio to your server. Your application code will:
- Receive the inbound audio stream from FreJun.
- Pipe this audio directly to your chosen ASR service’s streaming API.
- Receive the real-time text transcription from the ASR.
Step 5: Process Logic and Generate a Spoken Response
Once you have the transcribed text, your core logic takes over.
- Pass the text to your NLP or LLM to determine the correct response.
- Send the resulting text response to your TTS service to synthesize it into audio.
- Stream the synthesized audio from your TTS service back to the FreJun API.
FreJun handles the final step of playing this audio back to the caller with minimal latency, completing the conversational loop seamlessly.
Key Takeaway
True stack-agnostic development for Voice Recognition Chatbots is only possible when the problem of telephony is abstracted away. While AI services offer API-level flexibility, they do not solve the fundamental infrastructure challenge of connecting to the phone network. FreJun provides this universal voice transport layer, enabling any tech stack from Python and Node.js to Java and .NET, to power sophisticated, real-time voice conversations without having to become a telecom company.
Best Practices for Designing a Superior Voice Experience
Once FreJun has solved the infrastructure problem, you can focus on what truly matters: the quality of the conversation.
- Design for Multiple Channels: While your backend logic can be centralized, ensure the user interface is optimized for every channel, whether it’s a phone call, a web app, or a smart speaker.
- Prioritize Privacy and Security: Always encrypt audio streams and ensure your data handling practices comply with regulations. This builds trust with your users.
- Offer Fallback Options: In noisy environments or for users with speech impairments, provide alternative ways to interact, such as falling back to a text-based chat or keypad input.
- Continuously Improve Your Models: Use analytics to identify where your chatbot struggles with specific accents, dialects, or slang, and continuously retrain your models for better accuracy.
Final Thoughts: Focus on Your Logic, Not Your Lines
The future of user interaction is voice. Emerging trends like multimodal AI, on-device processing, and hyper-personalization are set to make Voice Recognition Chatbots even more powerful and intuitive. To take advantage of these advancements, your team needs to be agile, innovative, and focused.

You cannot afford to have your best engineers tied up for months dealing with the arcane complexities of voice infrastructure. The strategic choice is to build upon a platform that has already solved that problem at an enterprise scale. By partnering with FreJun, you decouple your application’s brilliant logic from the messy world of telephony. You empower your developers to use the tech stack they love to build the experiences your customers demand.
Stop worrying about dial tones and start perfecting your dialogue. Let FreJun handle the lines, so you can focus on the logic.
Further Reading – All About Voice Bots, Voice Assistants, and IVR
Frequently Asked Questions (FAQ)
Yes. FreJun’s infrastructure is designed to communicate via standard web protocols like WebSockets and well-documented REST APIs. This means any modern programming language or framework that can make an HTTP request or handle a WebSocket connection can integrate with our platform.
No, FreJun complements them. Services like Google and Azure provide the AI for transcription (ASR) and synthesis (TTS). FreJun provides the essential transport layer to get the audio from a live phone call to those services and back again in real-time.
Your application maintains full control over the dialogue state and conversational context. FreJun’s platform acts as a stable and reliable transport channel, informing your application of call events (e.g., call started, call ended), while your backend code is responsible for tracking the conversation’s history and logic.
Absolutely. FreJun provides comprehensive client-side and server-side SDKs. You can easily embed voice capabilities directly into your web and mobile applications, all powered by the same backend logic you use for your phone-based Voice Recognition Chatbots.
Our entire architecture is purpose-built for speed and clarity. We operate a globally distributed network optimized to minimize the round-trip time between the caller, your application, your AI services, and back to the caller. This engineering focus eliminates the unnatural delays that plague DIY voice solutions.